 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDziriBERT: a Pre-trained Language Model for the Algerian Dialect
Sep 25, 2021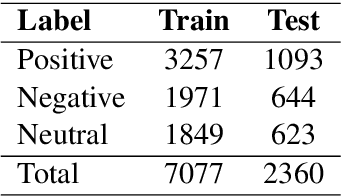
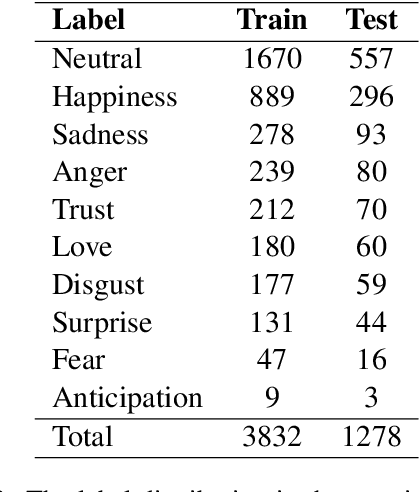
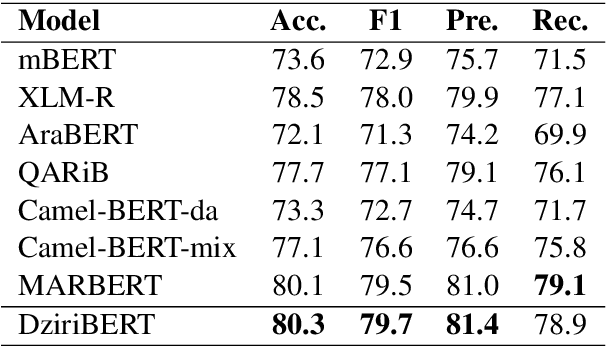
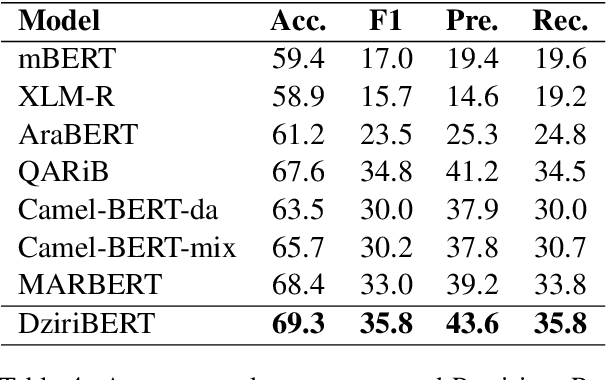
Pre-trained transformers are now the de facto models in Natural Language Processing given their state-of-the-art results in many tasks and languages. However, most of the current models have been trained on languages for which large text resources are already available (such as English, French, Arabic, etc.). Therefore, there is still a number of low-resource languages that need more attention from the community. In this paper, we study the Algerian dialect which has several specificities that make the use of Arabic or multilingual models inappropriate. To address this issue, we collected more than one Million Algerian tweets, and pre-trained the first Algerian language model: DziriBERT. When compared to existing models, DziriBERT achieves the best results on two Algerian downstream datasets. The obtained results show that pre-training a dedicated model on a small dataset (150 MB) can outperform existing models that have been trained on much more data (hundreds of GB). Finally, our model is publicly available to the community.