 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFueling the Next Quantum Leap in Cellular Networks: Embracing AI in 5G Evolution towards 6G
Nov 20, 2021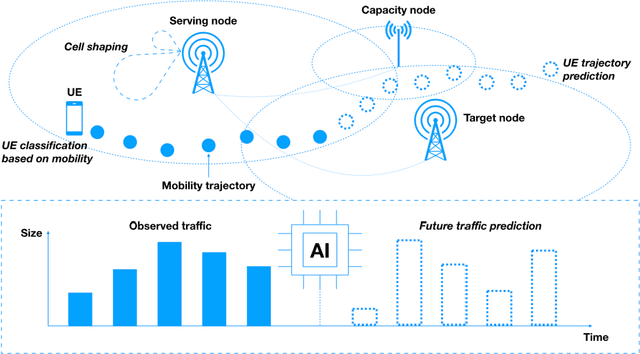
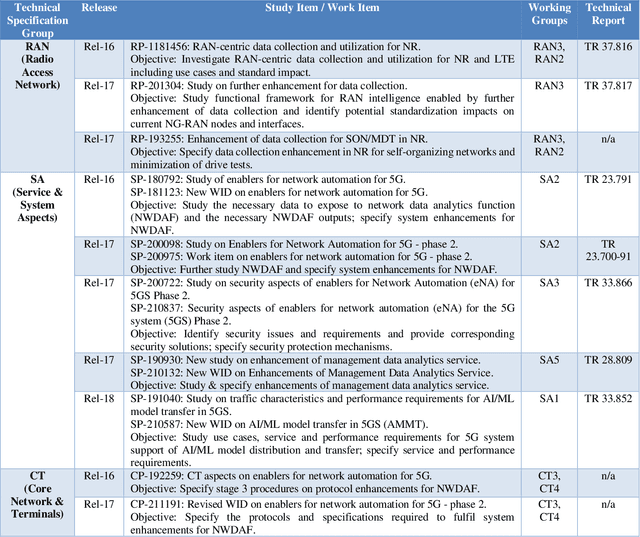
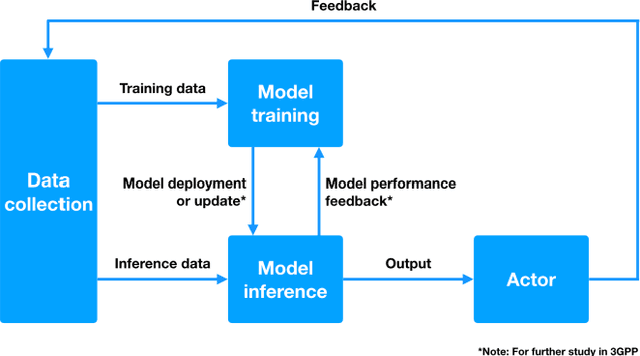
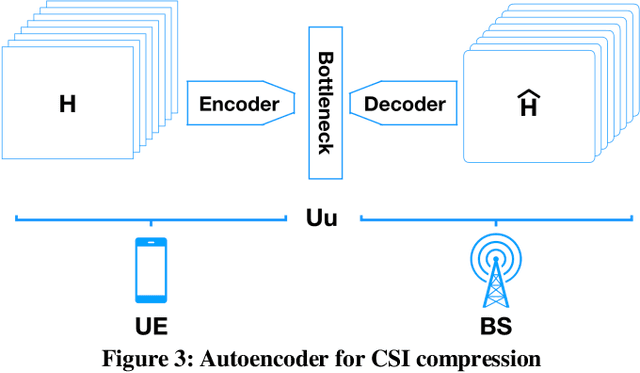
Cellular networks, such as 5G systems, are becoming increasingly complex for supporting various deployment scenarios and applications. Embracing artificial intelligence (AI) in 5G evolution is critical to managing the complexity and fueling the next quantum leap in 6G cellular networks. In this article, we share our experience and best practices in applying AI in cellular networks. We first present a primer on the state of the art of AI in cellular networks, including basic concepts and recent key advances. Then we discuss 3GPP standardization aspects and share various design rationales influencing standardization. We also present case studies with real network data to showcase how AI can improve network performance and enable network automation.
Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems
Sep 10, 2021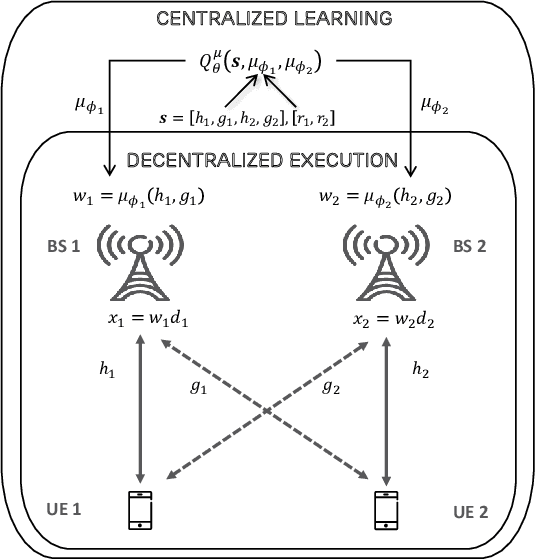
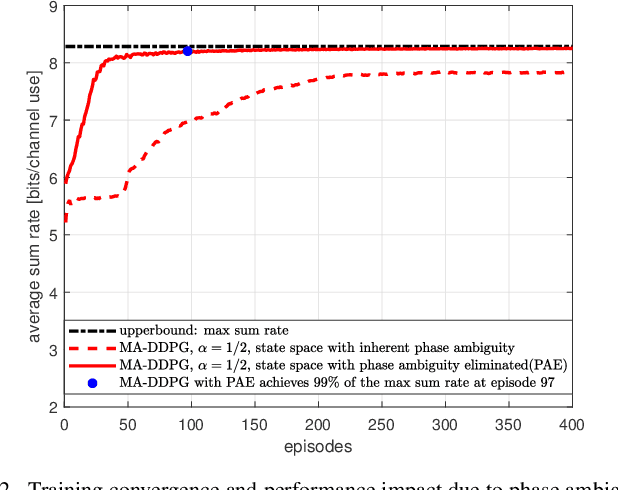
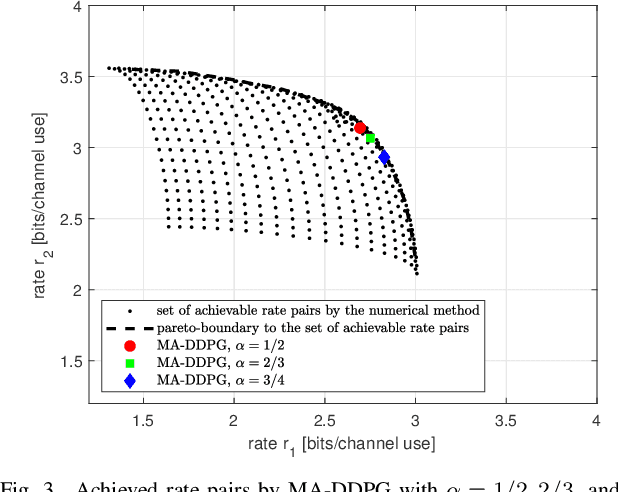

A multi-agent deep reinforcement learning (MADRL) is a promising approach to challenging problems in wireless environments involving multiple decision-makers (or actors) with high-dimensional continuous action space. In this paper, we present a MADRL-based approach that can jointly optimize precoders to achieve the outer-boundary, called pareto-boundary, of the achievable rate region for a multiple-input single-output (MISO) interference channel (IFC). In order to address two main challenges, namely, multiple actors (or agents) with partial observability and multi-dimensional continuous action space in MISO IFC setup, we adopt a multi-agent deep deterministic policy gradient (MA-DDPG) framework in which decentralized actors with partial observability can learn a multi-dimensional continuous policy in a centralized manner with the aid of shared critic with global information. Meanwhile, we will also address a phase ambiguity issue with the conventional complex baseband representation of signals widely used in radio communications. In order to mitigate the impact of phase ambiguity on training performance, we propose a training method, called phase ambiguity elimination (PAE), that leads to faster learning and better performance of MA-DDPG in wireless communication systems. The simulation results exhibit that MA-DDPG is capable of learning a near-optimal precoding strategy in a MISO IFC environment. To the best of our knowledge, this is the first work to demonstrate that the MA-DDPG framework can jointly optimize precoders to achieve the pareto-boundary of achievable rate region in a multi-cell multi-user multi-antenna system.
Deep reinforcement learning approach to MIMO precoding problem: Optimality and Robustness
Jun 30, 2020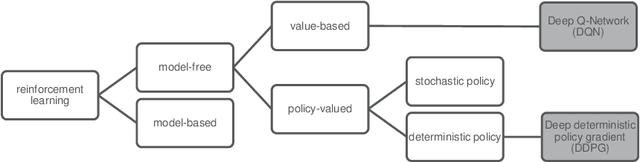

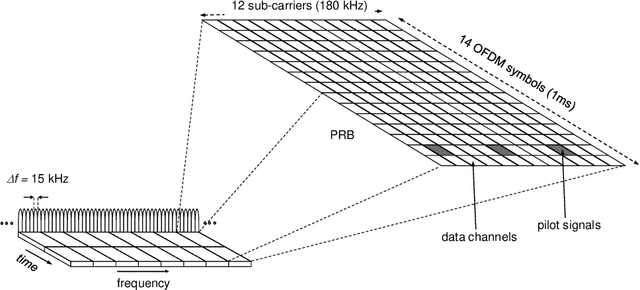
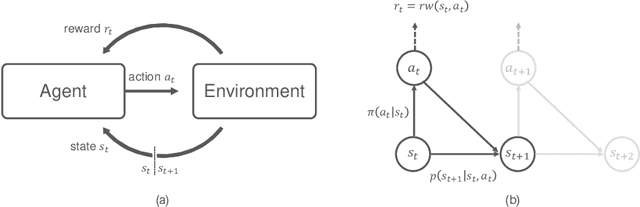
In this paper, we propose a deep reinforcement learning (RL)-based precoding framework that can be used to learn an optimal precoding policy for complex multiple-input multiple-output (MIMO) precoding problems. We model the precoding problem for a single-user MIMO system as an RL problem in which a learning agent sequentially selects the precoders to serve the environment of MIMO system based on contextual information about the environmental conditions, while simultaneously adapting the precoder selection policy based on the reward feedback from the environment to maximize a numerical reward signal. We develop the RL agent with two canonical deep RL (DRL) algorithms, namely deep Q-network (DQN) and deep deterministic policy gradient (DDPG). To demonstrate the optimality of the proposed DRL-based precoding framework, we explicitly consider a simple MIMO environment for which the optimal solution can be obtained analytically and show that DQN- and DDPG-based agents can learn the near-optimal policy to map the environment state of MIMO system to a precoder that maximizes the reward function, respectively, in the codebook-based and non-codebook based MIMO precoding systems. Furthermore, to investigate the robustness of DRL-based precoding framework, we examine the performance of the two DRL algorithms in a complex MIMO environment, for which the optimal solution is not known. The numerical results confirm the effectiveness of the DRL-based precoding framework and show that the proposed DRL-based framework can outperform the conventional approximation algorithm in the complex MIMO environment.