 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Word Translation Pairing using Refinement based Point Set Registration
Nov 26, 2020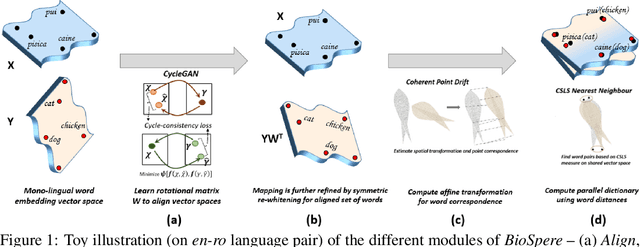
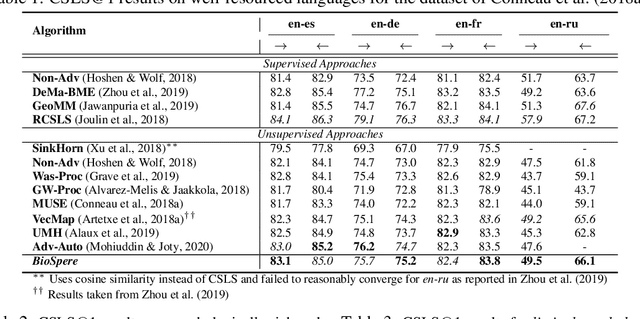

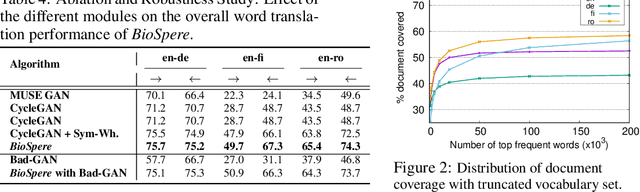
Cross-lingual alignment of word embeddings play an important role in knowledge transfer across languages, for improving machine translation and other multi-lingual applications. Current unsupervised approaches rely on similarities in geometric structure of word embedding spaces across languages, to learn structure-preserving linear transformations using adversarial networks and refinement strategies. However, such techniques, in practice, tend to suffer from instability and convergence issues, requiring tedious fine-tuning for precise parameter setting. This paper proposes BioSpere, a novel framework for unsupervised mapping of bi-lingual word embeddings onto a shared vector space, by combining adversarial initialization and refinement procedure with point set registration algorithm used in image processing. We show that our framework alleviates the shortcomings of existing methodologies, and is relatively invariant to variable adversarial learning performance, depicting robustness in terms of parameter choices and training losses. Experimental evaluation on parallel dictionary induction task demonstrates state-of-the-art results for our framework on diverse language pairs.
iSarcasm: A Dataset of Intended Sarcasm
Nov 08, 2019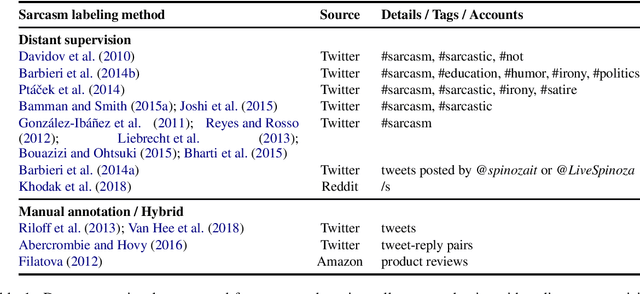


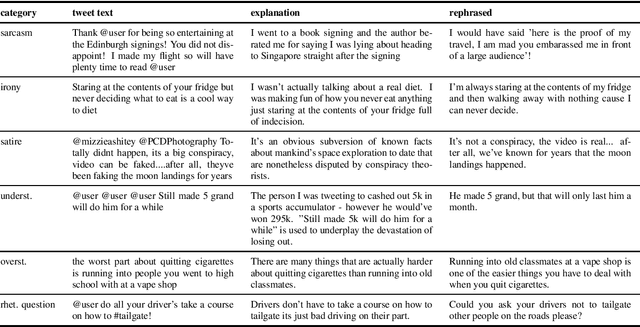
This paper considers the distinction between intended and perceived sarcasm in the context of textual sarcasm detection. The former occurs when an utterance is sarcastic from the perspective of its author, while the latter occurs when the utterance is interpreted as sarcastic by the audience. We show the limitations of previous labelling methods in capturing intended sarcasm and introduce the iSarcasm dataset of tweets labeled for sarcasm directly by their authors. We experiment with sarcasm detection models on our dataset. The low performance indicates that sarcasm might be a phenomenon under-studied computationally thus far.
Exploring Author Context for Detecting Intended vs Perceived Sarcasm
Oct 25, 2019
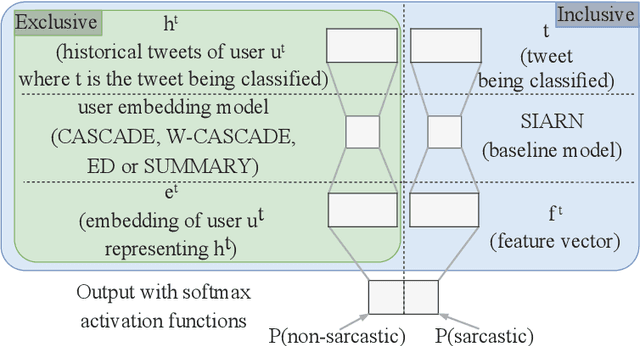
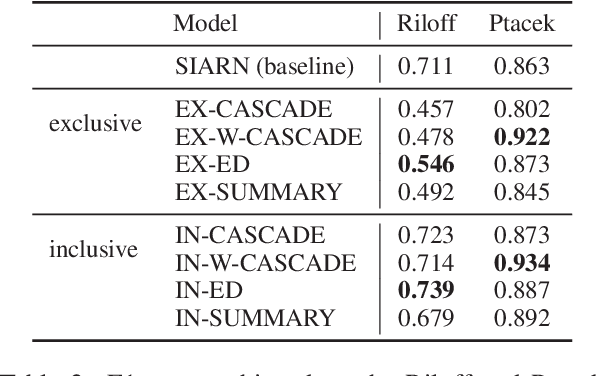
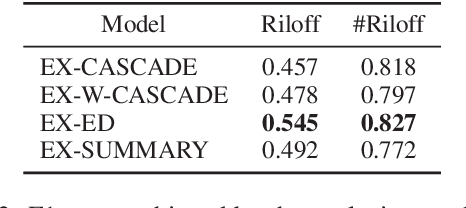
We investigate the impact of using author context on textual sarcasm detection. We define author context as the embedded representation of their historical posts on Twitter and suggest neural models that extract these representations. We experiment with two tweet datasets, one labelled manually for sarcasm, and the other via tag-based distant supervision. We achieve state-of-the-art performance on the second dataset, but not on the one labelled manually, indicating a difference between intended sarcasm, captured by distant supervision, and perceived sarcasm, captured by manual labelling.
* 6 pages, 1 figure, ACL 2020
Flood Detection On Low Cost Orbital Hardware
Oct 14, 2019


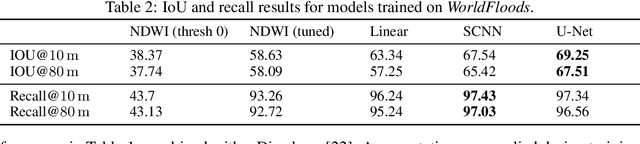
Satellite imaging is a critical technology for monitoring and responding to natural disasters such as flooding. Despite the capabilities of modern satellites, there is still much to be desired from the perspective of first response organisations like UNICEF. Two main challenges are rapid access to data, and the ability to automatically identify flooded regions in images. We describe a prototypical flood segmentation system, identifying cloud, water and land, that could be deployed on a constellation of small satellites, performing processing on board to reduce downlink bandwidth by 2 orders of magnitude. We target PhiSat-1, part of the FSSCAT mission, which is planned to be launched by the European Space Agency (ESA) near the start of 2020 as a proof of concept for this new technology.