 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Federated Learning for Fine-tuning of Large Language Models
Feb 01, 2021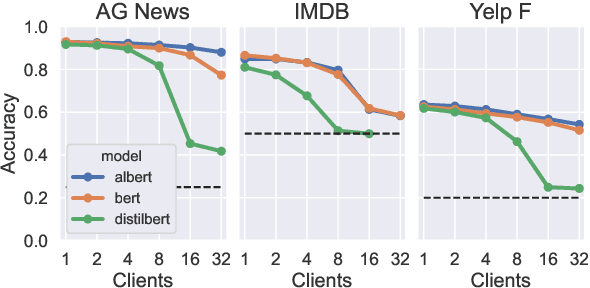
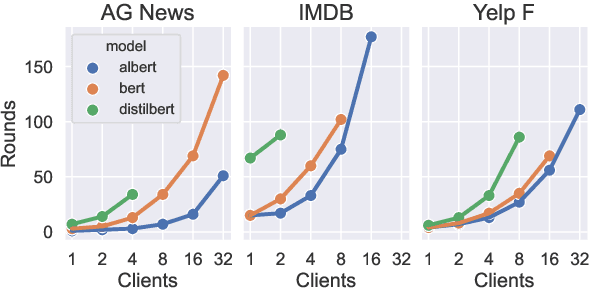
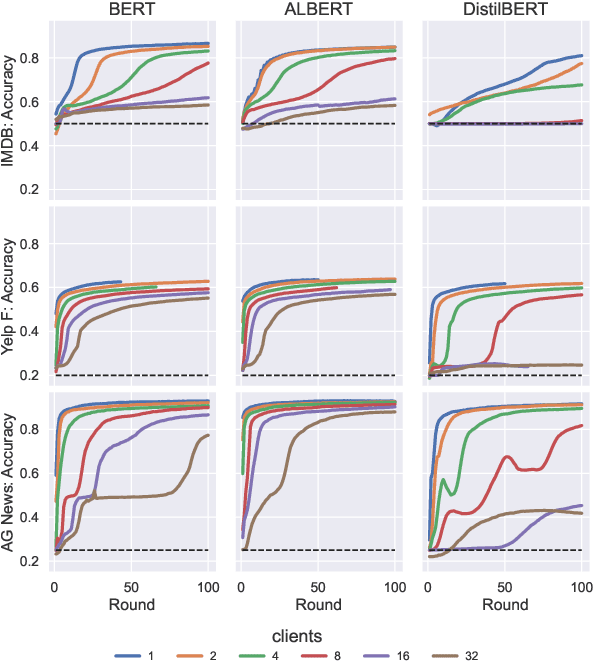
Federated learning (FL) is a promising approach to distributed compute, as well as distributed data, and provides a level of privacy and compliance to legal frameworks. This makes FL attractive for both consumer and healthcare applications. While the area is actively being explored, few studies have examined FL in the context of larger language models and there is a lack of comprehensive reviews of robustness across tasks, architectures, numbers of clients, and other relevant factors. In this paper, we explore the fine-tuning of Transformer-based language models in a federated learning setting. We evaluate three popular BERT-variants of different sizes (BERT, ALBERT, and DistilBERT) on a number of text classification tasks such as sentiment analysis and author identification. We perform an extensive sweep over the number of clients, ranging up to 32, to evaluate the impact of distributed compute on task performance in the federated averaging setting. While our findings suggest that the large sizes of the evaluated models are not generally prohibitive to federated training, we found that the different models handle federated averaging to a varying degree. Most notably, DistilBERT converges significantly slower with larger numbers of clients, and under some circumstances, even collapses to chance level performance. Investigating this issue presents an interesting perspective for future research.
Data Efficient and Weakly Supervised Computational Pathology on Whole Slide Images
May 22, 2020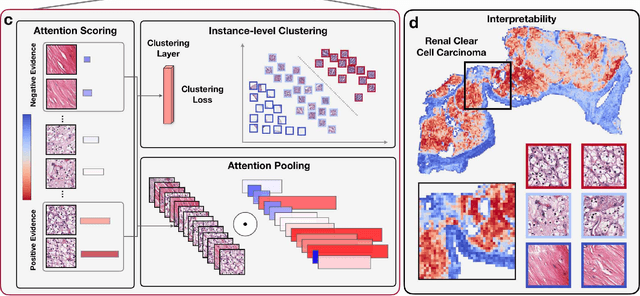
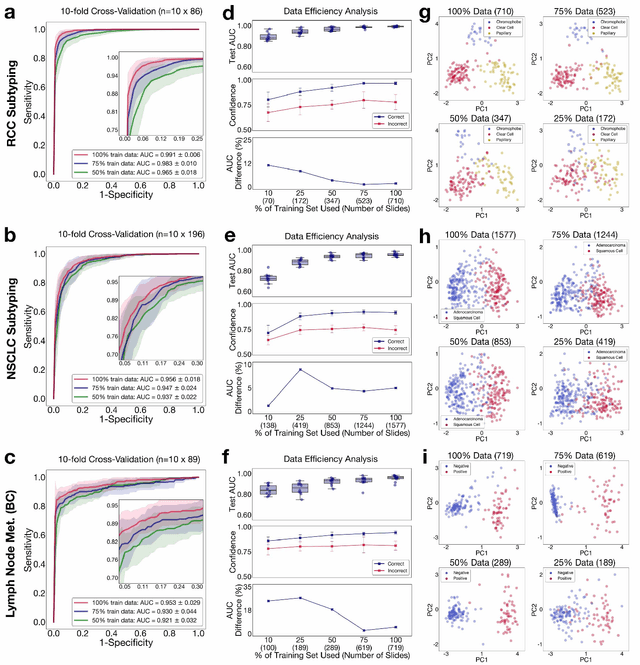
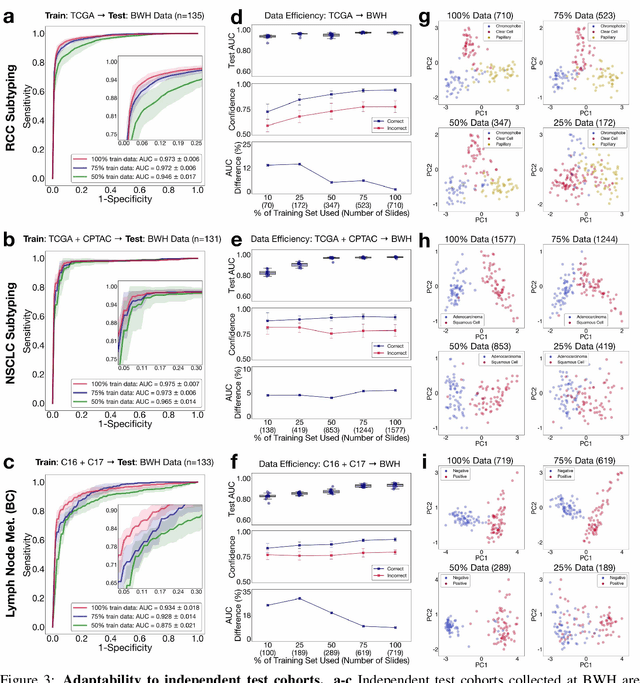
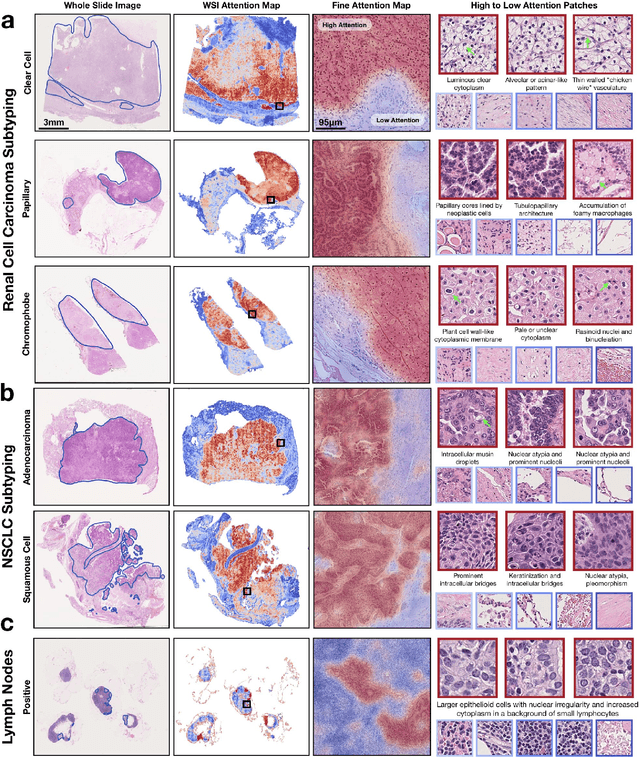
The rapidly emerging field of computational pathology has the potential to enable objective diagnosis, therapeutic response prediction and identification of new morphological features of clinical relevance. However, deep learning-based computational pathology approaches either require manual annotation of gigapixel whole slide images (WSIs) in fully-supervised settings or thousands of WSIs with slide-level labels in a weakly-supervised setting. Moreover, whole slide level computational pathology methods also suffer from domain adaptation and interpretability issues. These challenges have prevented the broad adaptation of computational pathology for clinical and research purposes. Here we present CLAM - Clustering-constrained attention multiple instance learning, an easy-to-use, high-throughput, and interpretable WSI-level processing and learning method that only requires slide-level labels while being data efficient, adaptable and capable of handling multi-class subtyping problems. CLAM is a deep-learning-based weakly-supervised method that uses attention-based learning to automatically identify sub-regions of high diagnostic value in order to accurately classify the whole slide, while also utilizing instance-level clustering over the representative regions identified to constrain and refine the feature space. In three separate analyses, we demonstrate the data efficiency and adaptability of CLAM and its superior performance over standard weakly-supervised classification. We demonstrate that CLAM models are interpretable and can be used to identify well-known and new morphological features. We further show that models trained using CLAM are adaptable to independent test cohorts, cell phone microscopy images, and biopsies. CLAM is a general-purpose and adaptable method that can be used for a variety of different computational pathology tasks in both clinical and research settings.