 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Adaptation via Reinforcement Learning in Recommender Systems
Paper and Code

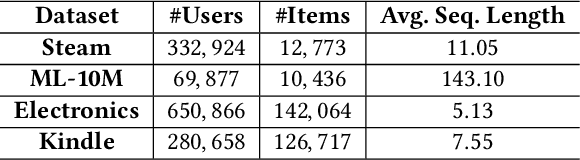
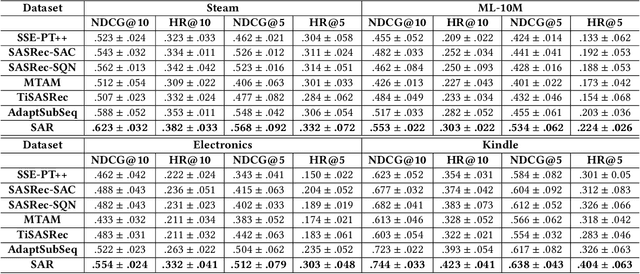
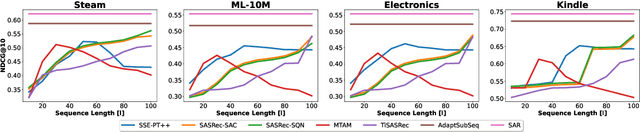
Accounting for the fact that users have different sequential patterns, the main drawback of state-of-the-art recommendation strategies is that a fixed sequence length of user-item interactions is required as input to train the models. This might limit the recommendation accuracy, as in practice users follow different trends on the sequential recommendations. Hence, baseline strategies might ignore important sequential interactions or add noise to the models with redundant interactions, depending on the variety of users' sequential behaviours. To overcome this problem, in this study we propose the SAR model, which not only learns the sequential patterns but also adjusts the sequence length of user-item interactions in a personalized manner. We first design an actor-critic framework, where the RL agent tries to compute the optimal sequence length as an action, given the user's state representation at a certain time step. In addition, we optimize a joint loss function to align the accuracy of the sequential recommendations with the expected cumulative rewards of the critic network, while at the same time we adapt the sequence length with the actor network in a personalized manner. Our experimental evaluation on four real-world datasets demonstrates the superiority of our proposed model over several baseline approaches. Finally, we make our implementation publicly available at https://github.com/stefanosantaris/sar.