 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep reinforcement learning approach to MIMO precoding problem: Optimality and Robustness
Paper and Code
Jun 30, 2020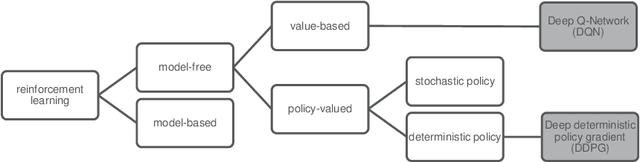

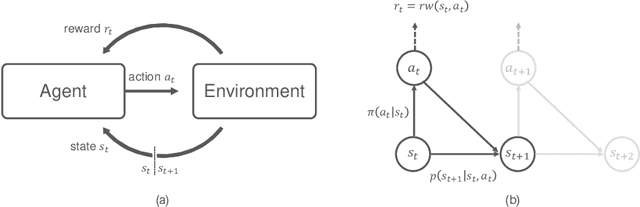
In this paper, we propose a deep reinforcement learning (RL)-based precoding framework that can be used to learn an optimal precoding policy for complex multiple-input multiple-output (MIMO) precoding problems. We model the precoding problem for a single-user MIMO system as an RL problem in which a learning agent sequentially selects the precoders to serve the environment of MIMO system based on contextual information about the environmental conditions, while simultaneously adapting the precoder selection policy based on the reward feedback from the environment to maximize a numerical reward signal. We develop the RL agent with two canonical deep RL (DRL) algorithms, namely deep Q-network (DQN) and deep deterministic policy gradient (DDPG). To demonstrate the optimality of the proposed DRL-based precoding framework, we explicitly consider a simple MIMO environment for which the optimal solution can be obtained analytically and show that DQN- and DDPG-based agents can learn the near-optimal policy to map the environment state of MIMO system to a precoder that maximizes the reward function, respectively, in the codebook-based and non-codebook based MIMO precoding systems. Furthermore, to investigate the robustness of DRL-based precoding framework, we examine the performance of the two DRL algorithms in a complex MIMO environment, for which the optimal solution is not known. The numerical results confirm the effectiveness of the DRL-based precoding framework and show that the proposed DRL-based framework can outperform the conventional approximation algorithm in the complex MIMO environment.