 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM3: Cooperative Multi-goal Multi-stage Multi-agent Reinforcement Learning
Paper and Code

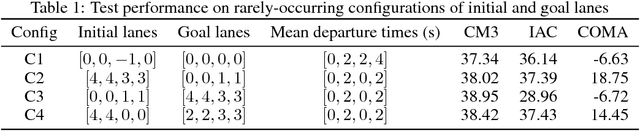

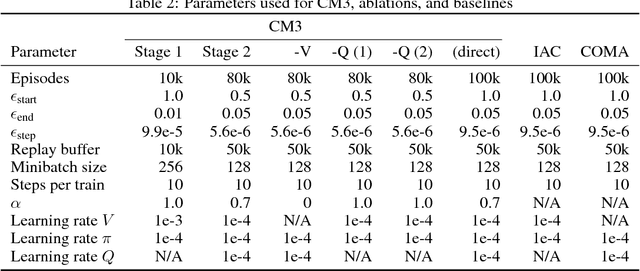
We propose CM3, a new deep reinforcement learning method for cooperative multi-agent problems where agents must coordinate for joint success in achieving different individual goals. We restructure multi-agent learning into a two-stage curriculum, consisting of a single-agent stage for learning to accomplish individual tasks, followed by a multi-agent stage for learning to cooperate in the presence of other agents. These two stages are bridged by modular augmentation of neural network policy and value functions. We further adapt the actor-critic framework to this curriculum by formulating local and global views of the policy gradient and learning via a double critic, consisting of a decentralized value function and a centralized action-value function. We evaluated CM3 on a new high-dimensional multi-agent environment with sparse rewards: negotiating lane changes among multiple autonomous vehicles in the Simulation of Urban Mobility (SUMO) traffic simulator. Detailed ablation experiments show the positive contribution of each component in CM3, and the overall synthesis converges significantly faster to higher performance policies than existing cooperative multi-agent methods.