 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study on NLP Data Augmentation for Hate Speech Detection: Legacy Methods, BERT, and LLMs
Mar 30, 2024



The surge of interest in data augmentation within the realm of NLP has been driven by the need to address challenges posed by hate speech domains, the dynamic nature of social media vocabulary, and the demands for large-scale neural networks requiring extensive training data. However, the prevalent use of lexical substitution in data augmentation has raised concerns, as it may inadvertently alter the intended meaning, thereby impacting the efficacy of supervised machine learning models. In pursuit of suitable data augmentation methods, this study explores both established legacy approaches and contemporary practices such as Large Language Models (LLM), including GPT in Hate Speech detection. Additionally, we propose an optimized utilization of BERT-based encoder models with contextual cosine similarity filtration, exposing significant limitations in prior synonym substitution methods. Our comparative analysis encompasses five popular augmentation techniques: WordNet and Fast-Text synonym replacement, Back-translation, BERT-mask contextual augmentation, and LLM. Our analysis across five benchmarked datasets revealed that while traditional methods like back-translation show low label alteration rates (0.3-1.5%), and BERT-based contextual synonym replacement offers sentence diversity but at the cost of higher label alteration rates (over 6%). Our proposed BERT-based contextual cosine similarity filtration markedly reduced label alteration to just 0.05%, demonstrating its efficacy in 0.7% higher F1 performance. However, augmenting data with GPT-3 not only avoided overfitting with up to sevenfold data increase but also improved embedding space coverage by 15% and classification F1 score by 1.4% over traditional methods, and by 0.8% over our method.
Data Expansion using Back Translation and Paraphrasing for Hate Speech Detection
May 25, 2021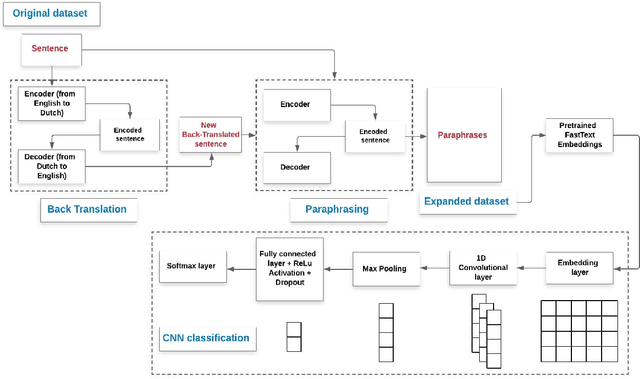
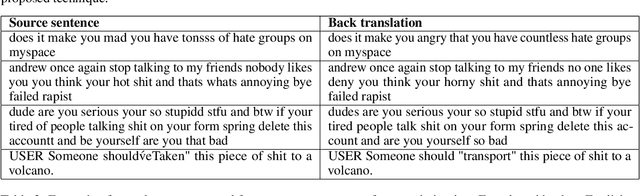
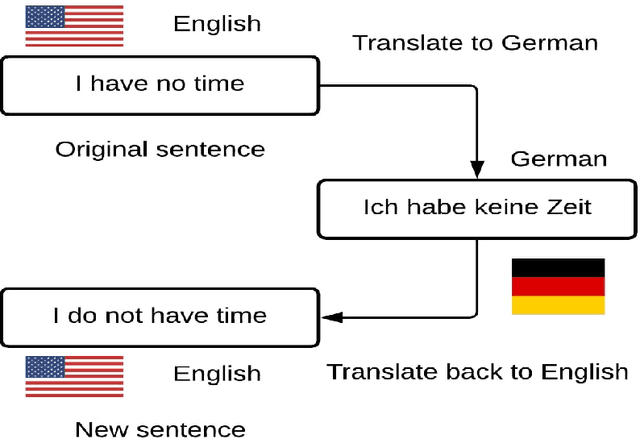
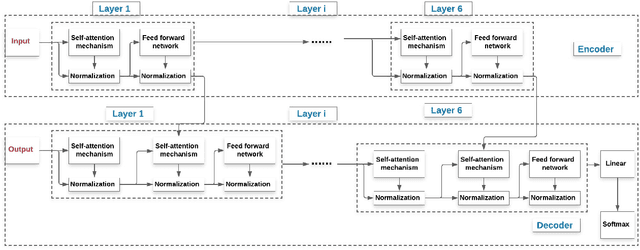
With proliferation of user generated contents in social media platforms, establishing mechanisms to automatically identify toxic and abusive content becomes a prime concern for regulators, researchers, and society. Keeping the balance between freedom of speech and respecting each other dignity is a major concern of social media platform regulators. Although, automatic detection of offensive content using deep learning approaches seems to provide encouraging results, training deep learning-based models requires large amounts of high-quality labeled data, which is often missing. In this regard, we present in this paper a new deep learning-based method that fuses a Back Translation method, and a Paraphrasing technique for data augmentation. Our pipeline investigates different word-embedding-based architectures for classification of hate speech. The back translation technique relies on an encoder-decoder architecture pre-trained on a large corpus and mostly used for machine translation. In addition, paraphrasing exploits the transformer model and the mixture of experts to generate diverse paraphrases. Finally, LSTM, and CNN are compared to seek enhanced classification results. We evaluate our proposal on five publicly available datasets; namely, AskFm corpus, Formspring dataset, Warner and Waseem dataset, Olid, and Wikipedia toxic comments dataset. The performance of the proposal together with comparison to some related state-of-art results demonstrate the effectiveness and soundness of our proposal.
A systematic review of Hate Speech automatic detection using Natural Language Processing
May 22, 2021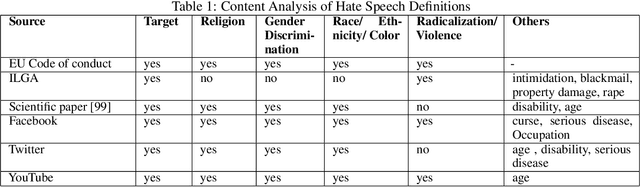
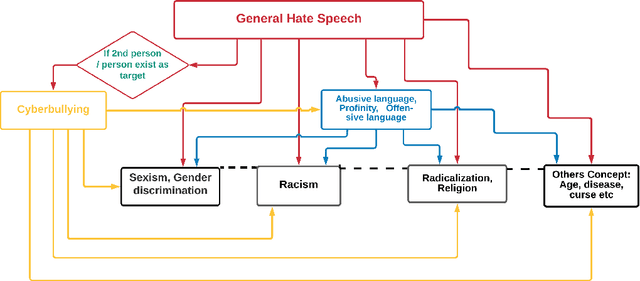
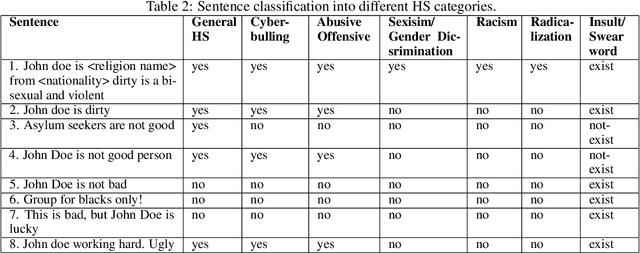
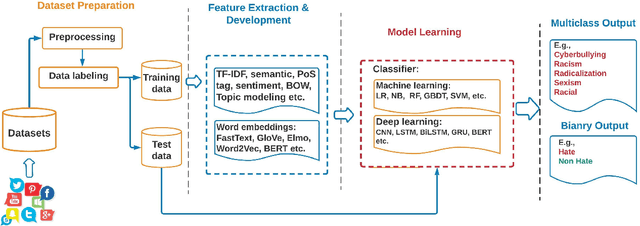
With the multiplication of social media platforms, which offer anonymity, easy access and online community formation, and online debate, the issue of hate speech detection and tracking becomes a growing challenge to society, individual, policy-makers and researchers. Despite efforts for leveraging automatic techniques for automatic detection and monitoring, their performances are still far from satisfactory, which constantly calls for future research on the issue. This paper provides a systematic review of literature in this field, with a focus on natural language processing and deep learning technologies, highlighting the terminology, processing pipeline, core methods employed, with a focal point on deep learning architecture. From a methodological perspective, we adopt PRISMA guideline of systematic review of the last 10 years literature from ACM Digital Library and Google Scholar. In the sequel, existing surveys, limitations, and future research directions are extensively discussed.