 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaiting Tables as a Robot Planning Problem
May 21, 2021
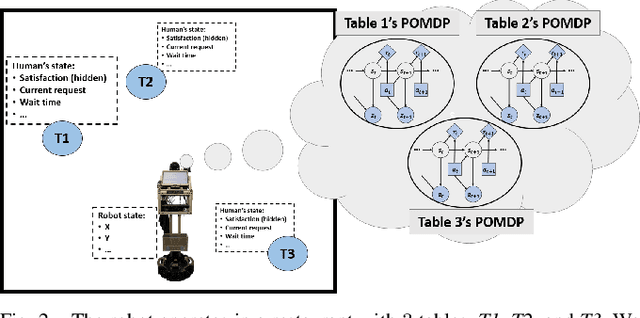
We present how we formalize the waiting tables task in a restaurant as a robot planning problem. This formalization was used to test our recently developed algorithms that allow for optimal planning for achieving multiple independent tasks that are partially observable and evolve over time [1], [2].
Theory and Analysis of Optimal Planning over Long and Infinite Horizons for Achieving Independent Partially-Observable Tasks that Evolve over Time
Feb 25, 2021We present the theoretical analysis and proofs of a recently developed algorithm that allows for optimal planning over long and infinite horizons for achieving multiple independent tasks that are partially observable and evolve over time.
Interaction-Aware Multi-Agent Reinforcement Learning for Mobile Agents with Individual Goals
Sep 27, 2019
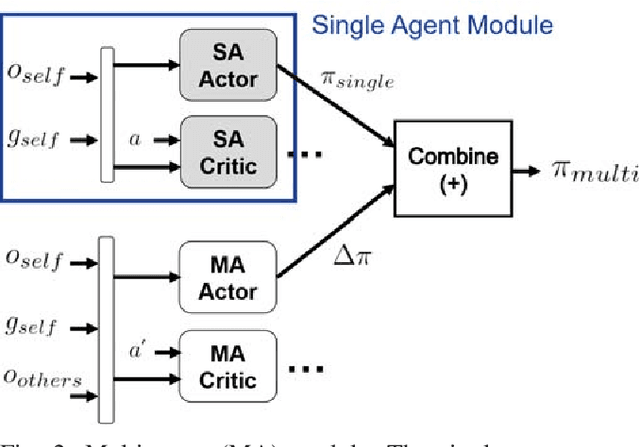
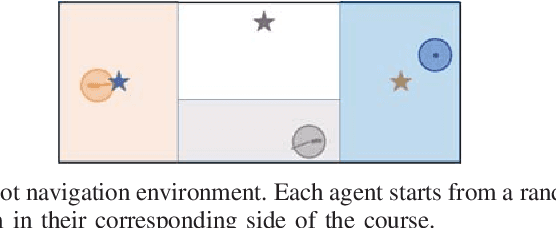

In a multi-agent setting, the optimal policy of a single agent is largely dependent on the behavior of other agents. We investigate the problem of multi-agent reinforcement learning, focusing on decentralized learning in non-stationary domains for mobile robot navigation. We identify a cause for the difficulty in training non-stationary policies: mutual adaptation to sub-optimal behaviors, and we use this to motivate a curriculum-based strategy for learning interactive policies. The curriculum has two stages. First, the agent leverages policy gradient algorithms to learn a policy that is capable of achieving multiple goals. Second, the agent learns a modifier policy to learn how to interact with other agents in a multi-agent setting. We evaluated our approach on both an autonomous driving lane-change domain and a robot navigation domain.