 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning for Complex Non-prehensile Manipulation Among Movable Objects by Interleaving Multi-Agent Pathfinding and Physics-Based Simulation
Mar 23, 2023



Real-world manipulation problems in heavy clutter require robots to reason about potential contacts with objects in the environment. We focus on pick-and-place style tasks to retrieve a target object from a shelf where some `movable' objects must be rearranged in order to solve the task. In particular, our motivation is to allow the robot to reason over and consider non-prehensile rearrangement actions that lead to complex robot-object and object-object interactions where multiple objects might be moved by the robot simultaneously, and objects might tilt, lean on each other, or topple. To support this, we query a physics-based simulator to forward simulate these interaction dynamics which makes action evaluation during planning computationally very expensive. To make the planner tractable, we establish a connection between the domain of Manipulation Among Movable Objects and Multi-Agent Pathfinding that lets us decompose the problem into two phases our M4M algorithm iterates over. First we solve a multi-agent planning problem that reasons about the configurations of movable objects but does not forward simulate a physics model. Next, an arm motion planning problem is solved that uses a physics-based simulator but does not search over possible configurations of movable objects. We run simulated and real-world experiments with the PR2 robot and compare against relevant baseline algorithms. Our results highlight that M4M generates complex 3D interactions, and solves at least twice as many problems as the baselines with competitive performance.
AMRA*: Anytime Multi-Resolution Multi-Heuristic A*
Oct 11, 2021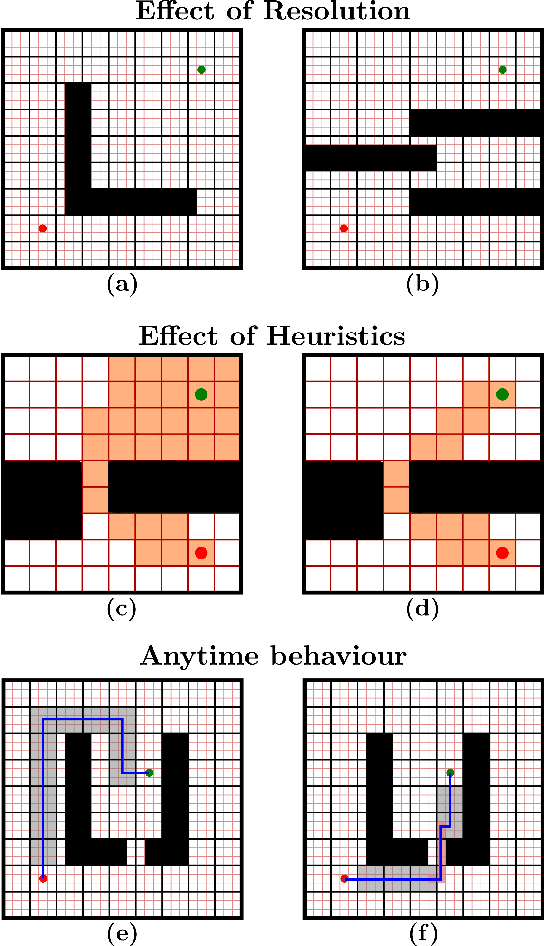
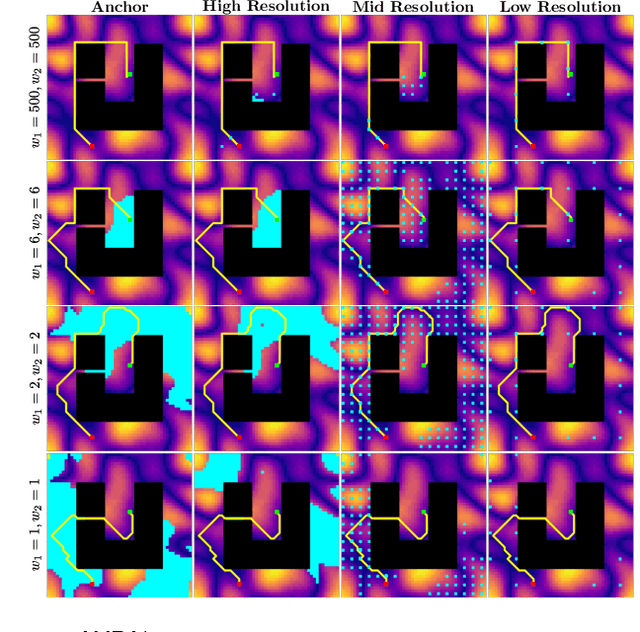

Heuristic search-based motion planning algorithms typically discretise the search space in order to solve the shortest path problem. Their performance is closely related to this discretisation. A fine discretisation allows for better approximations of the continuous search space, but makes the search for a solution more computationally costly. A coarser resolution might allow the algorithms to find solutions quickly at the expense of quality. For large state spaces, it can be beneficial to search for solutions across multiple resolutions even though defining the discretisations is challenging. The recently proposed algorithm Multi-Resolution A* (MRA*) searches over multiple resolutions. It traverses large areas of obstacle-free space and escapes local minima at a coarse resolution. It can also navigate so-called narrow passageways at a finer resolution. In this work, we develop AMRA*, an anytime version of MRA*. AMRA* tries to find a solution quickly using the coarse resolution as much as possible. It then refines the solution by relying on the fine resolution to discover better paths that may not have been available at the coarse resolution. In addition to being anytime, AMRA* can also leverage information sharing between multiple heuristics. We prove that AMRA* is complete and optimal (in-the-limit of time) with respect to the finest resolution. We show its performance on 2D grid navigation and 4D kinodynamic planning problems.
Manipulation Planning Among Movable Obstacles Using Physics-Based Adaptive Motion Primitives
Feb 08, 2021
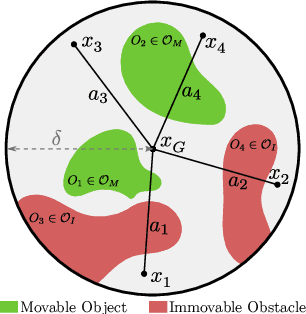
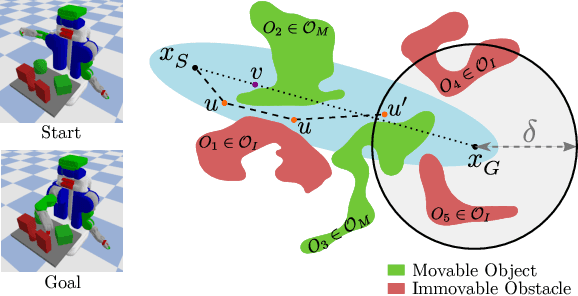
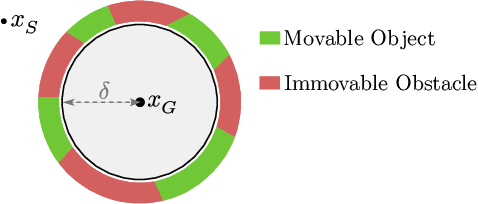
Robot manipulation in cluttered scenes often requires contact-rich interactions with objects. It can be more economical to interact via non-prehensile actions, for example, push through other objects to get to the desired grasp pose, instead of deliberate prehensile rearrangement of the scene. For each object in a scene, depending on its properties, the robot may or may not be allowed to make contact with, tilt, or topple it. To ensure that these constraints are satisfied during non-prehensile interactions, a planner can query a physics-based simulator to evaluate the complex multi-body interactions caused by robot actions. Unfortunately, it is infeasible to query the simulator for thousands of actions that need to be evaluated in a typical planning problem as each simulation is time-consuming. In this work, we show that (i) manipulation tasks (specifically pick-and-place style tasks from a tabletop or a refrigerator) can often be solved by restricting robot-object interactions to adaptive motion primitives in a plan, (ii) these actions can be incorporated as subgoals within a multi-heuristic search framework, and (iii) limiting interactions to these actions can help reduce the time spent querying the simulator during planning by up to 40x in comparison to baseline algorithms. Our algorithm is evaluated in simulation and in the real-world on a PR2 robot using PyBullet as our physics-based simulator. Supplementary video: \url{https://youtu.be/ABQc7JbeJPM}.
Search-based Planning for Active Sensing in Goal-Directed Coverage Tasks
Nov 14, 2020
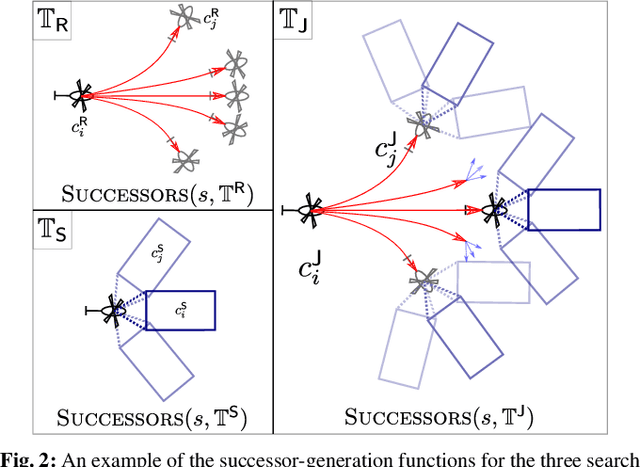

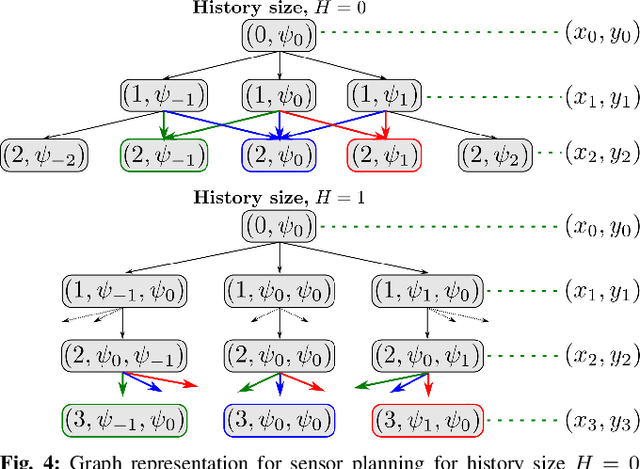
Path planning for robotic coverage is the task of determining a collision-free robot trajectory that observes all points of interest in an environment. Robots employed for such tasks are often capable of exercising active control over onboard observational sensors during navigation. In this paper, we tackle the problem of planning robot and sensor trajectories that maximize information gain in such tasks where the robot needs to cover points of interest with its sensor footprint. Search-based planners in general guarantee completeness and provable bounds on suboptimality with respect to an underlying graph discretization. However, searching for kinodynamically feasible paths in the joint space of robot and sensor state variables with standard search is computationally expensive. We propose two alternative search-based approaches to this problem. The first solves for robot and sensor trajectories independently in decoupled state spaces while maintaining a history of sensor headings during the search. The second is a two-step approach that first quickly computes a solution in decoupled state spaces and then refines it by searching its local neighborhood in the joint space for a better solution. We evaluate our approaches in simulation with a kinodynamically constrained unmanned aerial vehicle performing coverage over a 2D environment and show their benefits.
Driving in Dense Traffic with Model-Free Reinforcement Learning
Sep 15, 2019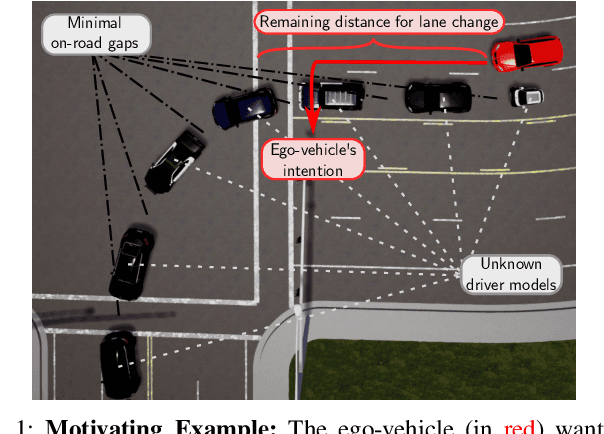
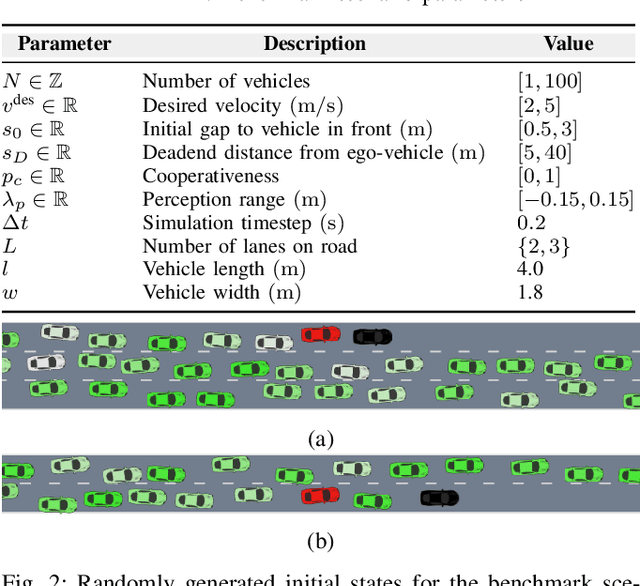
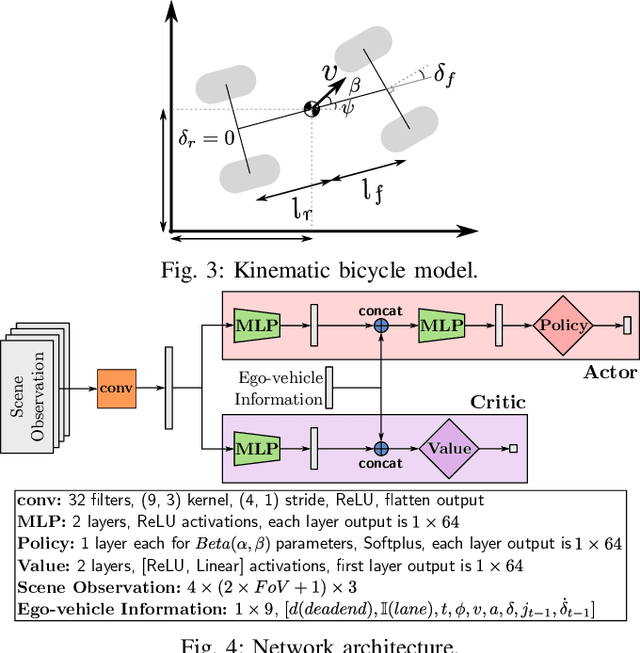
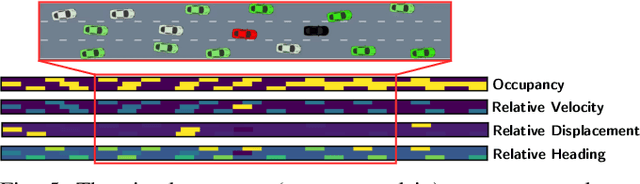
Traditional planning and control methods could fail to find a feasible trajectory for an autonomous vehicle to execute amongst dense traffic on roads. This is because the obstacle-free volume in spacetime is very small in these scenarios for the vehicle to drive through. However, that does not mean the task is infeasible since human drivers are known to be able to drive amongst dense traffic by leveraging the cooperativeness of other drivers to open a gap. The traditional methods fail to take into account the fact that the actions taken by an agent affect the behaviour of other vehicles on the road. In this work, we rely on the ability of deep reinforcement learning to implicitly model such interactions and learn a continuous control policy over the action space of an autonomous vehicle. The application we consider requires our agent to negotiate and open a gap in the road in order to successfully merge or change lanes. Our policy learns to repeatedly probe into the target road lane while trying to find a safe spot to move in to. We compare against two model-predictive control-based algorithms and show that our policy outperforms them in simulation.
A Planning Framework for Persistent, Multi-UAV Coverage with Global Deconfliction
Aug 27, 2019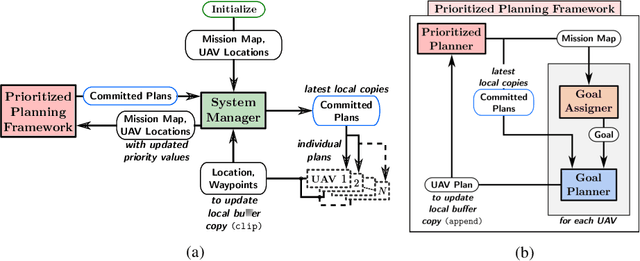
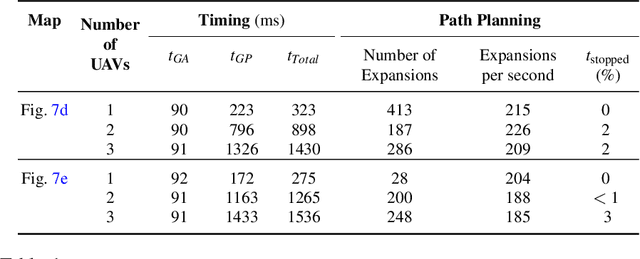
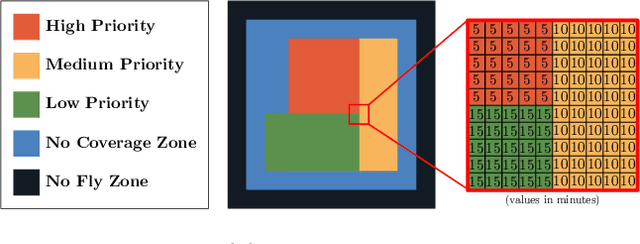
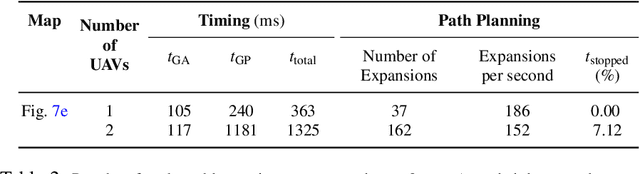
Planning for multi-robot coverage seeks to determine collision-free paths for a fleet of robots, enabling them to collectively observe points of interest in an environment. Persistent coverage is a variant of traditional coverage where coverage-levels in the environment decay over time. Thus, robots have to continuously revisit parts of the environment to maintain a desired coverage-level. Facilitating this in the real world demands we tackle numerous subproblems. While there exist standard solutions to these subproblems, there is no complete framework that addresses all of their individual challenges as a whole in a practical setting. We adapt and combine these solutions to present a planning framework for persistent coverage with multiple unmanned aerial vehicles (UAVs). Specifically, we run a continuous loop of goal assignment and globally deconflicting, kinodynamic path planning for multiple UAVs. We evaluate our framework in simulation as well as the real world. In particular, we demonstrate that (i) our framework exhibits graceful coverage given sufficient resources, we maintain persistent coverage; if resources are insufficient (e.g., having too few UAVs for a given size of the enviornment), coverage-levels decay slowly and (ii) planning with global deconfliction in our framework incurs a negligibly higher price compared to other weaker, more local collision-checking schemes. (Video: https://youtu.be/aqDs6Wymp5Q)