 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDROID: Dual Representation for Out-of-Scope Intent Detection
Oct 15, 2025Detecting out-of-scope (OOS) user utterances remains a key challenge in task-oriented dialogue systems and, more broadly, in open-set intent recognition. Existing approaches often depend on strong distributional assumptions or auxiliary calibration modules. We present DROID (Dual Representation for Out-of-Scope Intent Detection), a compact end-to-end framework that combines two complementary encoders -- the Universal Sentence Encoder (USE) for broad semantic generalization and a domain-adapted Transformer-based Denoising Autoencoder (TSDAE) for domain-specific contextual distinctions. Their fused representations are processed by a lightweight branched classifier with a single calibrated threshold that separates in-domain and OOS intents without post-hoc scoring. To enhance boundary learning under limited supervision, DROID incorporates both synthetic and open-domain outlier augmentation. Despite using only 1.5M trainable parameters, DROID consistently outperforms recent state-of-the-art baselines across multiple intent benchmarks, achieving macro-F1 improvements of 6--15% for known and 8--20% for OOS intents, with the most significant gains in low-resource settings. These results demonstrate that dual-encoder representations with simple calibration can yield robust, scalable, and reliable OOS detection for neural dialogue systems.
Improved Out-of-Scope Intent Classification with Dual Encoding and Threshold-based Re-Classification
May 31, 2024



Detecting out-of-scope user utterances is essential for task-oriented dialogues and intent classification. Current methodologies face difficulties with the unpredictable distribution of outliers and often rely on assumptions about data distributions. We present the Dual Encoder for Threshold-Based Re-Classification (DETER) to address these challenges. This end-to-end framework efficiently detects out-of-scope intents without requiring assumptions on data distributions or additional post-processing steps. The core of DETER utilizes dual text encoders, the Universal Sentence Encoder (USE) and the Transformer-based Denoising AutoEncoder (TSDAE), to generate user utterance embeddings, which are classified through a branched neural architecture. Further, DETER generates synthetic outliers using self-supervision and incorporates out-of-scope phrases from open-domain datasets. This approach ensures a comprehensive training set for out-of-scope detection. Additionally, a threshold-based re-classification mechanism refines the model's initial predictions. Evaluations on the CLINC-150, Stackoverflow, and Banking77 datasets demonstrate DETER's efficacy. Our model outperforms previous benchmarks, increasing up to 13% and 5% in F1 score for known and unknown intents on CLINC-150 and Stackoverflow, and 16% for known and 24% % for unknown intents on Banking77. The source code has been released at https://github.com/Hossam-Mohammed-tech/Intent_Classification_OOS.
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
May 04, 2024Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
Aligned Weight Regularizers for Pruning Pretrained Neural Networks
Apr 05, 2022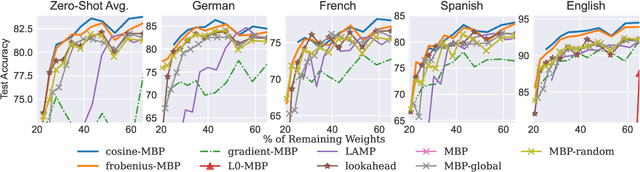


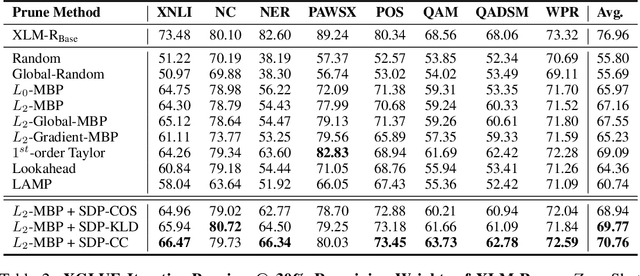
While various avenues of research have been explored for iterative pruning, little is known what effect pruning has on zero-shot test performance and its potential implications on the choice of pruning criteria. This pruning setup is particularly important for cross-lingual models that implicitly learn alignment between language representations during pretraining, which if distorted via pruning, not only leads to poorer performance on language data used for retraining but also on zero-shot languages that are evaluated. In this work, we show that there is a clear performance discrepancy in magnitude-based pruning when comparing standard supervised learning to the zero-shot setting. From this finding, we propose two weight regularizers that aim to maximize the alignment between units of pruned and unpruned networks to mitigate alignment distortion in pruned cross-lingual models and perform well for both non zero-shot and zero-shot settings. We provide experimental results on cross-lingual tasks for the zero-shot setting using XLM-RoBERTa$_{\mathrm{Base}}$, where we also find that pruning has varying degrees of representational degradation depending on the language corresponding to the zero-shot test set. This is also the first study that focuses on cross-lingual language model compression.
Deep Neural Compression Via Concurrent Pruning and Self-Distillation
Sep 30, 2021


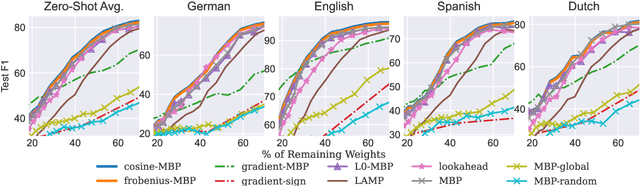
Pruning aims to reduce the number of parameters while maintaining performance close to the original network. This work proposes a novel \emph{self-distillation} based pruning strategy, whereby the representational similarity between the pruned and unpruned versions of the same network is maximized. Unlike previous approaches that treat distillation and pruning separately, we use distillation to inform the pruning criteria, without requiring a separate student network as in knowledge distillation. We show that the proposed {\em cross-correlation objective for self-distilled pruning} implicitly encourages sparse solutions, naturally complementing magnitude-based pruning criteria. Experiments on the GLUE and XGLUE benchmarks show that self-distilled pruning increases mono- and cross-lingual language model performance. Self-distilled pruned models also outperform smaller Transformers with an equal number of parameters and are competitive against (6 times) larger distilled networks. We also observe that self-distillation (1) maximizes class separability, (2) increases the signal-to-noise ratio, and (3) converges faster after pruning steps, providing further insights into why self-distilled pruning improves generalization.
Sequence-to-Sequence Learning on Keywords for Efficient FAQ Retrieval
Aug 23, 2021
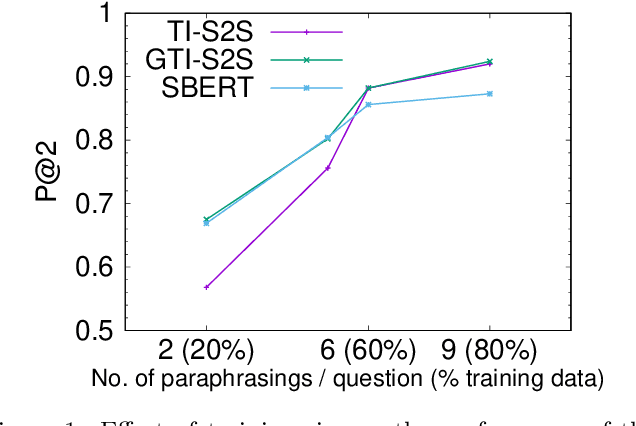
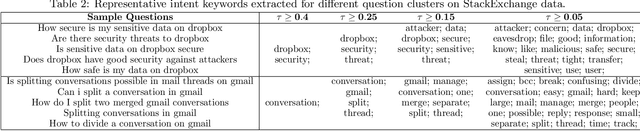
Frequently-Asked-Question (FAQ) retrieval provides an effective procedure for responding to user's natural language based queries. Such platforms are becoming common in enterprise chatbots, product question answering, and preliminary technical support for customers. However, the challenge in such scenarios lies in bridging the lexical and semantic gap between varied query formulations and the corresponding answers, both of which typically have a very short span. This paper proposes TI-S2S, a novel learning framework combining TF-IDF based keyword extraction and Word2Vec embeddings for training a Sequence-to-Sequence (Seq2Seq) architecture. It achieves high precision for FAQ retrieval by better understanding the underlying intent of a user question captured via the representative keywords. We further propose a variant with an additional neural network module for guiding retrieval via relevant candidate identification based on similarity features. Experiments on publicly available dataset depict our approaches to provide around 92% precision-at-rank-5, exhibiting nearly 13% improvement over existing approaches.
* 6 pages
Unsupervised Word Translation Pairing using Refinement based Point Set Registration
Nov 26, 2020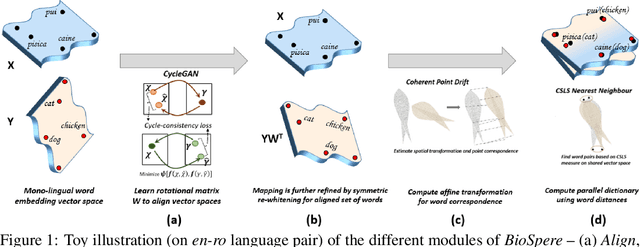
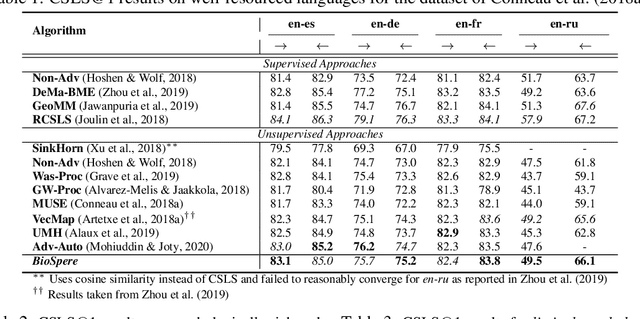

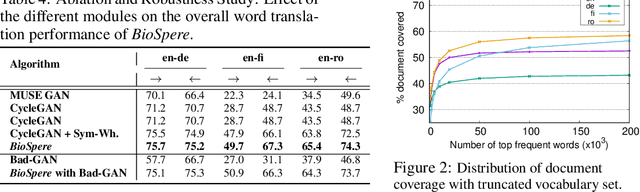
Cross-lingual alignment of word embeddings play an important role in knowledge transfer across languages, for improving machine translation and other multi-lingual applications. Current unsupervised approaches rely on similarities in geometric structure of word embedding spaces across languages, to learn structure-preserving linear transformations using adversarial networks and refinement strategies. However, such techniques, in practice, tend to suffer from instability and convergence issues, requiring tedious fine-tuning for precise parameter setting. This paper proposes BioSpere, a novel framework for unsupervised mapping of bi-lingual word embeddings onto a shared vector space, by combining adversarial initialization and refinement procedure with point set registration algorithm used in image processing. We show that our framework alleviates the shortcomings of existing methodologies, and is relatively invariant to variable adversarial learning performance, depicting robustness in terms of parameter choices and training losses. Experimental evaluation on parallel dictionary induction task demonstrates state-of-the-art results for our framework on diverse language pairs.