 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeap: Inductive Link Prediction via Learnable TopologyAugmentation
Mar 05, 2025Link prediction is a crucial task in many downstream applications of graph machine learning. To this end, Graph Neural Network (GNN) is a widely used technique for link prediction, mainly in transductive settings, where the goal is to predict missing links between existing nodes. However, many real-life applications require an inductive setting that accommodates for new nodes, coming into an existing graph. Thus, recently inductive link prediction has attracted considerable attention, and a multi-layer perceptron (MLP) is the popular choice of most studies to learn node representations. However, these approaches have limited expressivity and do not fully capture the graph's structural signal. Therefore, in this work we propose LEAP, an inductive link prediction method based on LEArnable toPology augmentation. Unlike previous methods, LEAP models the inductive bias from both the structure and node features, and hence is more expressive. To the best of our knowledge, this is the first attempt to provide structural contexts for new nodes via learnable augmentation in inductive settings. Extensive experiments on seven real-world homogeneous and heterogeneous graphs demonstrates that LEAP significantly surpasses SOTA methods. The improvements are up to 22\% and 17\% in terms of AUC and average precision, respectively. The code and datasets are available on GitHub (https://github.com/AhmedESamy/LEAP/)
Jointly Learnable Data Augmentations for Self-Supervised GNNs
Aug 23, 2021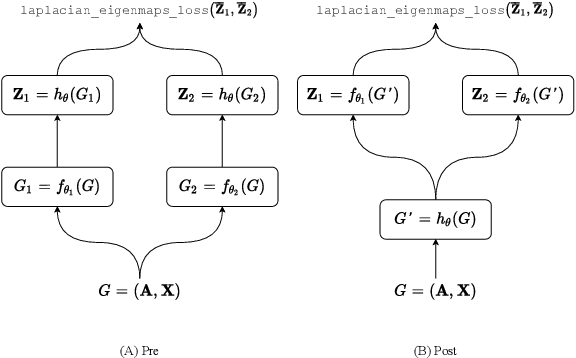

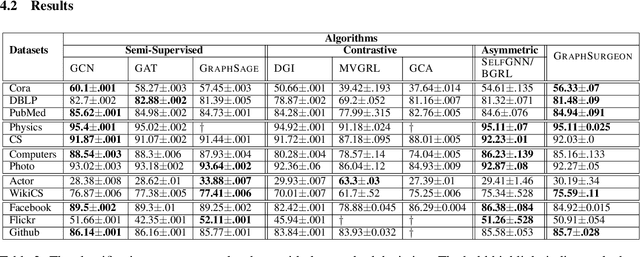

Self-supervised Learning (SSL) aims at learning representations of objects without relying on manual labeling. Recently, a number of SSL methods for graph representation learning have achieved performance comparable to SOTA semi-supervised GNNs. A Siamese network, which relies on data augmentation, is the popular architecture used in these methods. However, these methods rely on heuristically crafted data augmentation techniques. Furthermore, they use either contrastive terms or other tricks (e.g., asymmetry) to avoid trivial solutions that can occur in Siamese networks. In this study, we propose, GraphSurgeon, a novel SSL method for GNNs with the following features. First, instead of heuristics we propose a learnable data augmentation method that is jointly learned with the embeddings by leveraging the inherent signal encoded in the graph. In addition, we take advantage of the flexibility of the learnable data augmentation and introduce a new strategy that augments in the embedding space, called post augmentation. This strategy has a significantly lower memory overhead and run-time cost. Second, as it is difficult to sample truly contrastive terms, we avoid explicit negative sampling. Third, instead of relying on engineering tricks, we use a scalable constrained optimization objective motivated by Laplacian Eigenmaps to avoid trivial solutions. To validate the practical use of GraphSurgeon, we perform empirical evaluation using 14 public datasets across a number of domains and ranging from small to large scale graphs with hundreds of millions of edges. Our finding shows that GraphSurgeon is comparable to six SOTA semi-supervised and on par with five SOTA self-supervised baselines in node classification tasks. The source code is available at https://github.com/zekarias-tilahun/graph-surgeon.
Self-supervised Graph Neural Networks without explicit negative sampling
Apr 09, 2021

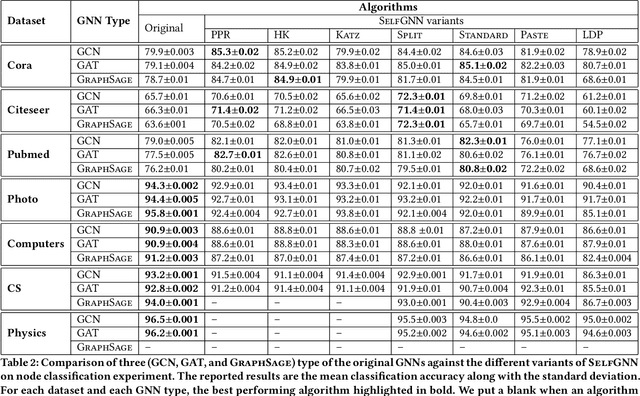
Real world data is mostly unlabeled or only few instances are labeled. Manually labeling data is a very expensive and daunting task. This calls for unsupervised learning techniques that are powerful enough to achieve comparable results as semi-supervised/supervised techniques. Contrastive self-supervised learning has emerged as a powerful direction, in some cases outperforming supervised techniques. In this study, we propose, SelfGNN, a novel contrastive self-supervised graph neural network (GNN) without relying on explicit contrastive terms. We leverage Batch Normalization, which introduces implicit contrastive terms, without sacrificing performance. Furthermore, as data augmentation is key in contrastive learning, we introduce four feature augmentation (FA) techniques for graphs. Though graph topological augmentation (TA) is commonly used, our empirical findings show that FA perform as good as TA. Moreover, FA incurs no computational overhead, unlike TA, which often has O(N^3) time complexity, N-number of nodes. Our empirical evaluation on seven publicly available real-world data shows that, SelfGNN is powerful and leads to a performance comparable with SOTA supervised GNNs and always better than SOTA semi-supervised and unsupervised GNNs. The source code is available at https://github.com/zekarias-tilahun/SelfGNN.
Dynamic Embeddings for Interaction Prediction
Nov 10, 2020
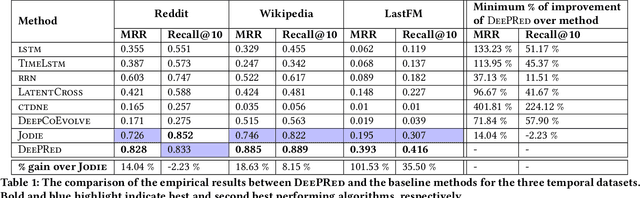

In recommender systems (RSs), predicting the next item that a user interacts with is critical for user retention. While the last decade has seen an explosion of RSs aimed at identifying relevant items that match user preferences, there is still a range of aspects that could be considered to further improve their performance. For example, often RSs are centered around the user, who is modeled using her recent sequence of activities. Recent studies, however, have shown the effectiveness of modeling the mutual interactions between users and items using separate user and item embeddings. Building on the success of these studies, we propose a novel method called DeePRed that addresses some of their limitations. In particular, we avoid recursive and costly interactions between consecutive short-term embeddings by using long-term (stationary) embeddings as a proxy. This enable us to train DeePRed using simple mini-batches without the overhead of specialized mini-batches proposed in previous studies. Moreover, DeePRed's effectiveness comes from the aforementioned design and a multi-way attention mechanism that inspects user-item compatibility. Experiments show that DeePRed outperforms the best state-of-the-art approach by at least 14% on next item prediction task, while gaining more than an order of magnitude speedup over the best performing baselines. Although this study is mainly concerned with temporal interaction networks, we also show the power and flexibility of DeePRed by adapting it to the case of static interaction networks, substituting the short- and long-term aspects with local and global ones.
Gossip and Attend: Context-Sensitive Graph Representation Learning
Mar 30, 2020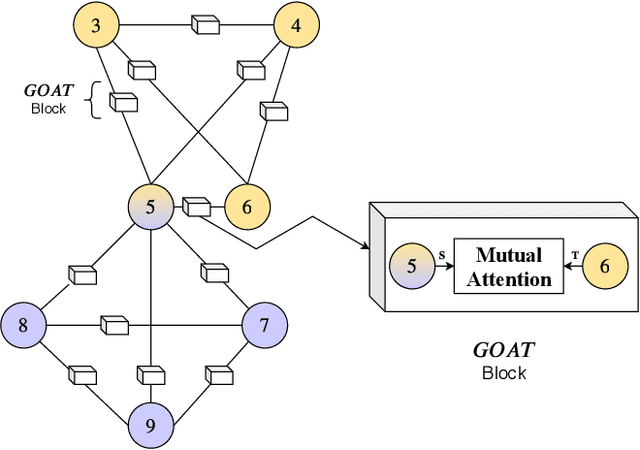



Graph representation learning (GRL) is a powerful technique for learning low-dimensional vector representation of high-dimensional and often sparse graphs. Most studies explore the structure and metadata associated with the graph using random walks and employ an unsupervised or semi-supervised learning schemes. Learning in these methods is context-free, resulting in only a single representation per node. Recently studies have argued on the adequacy of a single representation and proposed context-sensitive approaches, which are capable of extracting multiple node representations for different contexts. This proved to be highly effective in applications such as link prediction and ranking. However, most of these methods rely on additional textual features that require complex and expensive RNNs or CNNs to capture high-level features or rely on a community detection algorithm to identify multiple contexts of a node. In this study we show that in-order to extract high-quality context-sensitive node representations it is not needed to rely on supplementary node features, nor to employ computationally heavy and complex models. We propose GOAT, a context-sensitive algorithm inspired by gossip communication and a mutual attention mechanism simply over the structure of the graph. We show the efficacy of GOAT using 6 real-world datasets on link prediction and node clustering tasks and compare it against 12 popular and state-of-the-art (SOTA) baselines. GOAT consistently outperforms them and achieves up to 12% and 19% gain over the best performing methods on link prediction and clustering tasks, respectively.
Which way? Direction-Aware Attributed Graph Embedding
Jan 30, 2020
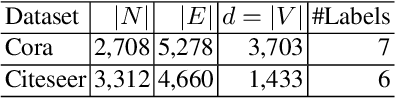
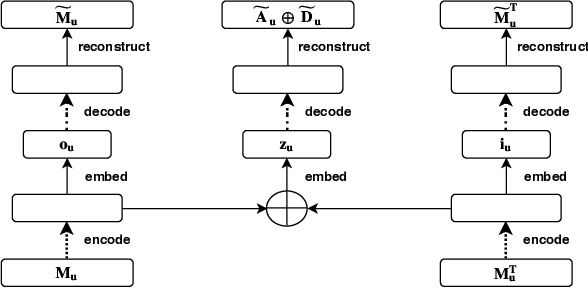
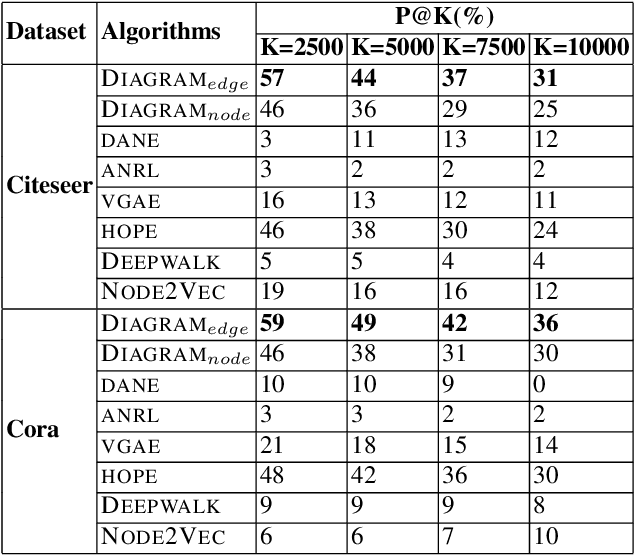
Graph embedding algorithms are used to efficiently represent (encode) a graph in a low-dimensional continuous vector space that preserves the most important properties of the graph. One aspect that is often overlooked is whether the graph is directed or not. Most studies ignore the directionality, so as to learn high-quality representations optimized for node classification. On the other hand, studies that capture directionality are usually effective on link prediction but do not perform well on other tasks. This preliminary study presents a novel text-enriched, direction-aware algorithm called DIAGRAM , based on a carefully designed multi-objective model to learn embeddings that preserve the direction of edges, textual features and graph context of nodes. As a result, our algorithm does not have to trade one property for another and jointly learns high-quality representations for multiple network analysis tasks. We empirically show that DIAGRAM significantly outperforms six state-of-the-art baselines, both direction-aware and oblivious ones,on link prediction and network reconstruction experiments using two popular datasets. It also achieves a comparable performance on node classification experiments against these baselines using the same datasets.
Graph Neighborhood Attentive Pooling
Jan 29, 2020


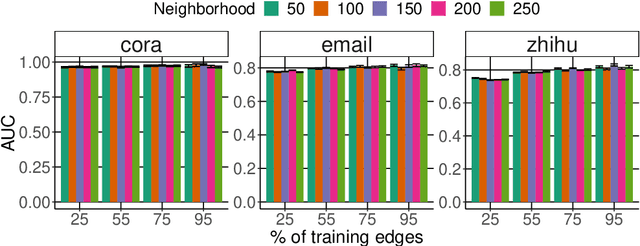
Network representation learning (NRL) is a powerful technique for learning low-dimensional vector representation of high-dimensional and sparse graphs. Most studies explore the structure and metadata associated with the graph using random walks and employ an unsupervised or semi-supervised learning schemes. Learning in these methods is context-free, because only a single representation per node is learned. Recently studies have argued on the sufficiency of a single representation and proposed a context-sensitive approach that proved to be highly effective in applications such as link prediction and ranking. However, most of these methods rely on additional textual features that require RNNs or CNNs to capture high-level features or rely on a community detection algorithm to identify multiple contexts of a node. In this study, without requiring additional features nor a community detection algorithm, we propose a novel context-sensitive algorithm called GAP that learns to attend on different parts of a node's neighborhood using attentive pooling networks. We show the efficacy of GAP using three real-world datasets on link prediction and node clustering tasks and compare it against 10 popular and state-of-the-art (SOTA) baselines. GAP consistently outperforms them and achieves up to ~9% and ~20% gain over the best performing methods on link prediction and clustering tasks, respectively.