 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Iterative Reasoning for Merging in Dense Traffic
May 25, 2020


Maneuvering in dense traffic is a challenging task for autonomous vehicles because it requires reasoning about the stochastic behaviors of many other participants. In addition, the agent must achieve the maneuver within a limited time and distance. In this work, we propose a combination of reinforcement learning and game theory to learn merging behaviors. We design a training curriculum for a reinforcement learning agent using the concept of level-$k$ behavior. This approach exposes the agent to a broad variety of behaviors during training, which promotes learning policies that are robust to model discrepancies. We show that our approach learns more efficient policies than traditional training methods.
* 6pages, 5 figures
Cooperation-Aware Lane Change Maneuver in Dense Traffic based on Model Predictive Control with Recurrent Neural Network
Sep 29, 2019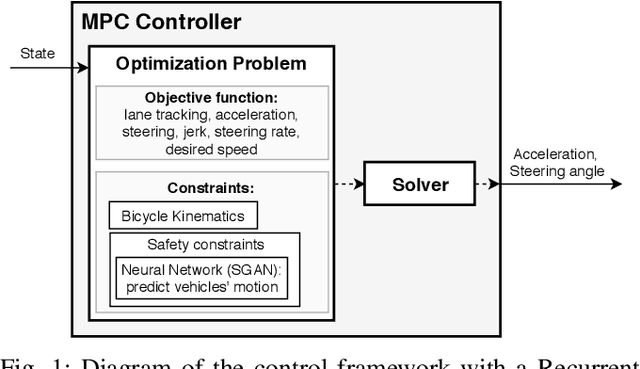
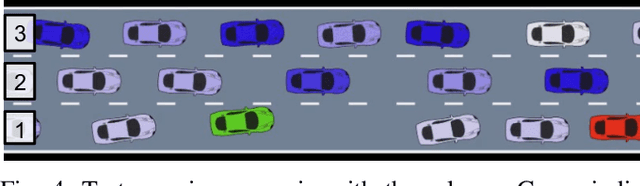
This paper presents a real-time lane change control framework of autonomous driving in dense traffic, which exploits cooperative behaviors of other drivers. This paper focuses on heavy traffic where vehicles cannot change lanes without cooperating with other drivers. In this case, classical robust controls may not apply since there is no safe area to merge to without interacting with the other drivers. That said, modeling complex and interactive human behaviors is highly non-trivial from the perspective of control engineers. We propose a mathematical control framework based on Model Predictive Control (MPC) encompassing a state-of-the-art Recurrent Neural network (RNN) architecture. In particular, RNN predicts interactive motions of other drivers in response to potential actions of the autonomous vehicle, which are then systematically evaluated in safety constraints. We also propose a real-time heuristic algorithm to find locally optimal control inputs. Finally, quantitative and qualitative analysis on simulation studies are presented to illustrate the benefits of the proposed framework.
Safe Reinforcement Learning on Autonomous Vehicles
Sep 27, 2019
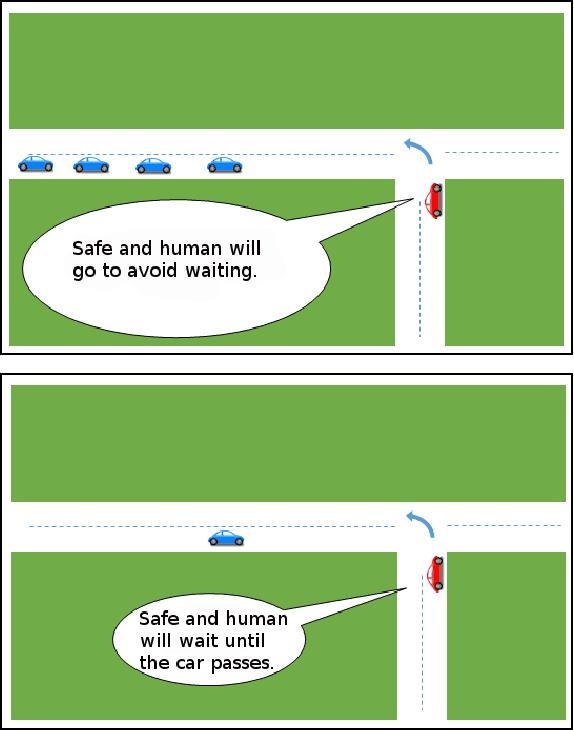
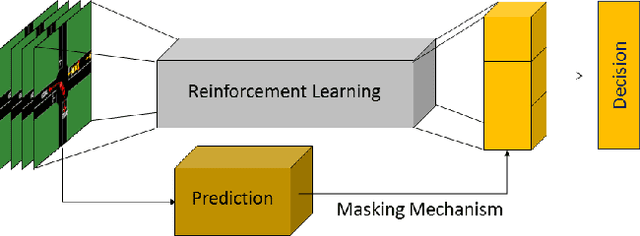
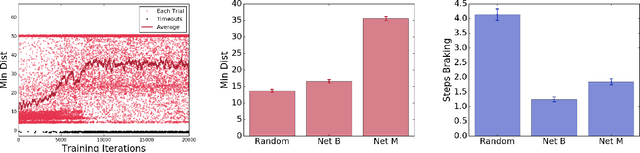
There have been numerous advances in reinforcement learning, but the typically unconstrained exploration of the learning process prevents the adoption of these methods in many safety critical applications. Recent work in safe reinforcement learning uses idealized models to achieve their guarantees, but these models do not easily accommodate the stochasticity or high-dimensionality of real world systems. We investigate how prediction provides a general and intuitive framework to constraint exploration, and show how it can be used to safely learn intersection handling behaviors on an autonomous vehicle.
Driving in Dense Traffic with Model-Free Reinforcement Learning
Sep 15, 2019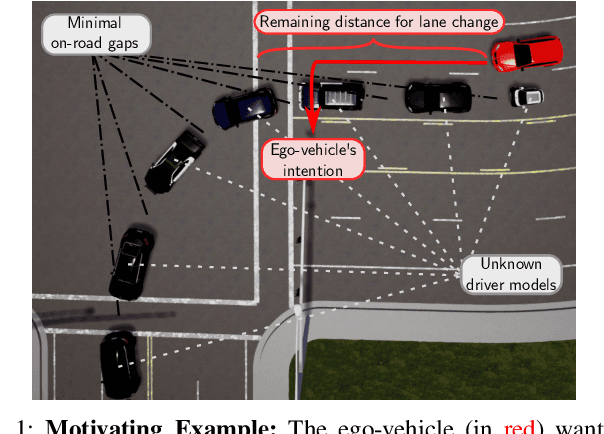
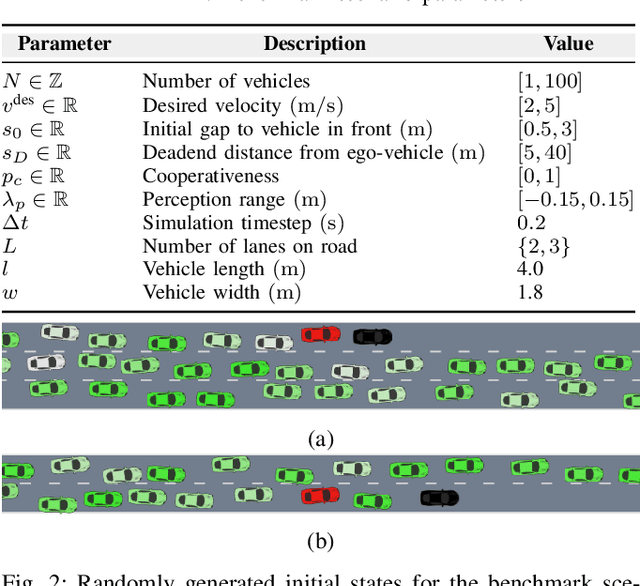
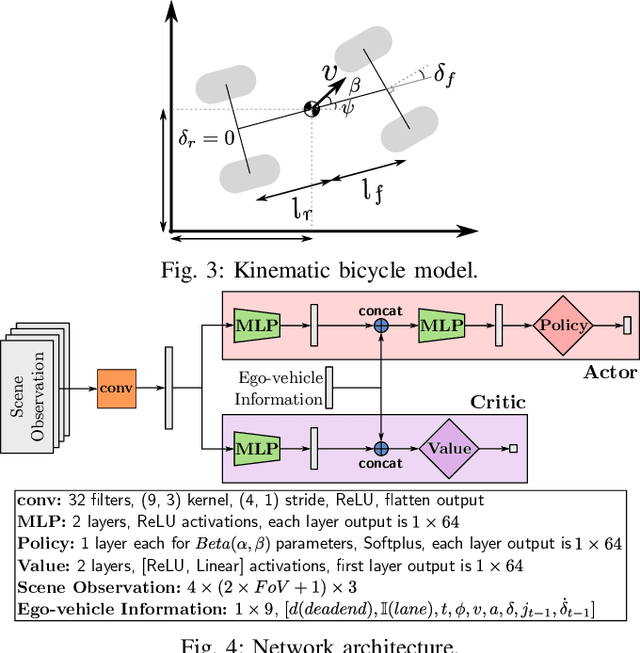
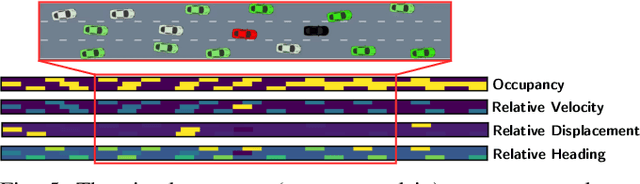
Traditional planning and control methods could fail to find a feasible trajectory for an autonomous vehicle to execute amongst dense traffic on roads. This is because the obstacle-free volume in spacetime is very small in these scenarios for the vehicle to drive through. However, that does not mean the task is infeasible since human drivers are known to be able to drive amongst dense traffic by leveraging the cooperativeness of other drivers to open a gap. The traditional methods fail to take into account the fact that the actions taken by an agent affect the behaviour of other vehicles on the road. In this work, we rely on the ability of deep reinforcement learning to implicitly model such interactions and learn a continuous control policy over the action space of an autonomous vehicle. The application we consider requires our agent to negotiate and open a gap in the road in order to successfully merge or change lanes. Our policy learns to repeatedly probe into the target road lane while trying to find a safe spot to move in to. We compare against two model-predictive control-based algorithms and show that our policy outperforms them in simulation.
Cooperation-Aware Reinforcement Learning for Merging in Dense Traffic
Jun 26, 2019
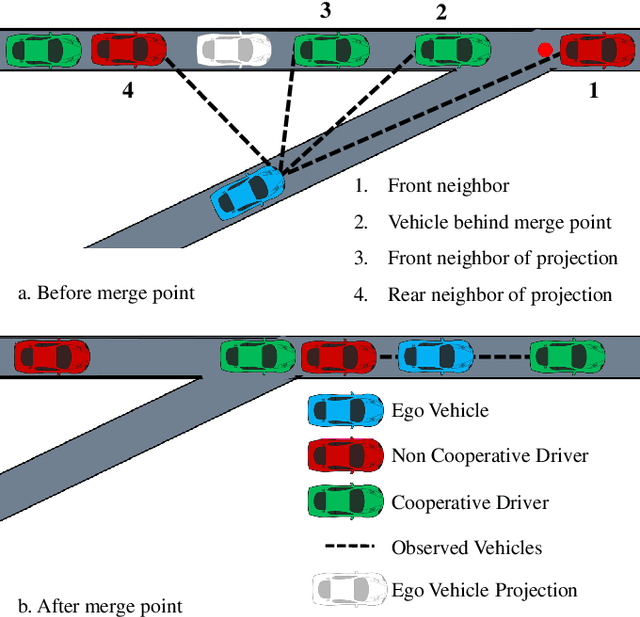


Decision making in dense traffic can be challenging for autonomous vehicles. An autonomous system only relying on predefined road priorities and considering other drivers as moving objects will cause the vehicle to freeze and fail the maneuver. Human drivers leverage the cooperation of other drivers to avoid such deadlock situations and convince others to change their behavior. Decision making algorithms must reason about the interaction with other drivers and anticipate a broad range of driver behaviors. In this work, we present a reinforcement learning approach to learn how to interact with drivers with different cooperation levels. We enhanced the performance of traditional reinforcement learning algorithms by maintaining a belief over the level of cooperation of other drivers. We show that our agent successfully learns how to navigate a dense merging scenario with less deadlocks than with online planning methods.
* 7 pages, 5 figures
Reinforcement Learning with Probabilistic Guarantees for Autonomous Driving
May 29, 2019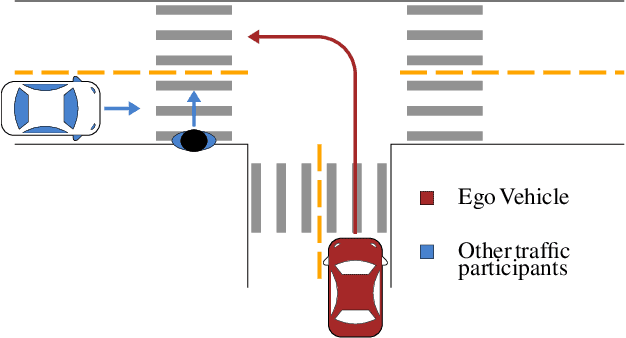
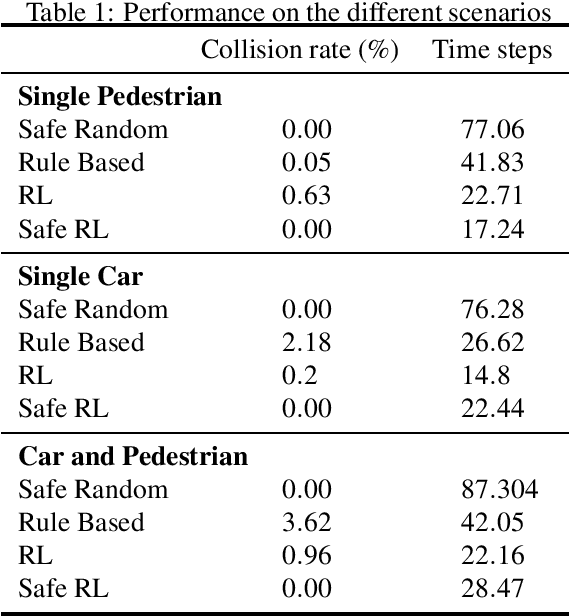
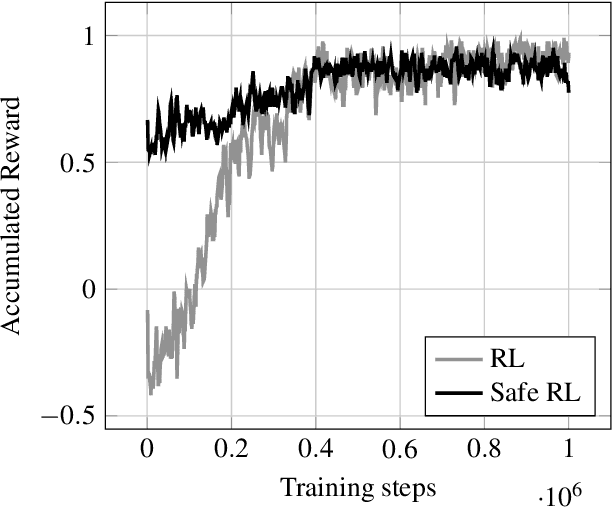
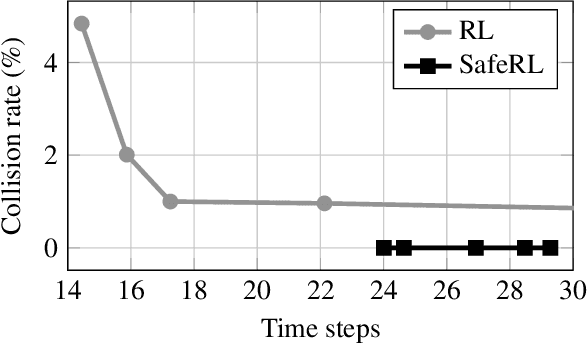
Designing reliable decision strategies for autonomous urban driving is challenging. Reinforcement learning (RL) has been used to automatically derive suitable behavior in uncertain environments, but it does not provide any guarantee on the performance of the resulting policy. We propose a generic approach to enforce probabilistic guarantees on an RL agent. An exploration strategy is derived prior to training that constrains the agent to choose among actions that satisfy a desired probabilistic specification expressed with linear temporal logic (LTL). Reducing the search space to policies satisfying the LTL formula helps training and simplifies reward design. This paper outlines a case study of an intersection scenario involving multiple traffic participants. The resulting policy outperforms a rule-based heuristic approach in terms of efficiency while exhibiting strong guarantees on safety.
Safe Reinforcement Learning with Scene Decomposition for Navigating Complex Urban Environments
Apr 25, 2019
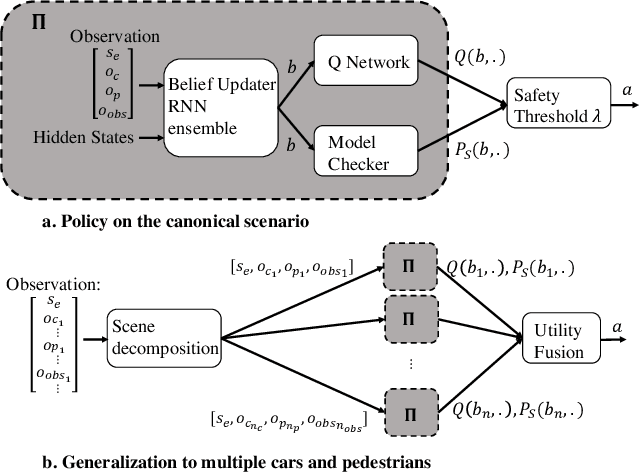


Navigating urban environments represents a complex task for automated vehicles. They must reach their goal safely and efficiently while considering a multitude of traffic participants. We propose a modular decision making algorithm to autonomously navigate intersections, addressing challenges of existing rule-based and reinforcement learning (RL) approaches. We first present a safe RL algorithm relying on a model-checker to ensure safety guarantees. To make the decision strategy robust to perception errors and occlusions, we introduce a belief update technique using a learning based approach. Finally, we use a scene decomposition approach to scale our algorithm to environments with multiple traffic participants. We empirically demonstrate that our algorithm outperforms rule-based methods and reinforcement learning techniques on a complex intersection scenario.
* 8 pages; 7 figures
Interaction-aware Decision Making with Adaptive Strategies under Merging Scenarios
Apr 12, 2019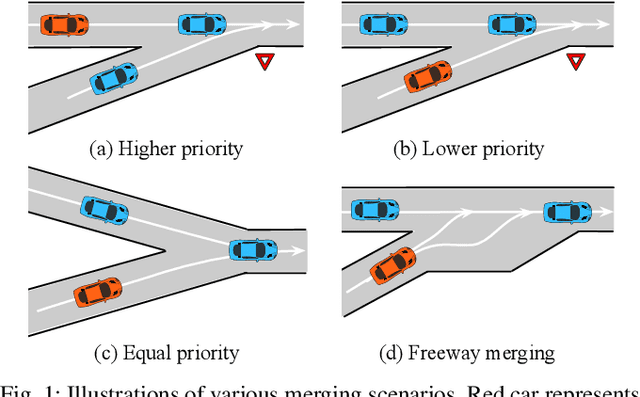
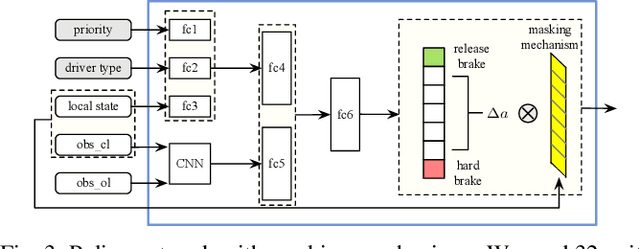

In order to drive safely and efficiently under merging scenarios, autonomous vehicles should be aware of their surroundings and make decisions by interacting with other road participants. Moreover, different strategies should be made when the autonomous vehicle is interacting with drivers having different level of cooperativeness. Whether the vehicle is on the merge-lane or main-lane will also influence the driving maneuvers since drivers will behave differently when they have the right-of-way than otherwise. Many traditional methods have been proposed to solve decision making problems under merging scenarios. However, these works either are incapable of modeling complicated interactions or require implementing hand-designed rules which cannot properly handle the uncertainties in real-world scenarios. In this paper, we proposed an interaction-aware decision making with adaptive strategies (IDAS) approach that can let the autonomous vehicle negotiate the road with other drivers by leveraging their cooperativeness under merging scenarios. A single policy is learned under the multi-agent reinforcement learning (MARL) setting via the curriculum learning strategy, which enables the agent to automatically infer other drivers' various behaviors and make decisions strategically. A masking mechanism is also proposed to prevent the agent from exploring states that violate common sense of human judgment and increase the learning efficiency. An exemplar merging scenario was used to implement and examine the proposed method.
CM3: Cooperative Multi-goal Multi-stage Multi-agent Reinforcement Learning
Sep 13, 2018
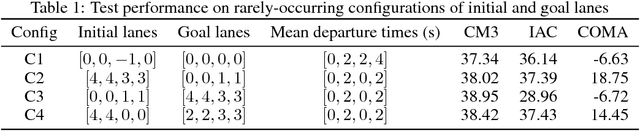

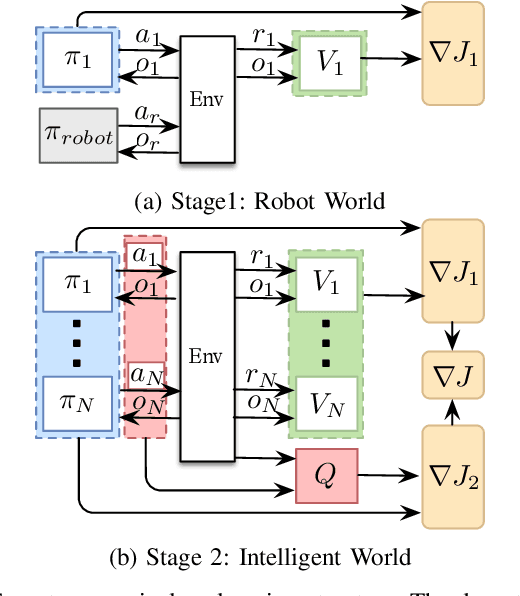
We propose CM3, a new deep reinforcement learning method for cooperative multi-agent problems where agents must coordinate for joint success in achieving different individual goals. We restructure multi-agent learning into a two-stage curriculum, consisting of a single-agent stage for learning to accomplish individual tasks, followed by a multi-agent stage for learning to cooperate in the presence of other agents. These two stages are bridged by modular augmentation of neural network policy and value functions. We further adapt the actor-critic framework to this curriculum by formulating local and global views of the policy gradient and learning via a double critic, consisting of a decentralized value function and a centralized action-value function. We evaluated CM3 on a new high-dimensional multi-agent environment with sparse rewards: negotiating lane changes among multiple autonomous vehicles in the Simulation of Urban Mobility (SUMO) traffic simulator. Detailed ablation experiments show the positive contribution of each component in CM3, and the overall synthesis converges significantly faster to higher performance policies than existing cooperative multi-agent methods.
Collaborative Planning for Mixed-Autonomy Lane Merging
Aug 07, 2018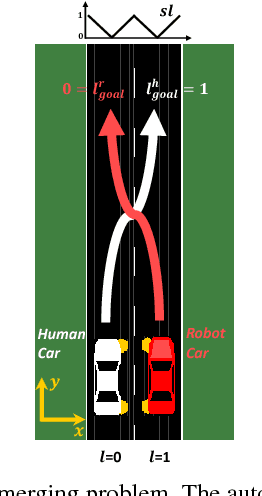

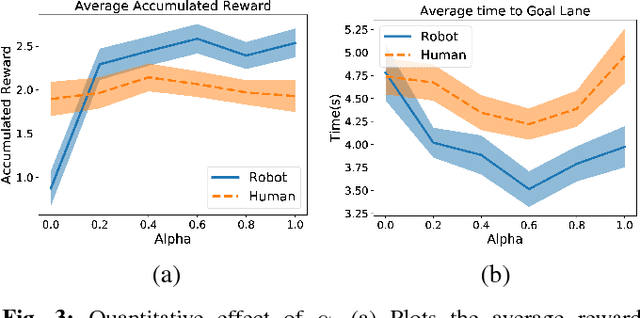
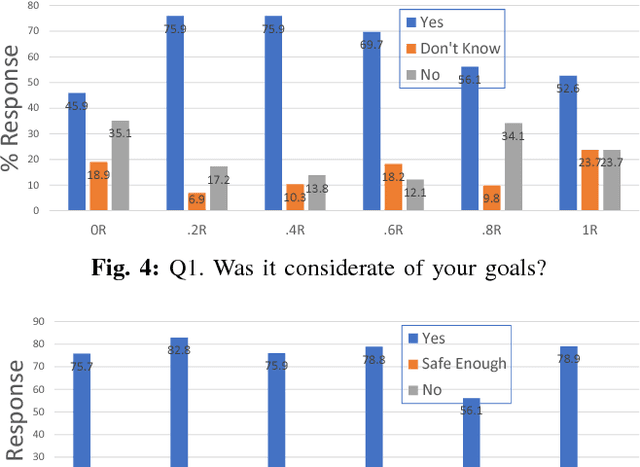
Driving is a social activity: drivers often indicate their intent to change lanes via motion cues. We consider mixed-autonomy traffic where a Human-driven Vehicle (HV) and an Autonomous Vehicle (AV) drive together. We propose a planning framework where the degree to which the AV considers the other agent's reward is controlled by a selfishness factor. We test our approach on a simulated two-lane highway where the AV and HV merge into each other's lanes. In a user study with 21 subjects and 6 different selfishness factors, we found that our planning approach was sound and that both agents had less merging times when a factor that balances the rewards for the two agents was chosen. Our results on double lane merging suggest it to be a non-zero-sum game and encourage further investigation on collaborative decision making algorithms for mixed-autonomy traffic.