 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData augmentation instead of explicit regularization
Paper and Code
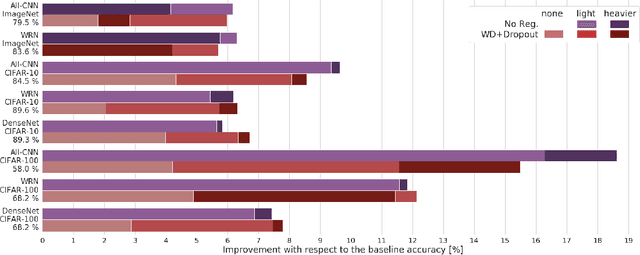
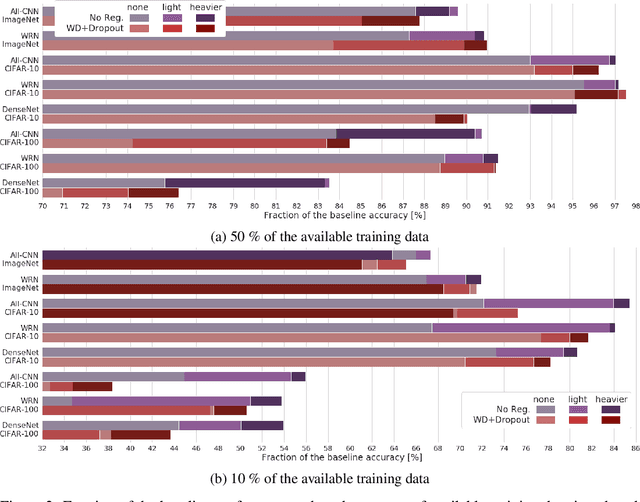
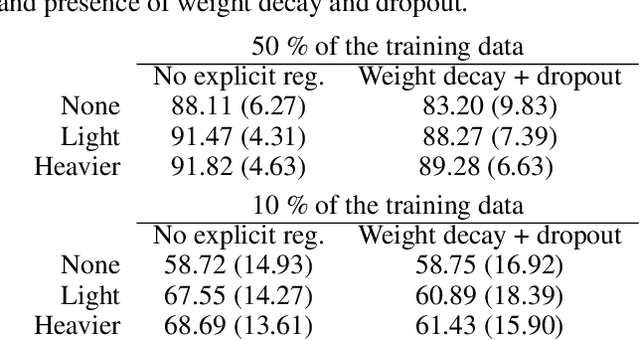
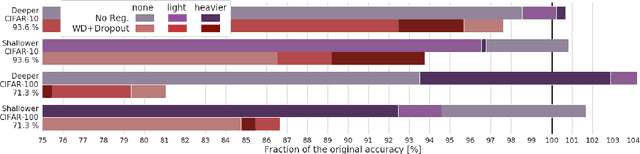
Modern deep artificial neural networks have achieved impressive results through models with very large capacity---compared to the number of training examples---that control overfitting with the help of different forms of regularization. Regularization can be implicit, as is the case of stochastic gradient descent and parameter sharing in convolutional layers, or explicit. Most common explicit regularization techniques, such as weight decay and dropout, reduce the effective capacity of the model and typically require the use of deeper and wider architectures to compensate for the reduced capacity. Although these techniques have been proven successful in terms of improved generalization, they seem to waste capacity. In contrast, data augmentation techniques do not reduce the effective capacity and improve generalization by increasing the number of training examples. In this paper we systematically analyze the effect of data augmentation on some popular architectures and conclude that data augmentation alone---without any other explicit regularization techniques---can achieve the same performance or higher as regularized models, especially when training with fewer examples, and exhibits much higher adaptability to changes in the architecture.