 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Bank Compression for Continual Adaptation of Large Language Models
Jan 02, 2026Large Language Models (LLMs) have become a mainstay for many everyday applications. However, as data evolve their knowledge quickly becomes outdated. Continual learning aims to update LLMs with new information without erasing previously acquired knowledge. Although methods such as full fine-tuning can incorporate new data, they are computationally expensive and prone to catastrophic forgetting, where prior knowledge is overwritten. Memory-augmented approaches address this by equipping LLMs with a memory bank, that is an external memory module which stores information for future use. However, these methods face a critical limitation, in particular, the memory bank constantly grows in the real-world scenario when large-scale data streams arrive. In this paper, we propose MBC, a model that compresses the memory bank through a codebook optimization strategy during online adaptation learning. To ensure stable learning, we also introduce an online resetting mechanism that prevents codebook collapse. In addition, we employ Key-Value Low-Rank Adaptation in the attention layers of the LLM, enabling efficient utilization of the compressed memory representations. Experiments with benchmark question-answering datasets demonstrate that MBC reduces the memory bank size to 0.3% when compared against the most competitive baseline, while maintaining high retention accuracy during online adaptation learning. Our code is publicly available at https://github.com/Thomkat/MBC.
Pruning Overparameterized Multi-Task Networks for Degraded Web Image Restoration
Oct 16, 2025Image quality is a critical factor in delivering visually appealing content on web platforms. However, images often suffer from degradation due to lossy operations applied by online social networks (OSNs), negatively affecting user experience. Image restoration is the process of recovering a clean high-quality image from a given degraded input. Recently, multi-task (all-in-one) image restoration models have gained significant attention, due to their ability to simultaneously handle different types of image degradations. However, these models often come with an excessively high number of trainable parameters, making them computationally inefficient. In this paper, we propose a strategy for compressing multi-task image restoration models. We aim to discover highly sparse subnetworks within overparameterized deep models that can match or even surpass the performance of their dense counterparts. The proposed model, namely MIR-L, utilizes an iterative pruning strategy that removes low-magnitude weights across multiple rounds, while resetting the remaining weights to their original initialization. This iterative process is important for the multi-task image restoration model's optimization, effectively uncovering "winning tickets" that maintain or exceed state-of-the-art performance at high sparsity levels. Experimental evaluation on benchmark datasets for the deraining, dehazing, and denoising tasks shows that MIR-L retains only 10% of the trainable parameters while maintaining high image restoration performance. Our code, datasets and pre-trained models are made publicly available at https://github.com/Thomkat/MIR-L.
Multi-Task Learning with Loop Specific Attention for CDR Structure Prediction
Jun 22, 2023



The Complementarity Determining Region (CDR) structure prediction of loops in antibody engineering has gained a lot of attraction by researchers. When designing antibodies, a main challenge is to predict the CDR structure of the H3 loop. Compared with the other CDR loops, that is the H1 and H2 loops, the CDR structure of the H3 loop is more challenging due to its varying length and flexible structure. In this paper, we propose a Multi-task learning model with Loop Specific Attention, namely MLSA. In particular, to the best of our knowledge we are the first to jointly learn the three CDR loops, via a novel multi-task learning strategy. In addition, to account for the structural and functional similarities and differences of the three CDR loops, we propose a loop specific attention mechanism to control the influence of each CDR loop on the training of MLSA. Our experimental evaluation on widely used benchmark data shows that the proposed MLSA method significantly reduces the prediction error of the CDR structure of the H3 loop, by at least 19%, when compared with other baseline strategies. Finally, for reproduction purposes we make the implementation of MLSA publicly available at https://anonymous.4open.science/r/MLSA-2442/.
Sequence Adaptation via Reinforcement Learning in Recommender Systems
Jul 31, 2021
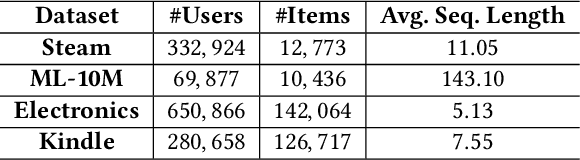
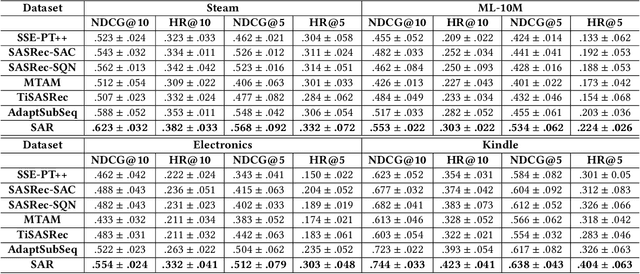
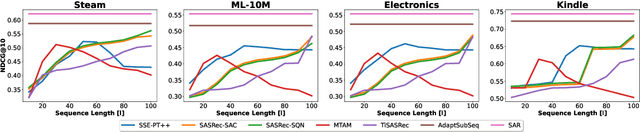
Accounting for the fact that users have different sequential patterns, the main drawback of state-of-the-art recommendation strategies is that a fixed sequence length of user-item interactions is required as input to train the models. This might limit the recommendation accuracy, as in practice users follow different trends on the sequential recommendations. Hence, baseline strategies might ignore important sequential interactions or add noise to the models with redundant interactions, depending on the variety of users' sequential behaviours. To overcome this problem, in this study we propose the SAR model, which not only learns the sequential patterns but also adjusts the sequence length of user-item interactions in a personalized manner. We first design an actor-critic framework, where the RL agent tries to compute the optimal sequence length as an action, given the user's state representation at a certain time step. In addition, we optimize a joint loss function to align the accuracy of the sequential recommendations with the expected cumulative rewards of the critic network, while at the same time we adapt the sequence length with the actor network in a personalized manner. Our experimental evaluation on four real-world datasets demonstrates the superiority of our proposed model over several baseline approaches. Finally, we make our implementation publicly available at https://github.com/stefanosantaris/sar.
A Deep Graph Reinforcement Learning Model for Improving User Experience in Live Video Streaming
Jul 28, 2021



In this paper we present a deep graph reinforcement learning model to predict and improve the user experience during a live video streaming event, orchestrated by an agent/tracker. We first formulate the user experience prediction problem as a classification task, accounting for the fact that most of the viewers at the beginning of an event have poor quality of experience due to low-bandwidth connections and limited interactions with the tracker. In our model we consider different factors that influence the quality of user experience and train the proposed model on diverse state-action transitions when viewers interact with the tracker. In addition, provided that past events have various user experience characteristics we follow a gradient boosting strategy to compute a global model that learns from different events. Our experiments with three real-world datasets of live video streaming events demonstrate the superiority of the proposed model against several baseline strategies. Moreover, as the majority of the viewers at the beginning of an event has poor experience, we show that our model can significantly increase the number of viewers with high quality experience by at least 75% over the first streaming minutes. Our evaluation datasets and implementation are publicly available at https://publicresearch.z13.web.core.windows.net
Multi-Task Learning for User Engagement and Adoption in Live Video Streaming Events
Jun 18, 2021
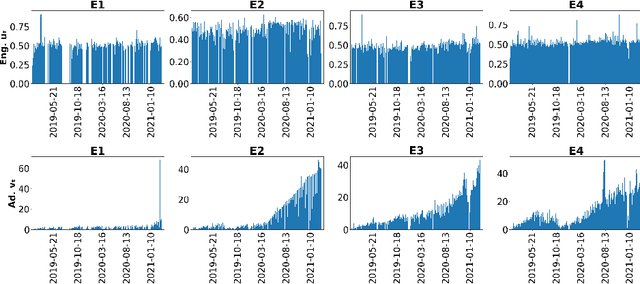
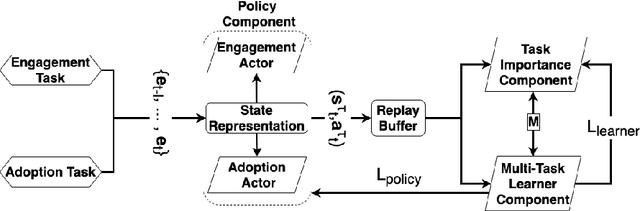
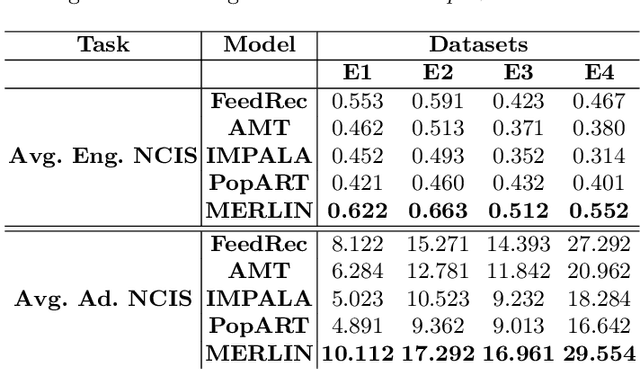
Nowadays, live video streaming events have become a mainstay in viewer's communication in large international enterprises. Provided that viewers are distributed worldwide, the main challenge resides on how to schedule the optimal event's time so as to improve both the viewer's engagement and adoption. In this paper we present a multi-task deep reinforcement learning model to select the time of a live video streaming event, aiming to optimize the viewer's engagement and adoption at the same time. We consider the engagement and adoption of the viewers as independent tasks and formulate a unified loss function to learn a common policy. In addition, we account for the fact that each task might have different contribution to the training strategy of the agent. Therefore, to determine the contribution of each task to the agent's training, we design a Transformer's architecture for the state-action transitions of each task. We evaluate our proposed model on four real-world datasets, generated by the live video streaming events of four large enterprises spanning from January 2019 until March 2021. Our experiments demonstrate the effectiveness of the proposed model when compared with several state-of-the-art strategies. For reproduction purposes, our evaluation datasets and implementation are publicly available at https://github.com/stefanosantaris/merlin.
EGAD: Evolving Graph Representation Learning with Self-Attention and Knowledge Distillation for Live Video Streaming Events
Nov 11, 2020

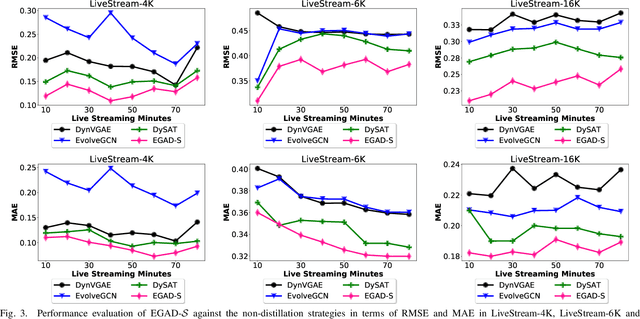
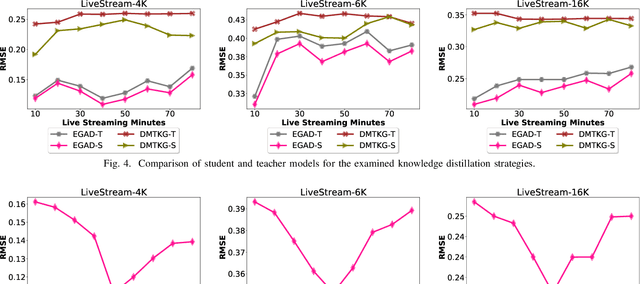
In this study, we present a dynamic graph representation learning model on weighted graphs to accurately predict the network capacity of connections between viewers in a live video streaming event. We propose EGAD, a neural network architecture to capture the graph evolution by introducing a self-attention mechanism on the weights between consecutive graph convolutional networks. In addition, we account for the fact that neural architectures require a huge amount of parameters to train, thus increasing the online inference latency and negatively influencing the user experience in a live video streaming event. To address the problem of the high online inference of a vast number of parameters, we propose a knowledge distillation strategy. In particular, we design a distillation loss function, aiming to first pretrain a teacher model on offline data, and then transfer the knowledge from the teacher to a smaller student model with less parameters. We evaluate our proposed model on the link prediction task on three real-world datasets, generated by live video streaming events. The events lasted 80 minutes and each viewer exploited the distribution solution provided by the company Hive Streaming AB. The experiments demonstrate the effectiveness of the proposed model in terms of link prediction accuracy and number of required parameters, when evaluated against state-of-the-art approaches. In addition, we study the distillation performance of the proposed model in terms of compression ratio for different distillation strategies, where we show that the proposed model can achieve a compression ratio up to 15:100, preserving high link prediction accuracy. For reproduction purposes, our evaluation datasets and implementation are publicly available at https://stefanosantaris.github.io/EGAD.
VStreamDRLS: Dynamic Graph Representation Learning with Self-Attention for Enterprise Distributed Video Streaming Solutions
Nov 11, 2020
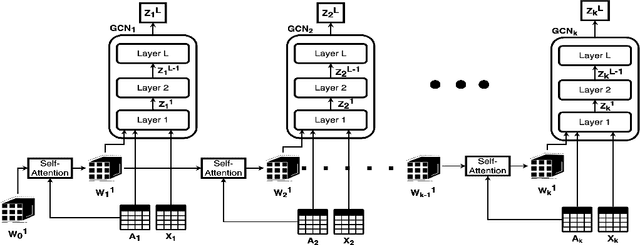


Live video streaming has become a mainstay as a standard communication solution for several enterprises worldwide. To efficiently stream high-quality live video content to a large amount of offices, companies employ distributed video streaming solutions which rely on prior knowledge of the underlying evolving enterprise network. However, such networks are highly complex and dynamic. Hence, to optimally coordinate the live video distribution, the available network capacity between viewers has to be accurately predicted. In this paper we propose a graph representation learning technique on weighted and dynamic graphs to predict the network capacity, that is the weights of connections/links between viewers/nodes. We propose VStreamDRLS, a graph neural network architecture with a self-attention mechanism to capture the evolution of the graph structure of live video streaming events. VStreamDRLS employs the graph convolutional network (GCN) model over the duration of a live video streaming event and introduces a self-attention mechanism to evolve the GCN parameters. In doing so, our model focuses on the GCN weights that are relevant to the evolution of the graph and generate the node representation, accordingly. We evaluate our proposed approach on the link prediction task on two real-world datasets, generated by enterprise live video streaming events. The duration of each event lasted an hour. The experimental results demonstrate the effectiveness of VStreamDRLS when compared with state-of-the-art strategies. Our evaluation datasets and implementation are publicly available at https://github.com/stefanosantaris/vstreamdrls
Distill2Vec: Dynamic Graph Representation Learning with Knowledge Distillation
Nov 11, 2020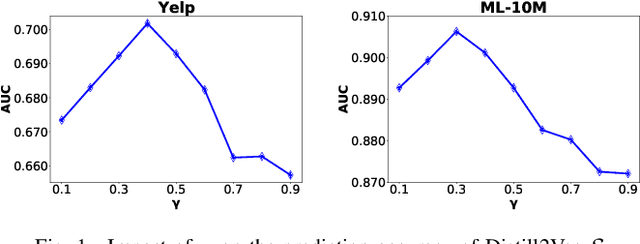
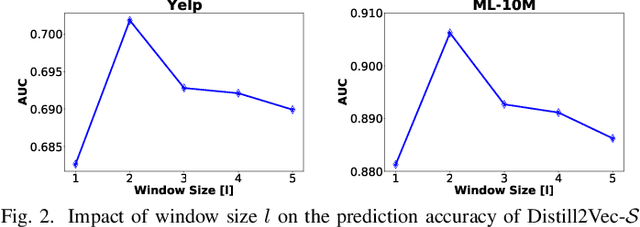


Dynamic graph representation learning strategies are based on different neural architectures to capture the graph evolution over time. However, the underlying neural architectures require a large amount of parameters to train and suffer from high online inference latency, that is several model parameters have to be updated when new data arrive online. In this study we propose Distill2Vec, a knowledge distillation strategy to train a compact model with a low number of trainable parameters, so as to reduce the latency of online inference and maintain the model accuracy high. We design a distillation loss function based on Kullback-Leibler divergence to transfer the acquired knowledge from a teacher model trained on offline data, to a small-size student model for online data. Our experiments with publicly available datasets show the superiority of our proposed model over several state-of-the-art approaches with relative gains up to 5% in the link prediction task. In addition, we demonstrate the effectiveness of our knowledge distillation strategy, in terms of number of required parameters, where Distill2Vec achieves a compression ratio up to 7:100 when compared with baseline approaches. For reproduction purposes, our implementation is publicly available at https://stefanosantaris.github.io/Distill2Vec.
On Estimating the Training Cost of Conversational Recommendation Systems
Nov 10, 2020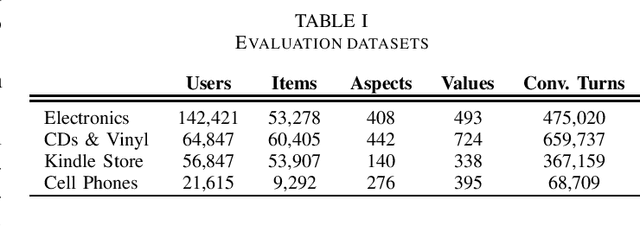

Conversational recommendation systems have recently gain a lot of attention, as users can continuously interact with the system over multiple conversational turns. However, conversational recommendation systems are based on complex neural architectures, thus the training cost of such models is high. To shed light on the high computational training time of state-of-the art conversational models, we examine five representative strategies and demonstrate this issue. Furthermore, we discuss possible ways to cope with the high training cost following knowledge distillation strategies, where we detail the key challenges to reduce the online inference time of the high number of model parameters in conversational recommendation systems