 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFFGAN: Ensembles of fine-tuned federated GANs
Jun 23, 2022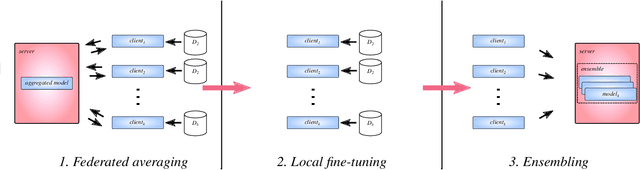


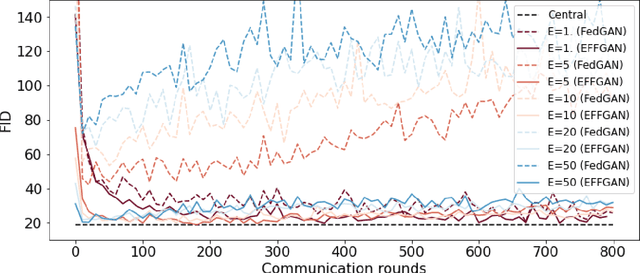
Generative adversarial networks have proven to be a powerful tool for learning complex and high-dimensional data distributions, but issues such as mode collapse have been shown to make it difficult to train them. This is an even harder problem when the data is decentralized over several clients in a federated learning setup, as problems such as client drift and non-iid data make it hard for federated averaging to converge. In this work, we study the task of how to learn a data distribution when training data is heterogeneously decentralized over clients and cannot be shared. Our goal is to sample from this distribution centrally, while the data never leaves the clients. We show using standard benchmark image datasets that existing approaches fail in this setting, experiencing so-called client drift when the local number of epochs becomes to large. We thus propose a novel approach we call EFFGAN: Ensembles of fine-tuned federated GANs. Being an ensemble of local expert generators, EFFGAN is able to learn the data distribution over all clients and mitigate client drift. It is able to train with a large number of local epochs, making it more communication efficient than previous works.
Decentralized adaptive clustering of deep nets is beneficial for client collaboration
Jun 17, 2022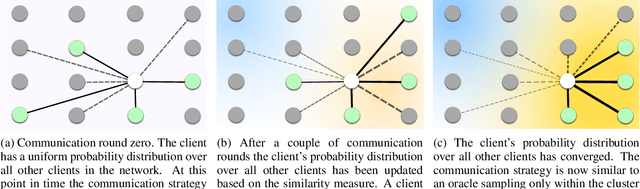
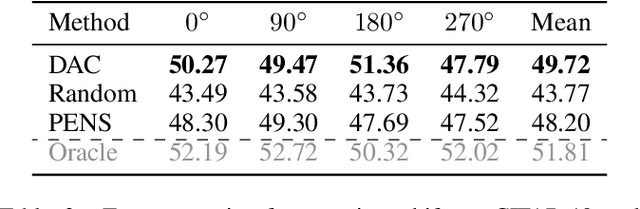
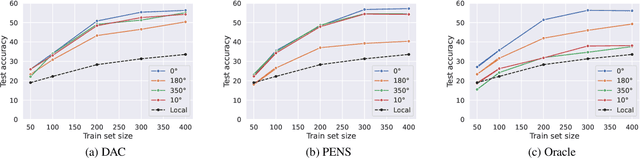

We study the problem of training personalized deep learning models in a decentralized peer-to-peer setting, focusing on the setting where data distributions differ between the clients and where different clients have different local learning tasks. We study both covariate and label shift, and our contribution is an algorithm which for each client finds beneficial collaborations based on a similarity estimate for the local task. Our method does not rely on hyperparameters which are hard to estimate, such as the number of client clusters, but rather continuously adapts to the network topology using soft cluster assignment based on a novel adaptive gossip algorithm. We test the proposed method in various settings where data is not independent and identically distributed among the clients. The experimental evaluation shows that the proposed method performs better than previous state-of-the-art algorithms for this problem setting, and handles situations well where previous methods fail.