 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Autonomous Navigation with Internal State Inference and Interactivity Estimation
Nov 27, 2023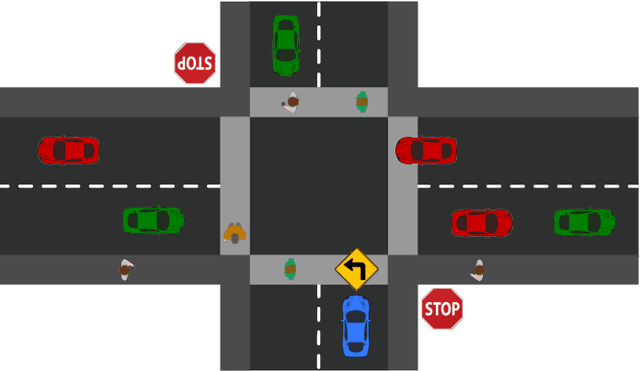
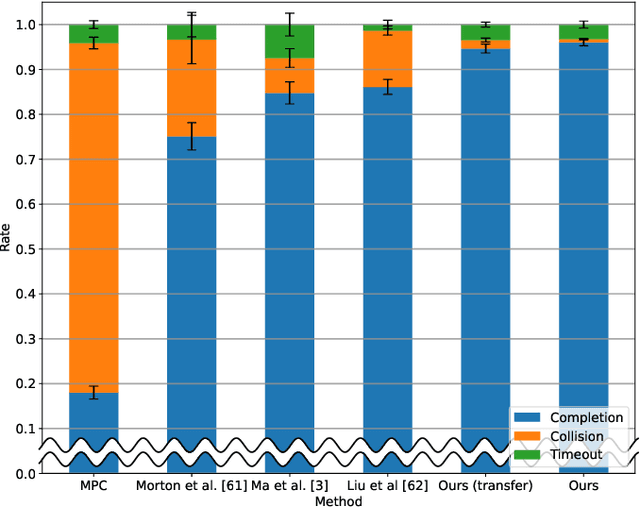
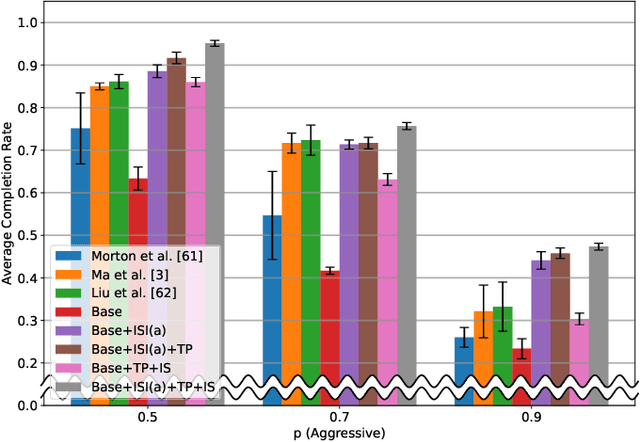
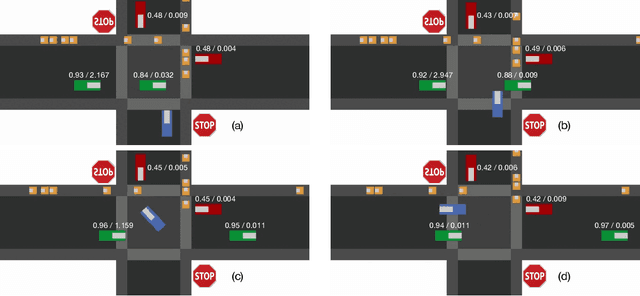
Deep reinforcement learning (DRL) provides a promising way for intelligent agents (e.g., autonomous vehicles) to learn to navigate complex scenarios. However, DRL with neural networks as function approximators is typically considered a black box with little explainability and often suffers from suboptimal performance, especially for autonomous navigation in highly interactive multi-agent environments. To address these issues, we propose three auxiliary tasks with spatio-temporal relational reasoning and integrate them into the standard DRL framework, which improves the decision making performance and provides explainable intermediate indicators. We propose to explicitly infer the internal states (i.e., traits and intentions) of surrounding agents (e.g., human drivers) as well as to predict their future trajectories in the situations with and without the ego agent through counterfactual reasoning. These auxiliary tasks provide additional supervision signals to infer the behavior patterns of other interactive agents. Multiple variants of framework integration strategies are compared. We also employ a spatio-temporal graph neural network to encode relations between dynamic entities, which enhances both internal state inference and decision making of the ego agent. Moreover, we propose an interactivity estimation mechanism based on the difference between predicted trajectories in these two situations, which indicates the degree of influence of the ego agent on other agents. To validate the proposed method, we design an intersection driving simulator based on the Intelligent Intersection Driver Model (IIDM) that simulates vehicles and pedestrians. Our approach achieves robust and state-of-the-art performance in terms of standard evaluation metrics and provides explainable intermediate indicators (i.e., internal states, and interactivity scores) for decision making.
Robust Driving Policy Learning with Guided Meta Reinforcement Learning
Jul 19, 2023



Although deep reinforcement learning (DRL) has shown promising results for autonomous navigation in interactive traffic scenarios, existing work typically adopts a fixed behavior policy to control social vehicles in the training environment. This may cause the learned driving policy to overfit the environment, making it difficult to interact well with vehicles with different, unseen behaviors. In this work, we introduce an efficient method to train diverse driving policies for social vehicles as a single meta-policy. By randomizing the interaction-based reward functions of social vehicles, we can generate diverse objectives and efficiently train the meta-policy through guiding policies that achieve specific objectives. We further propose a training strategy to enhance the robustness of the ego vehicle's driving policy using the environment where social vehicles are controlled by the learned meta-policy. Our method successfully learns an ego driving policy that generalizes well to unseen situations with out-of-distribution (OOD) social agents' behaviors in a challenging uncontrolled T-intersection scenario.
Recursive Reasoning Graph for Multi-Agent Reinforcement Learning
Mar 06, 2022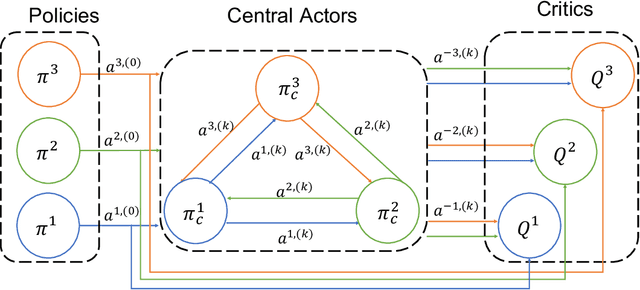
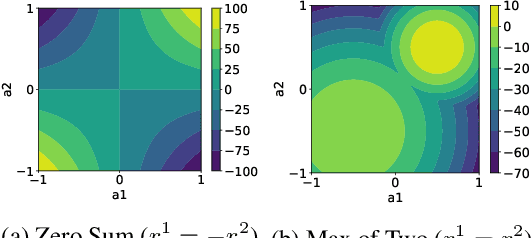
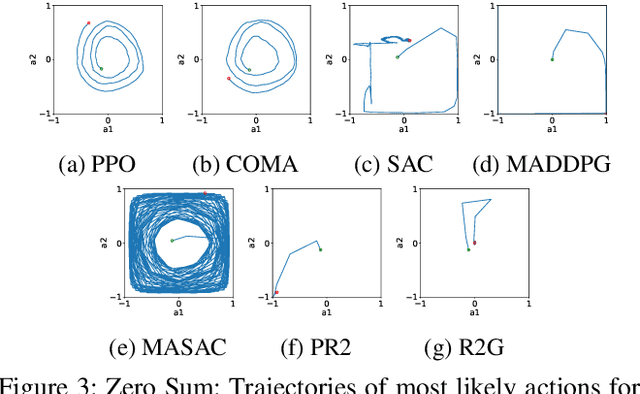
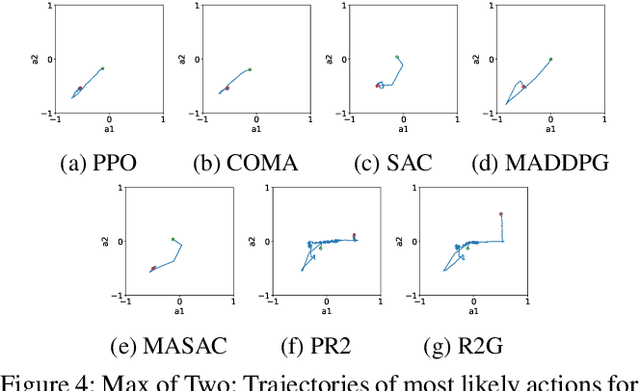
Multi-agent reinforcement learning (MARL) provides an efficient way for simultaneously learning policies for multiple agents interacting with each other. However, in scenarios requiring complex interactions, existing algorithms can suffer from an inability to accurately anticipate the influence of self-actions on other agents. Incorporating an ability to reason about other agents' potential responses can allow an agent to formulate more effective strategies. This paper adopts a recursive reasoning model in a centralized-training-decentralized-execution framework to help learning agents better cooperate with or compete against others. The proposed algorithm, referred to as the Recursive Reasoning Graph (R2G), shows state-of-the-art performance on multiple multi-agent particle and robotics games.
Risk-Aware Lane Selection on Highway with Dynamic Obstacles
Apr 08, 2021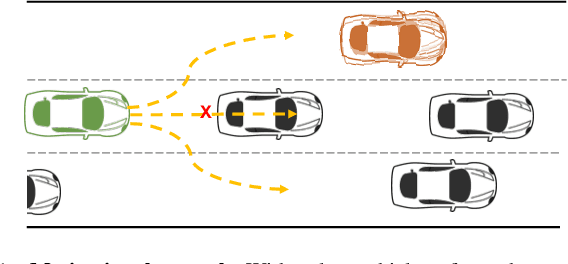

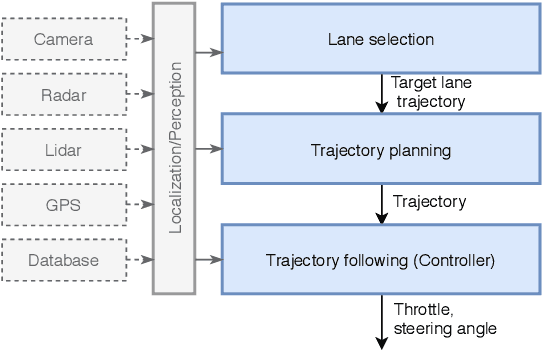
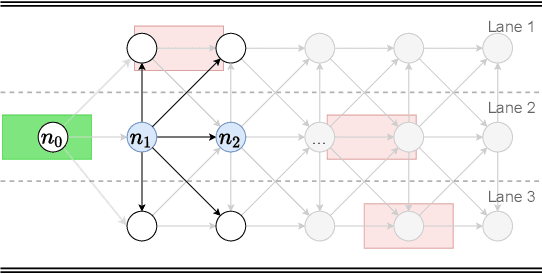
This paper proposes a discretionary lane selection algorithm. In particular, highway driving is considered as a targeted scenario, where each lane has a different level of traffic flow. When lane-changing is discretionary, it is advised not to change lanes unless highly beneficial, e.g., reducing travel time significantly or securing higher safety. Evaluating such "benefit" is a challenge, along with multiple surrounding vehicles in dynamic speed and heading with uncertainty. We propose a real-time lane-selection algorithm with careful cost considerations and with modularity in design. The algorithm is a search-based optimization method that evaluates uncertain dynamic positions of other vehicles under a continuous time and space domain. For demonstration, we incorporate a state-of-the-art motion planner framework (Neural Networks integrated Model Predictive Control) under a CARLA simulation environment.
Reinforcement Learning for Autonomous Driving with Latent State Inference and Spatial-Temporal Relationships
Nov 09, 2020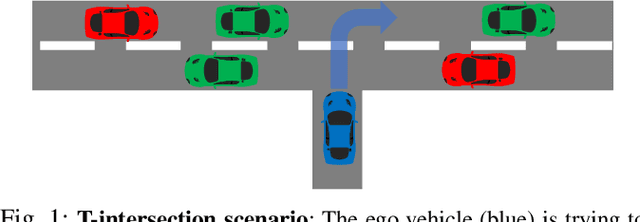
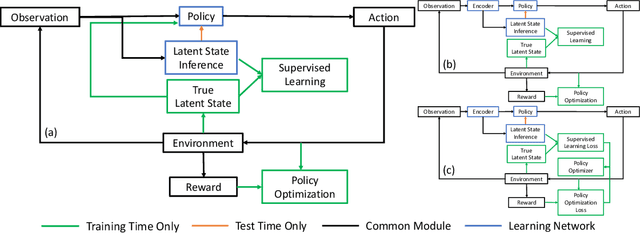
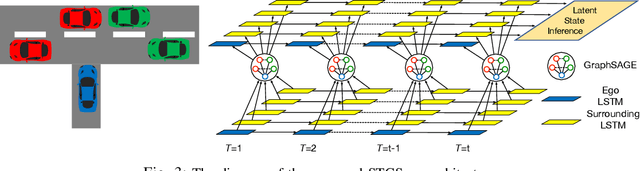
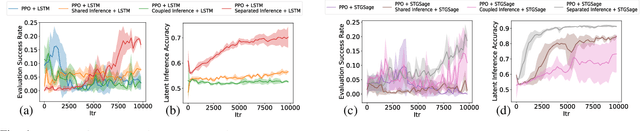
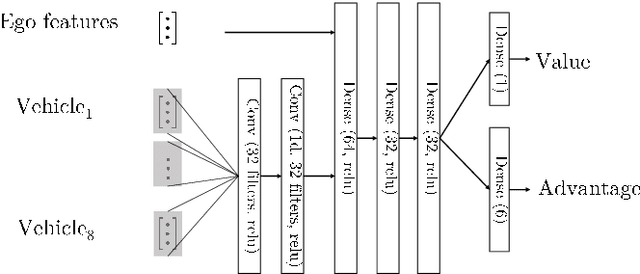
Deep reinforcement learning (DRL) provides a promising way for learning navigation in complex autonomous driving scenarios. However, identifying the subtle cues that can indicate drastically different outcomes remains an open problem with designing autonomous systems that operate in human environments. In this work, we show that explicitly inferring the latent state and encoding spatial-temporal relationships in a reinforcement learning framework can help address this difficulty. We encode prior knowledge on the latent states of other drivers through a framework that combines the reinforcement learner with a supervised learner. In addition, we model the influence passing between different vehicles through graph neural networks (GNNs). The proposed framework significantly improves performance in the context of navigating T-intersections compared with state-of-the-art baseline approaches.
Reinforcement Learning with Iterative Reasoning for Merging in Dense Traffic
May 25, 2020


Maneuvering in dense traffic is a challenging task for autonomous vehicles because it requires reasoning about the stochastic behaviors of many other participants. In addition, the agent must achieve the maneuver within a limited time and distance. In this work, we propose a combination of reinforcement learning and game theory to learn merging behaviors. We design a training curriculum for a reinforcement learning agent using the concept of level-$k$ behavior. This approach exposes the agent to a broad variety of behaviors during training, which promotes learning policies that are robust to model discrepancies. We show that our approach learns more efficient policies than traditional training methods.
* 6pages, 5 figures
Cooperation-Aware Lane Change Maneuver in Dense Traffic based on Model Predictive Control with Recurrent Neural Network
Sep 29, 2019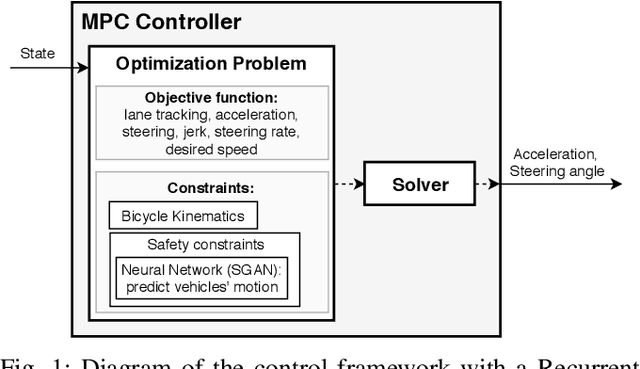
This paper presents a real-time lane change control framework of autonomous driving in dense traffic, which exploits cooperative behaviors of other drivers. This paper focuses on heavy traffic where vehicles cannot change lanes without cooperating with other drivers. In this case, classical robust controls may not apply since there is no safe area to merge to without interacting with the other drivers. That said, modeling complex and interactive human behaviors is highly non-trivial from the perspective of control engineers. We propose a mathematical control framework based on Model Predictive Control (MPC) encompassing a state-of-the-art Recurrent Neural network (RNN) architecture. In particular, RNN predicts interactive motions of other drivers in response to potential actions of the autonomous vehicle, which are then systematically evaluated in safety constraints. We also propose a real-time heuristic algorithm to find locally optimal control inputs. Finally, quantitative and qualitative analysis on simulation studies are presented to illustrate the benefits of the proposed framework.
Interaction-Aware Multi-Agent Reinforcement Learning for Mobile Agents with Individual Goals
Sep 27, 2019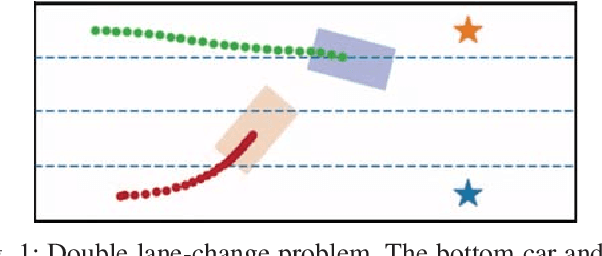
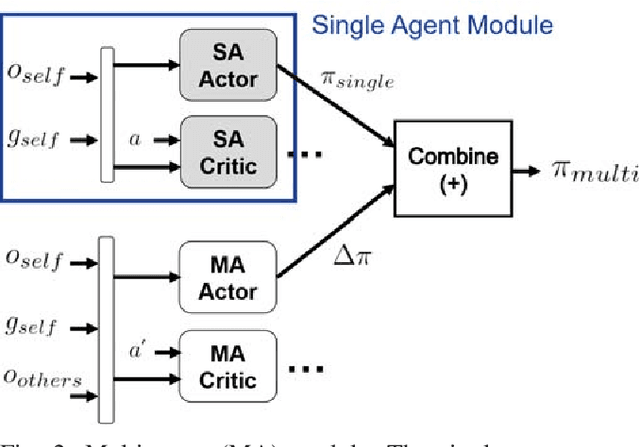
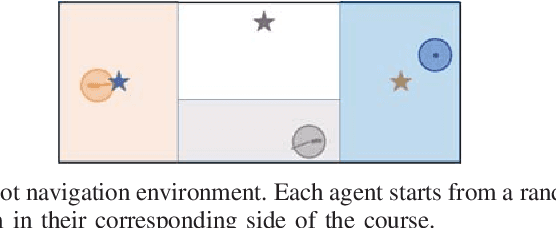

In a multi-agent setting, the optimal policy of a single agent is largely dependent on the behavior of other agents. We investigate the problem of multi-agent reinforcement learning, focusing on decentralized learning in non-stationary domains for mobile robot navigation. We identify a cause for the difficulty in training non-stationary policies: mutual adaptation to sub-optimal behaviors, and we use this to motivate a curriculum-based strategy for learning interactive policies. The curriculum has two stages. First, the agent leverages policy gradient algorithms to learn a policy that is capable of achieving multiple goals. Second, the agent learns a modifier policy to learn how to interact with other agents in a multi-agent setting. We evaluated our approach on both an autonomous driving lane-change domain and a robot navigation domain.
Safe Reinforcement Learning on Autonomous Vehicles
Sep 27, 2019
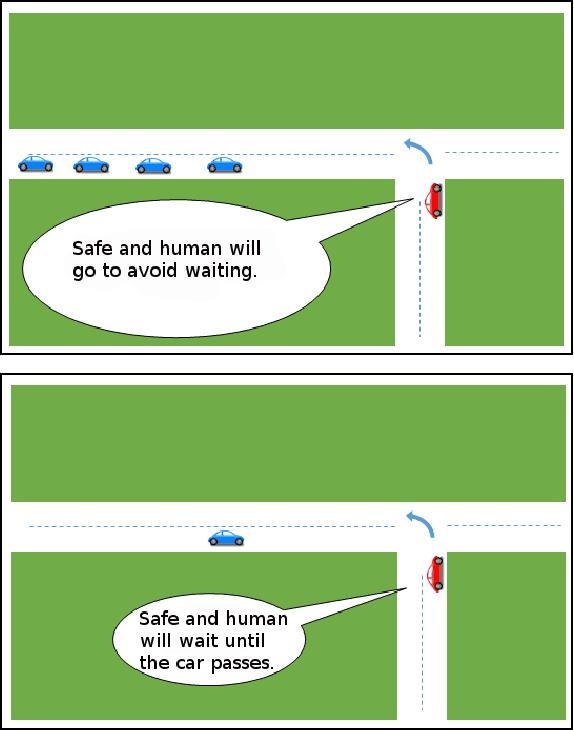
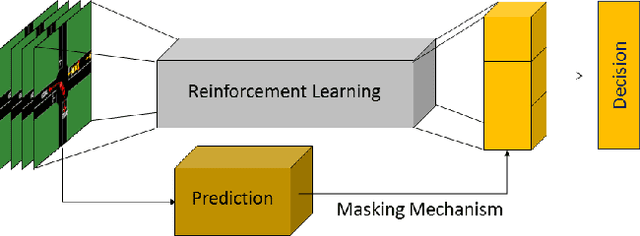
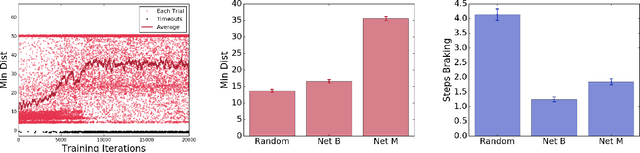
There have been numerous advances in reinforcement learning, but the typically unconstrained exploration of the learning process prevents the adoption of these methods in many safety critical applications. Recent work in safe reinforcement learning uses idealized models to achieve their guarantees, but these models do not easily accommodate the stochasticity or high-dimensionality of real world systems. We investigate how prediction provides a general and intuitive framework to constraint exploration, and show how it can be used to safely learn intersection handling behaviors on an autonomous vehicle.
Driving in Dense Traffic with Model-Free Reinforcement Learning
Sep 15, 2019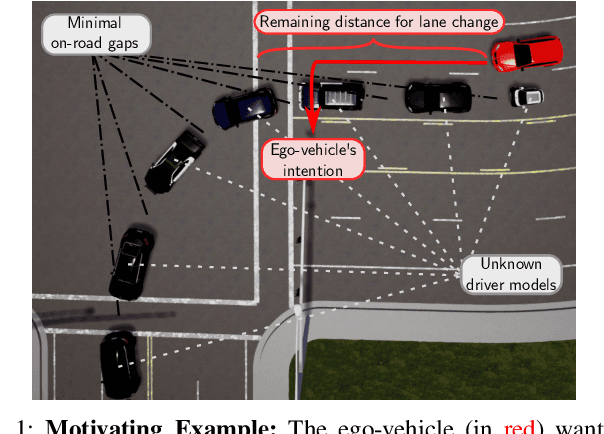
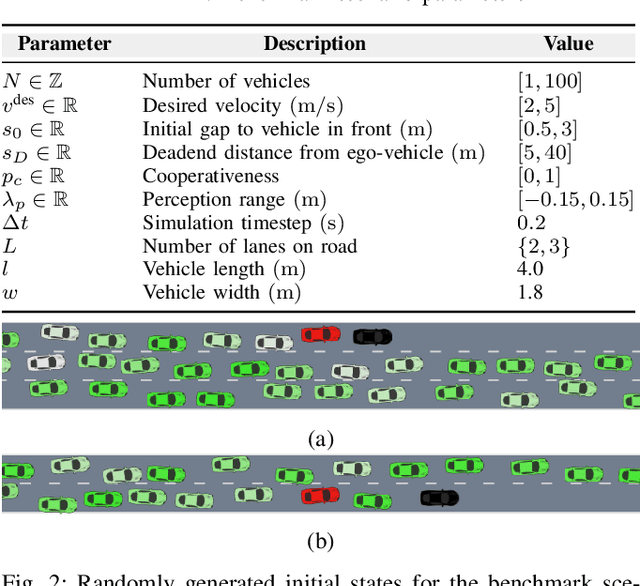
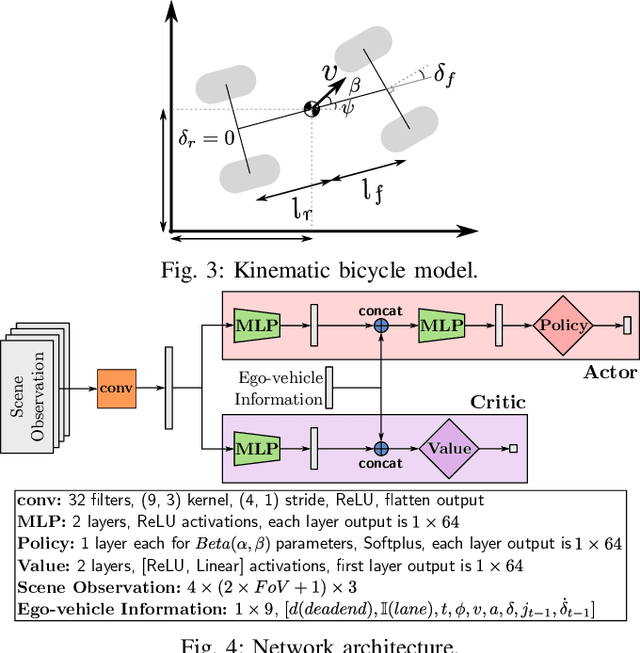
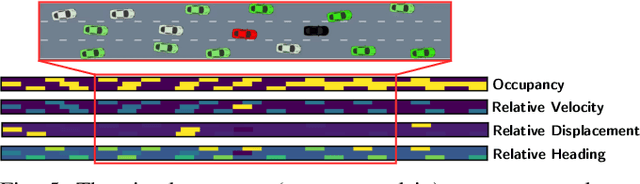
Traditional planning and control methods could fail to find a feasible trajectory for an autonomous vehicle to execute amongst dense traffic on roads. This is because the obstacle-free volume in spacetime is very small in these scenarios for the vehicle to drive through. However, that does not mean the task is infeasible since human drivers are known to be able to drive amongst dense traffic by leveraging the cooperativeness of other drivers to open a gap. The traditional methods fail to take into account the fact that the actions taken by an agent affect the behaviour of other vehicles on the road. In this work, we rely on the ability of deep reinforcement learning to implicitly model such interactions and learn a continuous control policy over the action space of an autonomous vehicle. The application we consider requires our agent to negotiate and open a gap in the road in order to successfully merge or change lanes. Our policy learns to repeatedly probe into the target road lane while trying to find a safe spot to move in to. We compare against two model-predictive control-based algorithms and show that our policy outperforms them in simulation.