 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization via Ensemble Stacking for Face Presentation Attack Detection
Jan 05, 2023Face presentation attack detection (PAD) plays a pivotal role in securing face recognition systems against spoofing attacks. Although great progress has been made in designing face PAD methods, developing a model that can generalize well to an unseen test domain remains a significant challenge. Moreover, due to different types of spoofing attacks, creating a dataset with a sufficient number of samples for training deep neural networks is a laborious task. This work addresses these challenges by creating synthetic data and introducing a deep learning-based unified framework for improving the generalization ability of the face PAD. In particular, synthetic data is generated by proposing a video distillation technique that blends a spatiotemporal warped image with a still image based on alpha compositing. Since the proposed synthetic samples can be generated by increasing different alpha weights, we train multiple classifiers by taking the advantage of a specific type of ensemble learning known as a stacked ensemble, where each such classifier becomes an expert in its own domain but a non-expert to others. Motivated by this, a meta-classifier is employed to learn from these experts collaboratively so that when developing an ensemble, they can leverage complementary information from each other to better tackle or be more useful for an unseen target domain. Experimental results using half total error rates (HTERs) on four PAD databases CASIA-MFSD (6.97 %), Replay-Attack (33.49%), MSU-MFSD (4.02%), and OULU-NPU (10.91%)) demonstrate the robustness of the method and open up new possibilities for advancing presentation attack detection using ensemble learning with large-scale synthetic data.
Data Expansion using Back Translation and Paraphrasing for Hate Speech Detection
May 25, 2021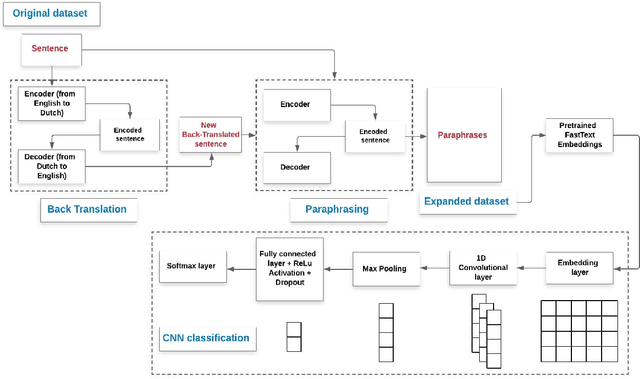
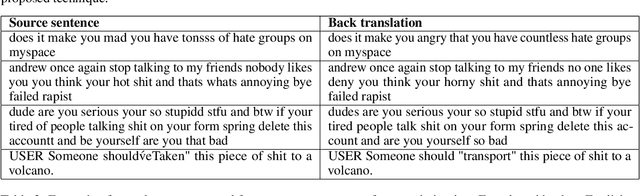
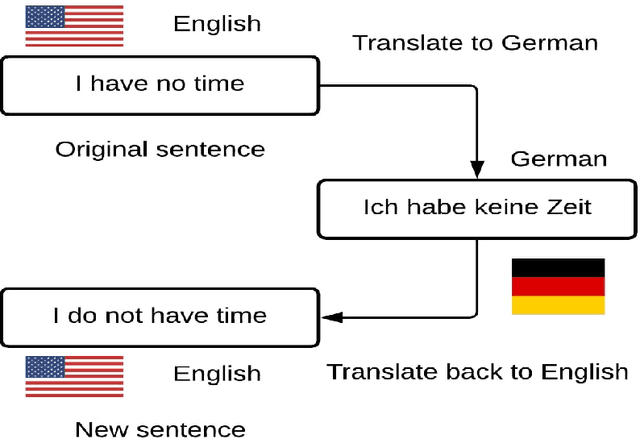
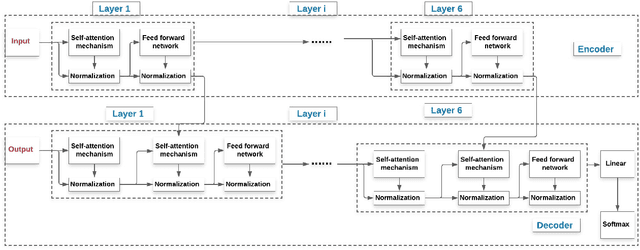
With proliferation of user generated contents in social media platforms, establishing mechanisms to automatically identify toxic and abusive content becomes a prime concern for regulators, researchers, and society. Keeping the balance between freedom of speech and respecting each other dignity is a major concern of social media platform regulators. Although, automatic detection of offensive content using deep learning approaches seems to provide encouraging results, training deep learning-based models requires large amounts of high-quality labeled data, which is often missing. In this regard, we present in this paper a new deep learning-based method that fuses a Back Translation method, and a Paraphrasing technique for data augmentation. Our pipeline investigates different word-embedding-based architectures for classification of hate speech. The back translation technique relies on an encoder-decoder architecture pre-trained on a large corpus and mostly used for machine translation. In addition, paraphrasing exploits the transformer model and the mixture of experts to generate diverse paraphrases. Finally, LSTM, and CNN are compared to seek enhanced classification results. We evaluate our proposal on five publicly available datasets; namely, AskFm corpus, Formspring dataset, Warner and Waseem dataset, Olid, and Wikipedia toxic comments dataset. The performance of the proposal together with comparison to some related state-of-art results demonstrate the effectiveness and soundness of our proposal.