 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit
Dec 10, 2025Analyzing large-scale text corpora is a core challenge in machine learning, crucial for tasks like identifying undesirable model behaviors or biases in training data. Current methods often rely on costly LLM-based techniques (e.g. annotating dataset differences) or dense embedding models (e.g. for clustering), which lack control over the properties of interest. We propose using sparse autoencoders (SAEs) to create SAE embeddings: representations whose dimensions map to interpretable concepts. Through four data analysis tasks, we show that SAE embeddings are more cost-effective and reliable than LLMs and more controllable than dense embeddings. Using the large hypothesis space of SAEs, we can uncover insights such as (1) semantic differences between datasets and (2) unexpected concept correlations in documents. For instance, by comparing model responses, we find that Grok-4 clarifies ambiguities more often than nine other frontier models. Relative to LLMs, SAE embeddings uncover bigger differences at 2-8x lower cost and identify biases more reliably. Additionally, SAE embeddings are controllable: by filtering concepts, we can (3) cluster documents along axes of interest and (4) outperform dense embeddings on property-based retrieval. Using SAE embeddings, we study model behavior with two case studies: investigating how OpenAI model behavior has changed over time and finding "trigger" phrases learned by Tulu-3 (Lambert et al., 2024) from its training data. These results position SAEs as a versatile tool for unstructured data analysis and highlight the neglected importance of interpreting models through their data.
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Aug 09, 2024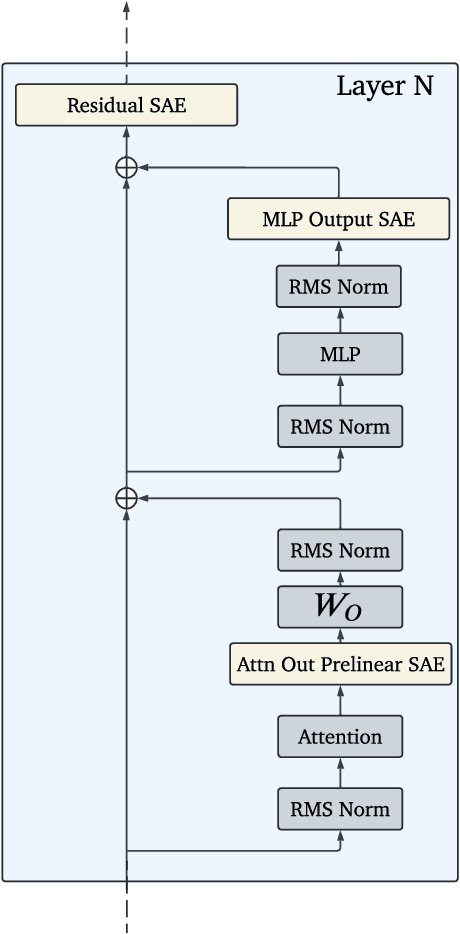
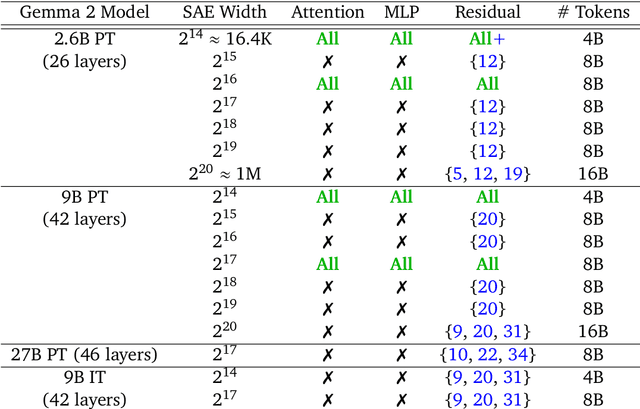
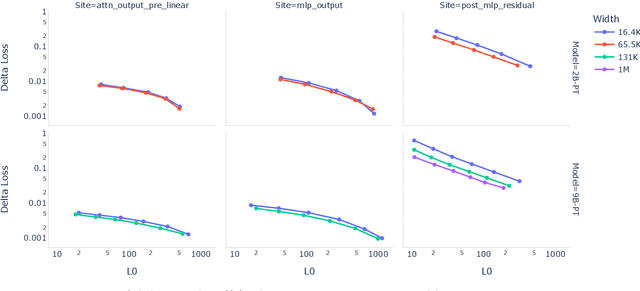
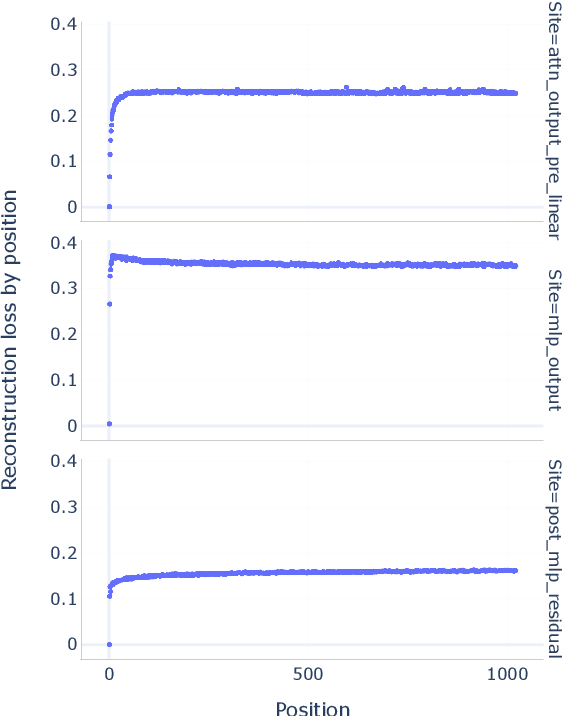
Sparse autoencoders (SAEs) are an unsupervised method for learning a sparse decomposition of a neural network's latent representations into seemingly interpretable features. Despite recent excitement about their potential, research applications outside of industry are limited by the high cost of training a comprehensive suite of SAEs. In this work, we introduce Gemma Scope, an open suite of JumpReLU SAEs trained on all layers and sub-layers of Gemma 2 2B and 9B and select layers of Gemma 2 27B base models. We primarily train SAEs on the Gemma 2 pre-trained models, but additionally release SAEs trained on instruction-tuned Gemma 2 9B for comparison. We evaluate the quality of each SAE on standard metrics and release these results. We hope that by releasing these SAE weights, we can help make more ambitious safety and interpretability research easier for the community. Weights and a tutorial can be found at https://huggingface.co/google/gemma-scope and an interactive demo can be found at https://www.neuronpedia.org/gemma-scope
Improving Dictionary Learning with Gated Sparse Autoencoders
Apr 30, 2024



Recent work has found that sparse autoencoders (SAEs) are an effective technique for unsupervised discovery of interpretable features in language models' (LMs) activations, by finding sparse, linear reconstructions of LM activations. We introduce the Gated Sparse Autoencoder (Gated SAE), which achieves a Pareto improvement over training with prevailing methods. In SAEs, the L1 penalty used to encourage sparsity introduces many undesirable biases, such as shrinkage -- systematic underestimation of feature activations. The key insight of Gated SAEs is to separate the functionality of (a) determining which directions to use and (b) estimating the magnitudes of those directions: this enables us to apply the L1 penalty only to the former, limiting the scope of undesirable side effects. Through training SAEs on LMs of up to 7B parameters we find that, in typical hyper-parameter ranges, Gated SAEs solve shrinkage, are similarly interpretable, and require half as many firing features to achieve comparable reconstruction fidelity.
Quantifying Uncertainty for Machine Learning Based Diagnostic
Jul 29, 2021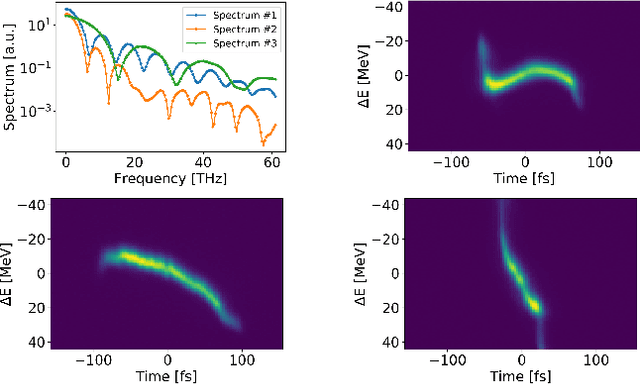
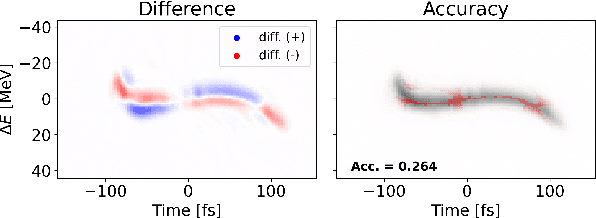
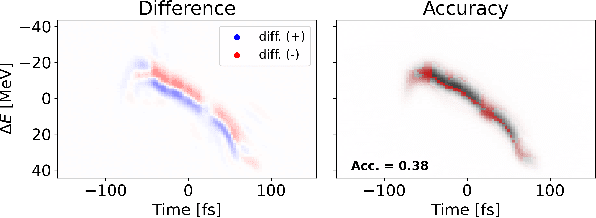
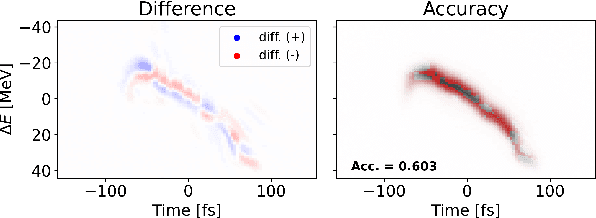
Virtual Diagnostic (VD) is a deep learning tool that can be used to predict a diagnostic output. VDs are especially useful in systems where measuring the output is invasive, limited, costly or runs the risk of damaging the output. Given a prediction, it is necessary to relay how reliable that prediction is. This is known as 'uncertainty quantification' of a prediction. In this paper, we use ensemble methods and quantile regression neural networks to explore different ways of creating and analyzing prediction's uncertainty on experimental data from the Linac Coherent Light Source at SLAC. We aim to accurately and confidently predict the current profile or longitudinal phase space images of the electron beam. The ability to make informed decisions under uncertainty is crucial for reliable deployment of deep learning tools on safety-critical systems as particle accelerators.
Can convolutional ResNets approximately preserve input distances? A frequency analysis perspective
Jun 17, 2021

ResNets constrained to be bi-Lipschitz, that is, approximately distance preserving, have been a crucial component of recently proposed techniques for deterministic uncertainty quantification in neural models. We show that theoretical justifications for recent regularisation schemes trying to enforce such a constraint suffer from a crucial flaw -- the theoretical link between the regularisation scheme used and bi-Lipschitzness is only valid under conditions which do not hold in practice, rendering existing theory of limited use, despite the strong empirical performance of these models. We provide a theoretical explanation for the effectiveness of these regularisation schemes using a frequency analysis perspective, showing that under mild conditions these schemes will enforce a lower Lipschitz bound on the low-frequency projection of images. We then provide empirical evidence supporting our theoretical claims, and perform further experiments which demonstrate that our broader conclusions appear to hold when some of the mathematical assumptions of our proof are relaxed, corresponding to the setup used in prior work. In addition, we present a simple constructive algorithm to search for counter examples to the distance preservation condition, and discuss possible implications of our theory for future model design.
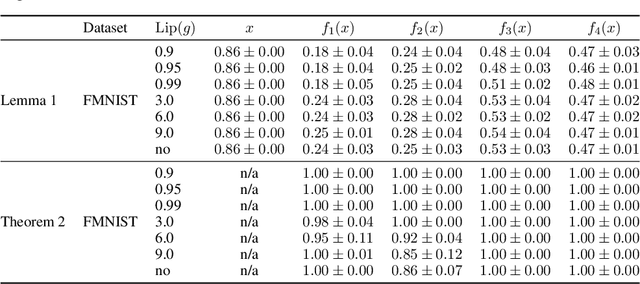
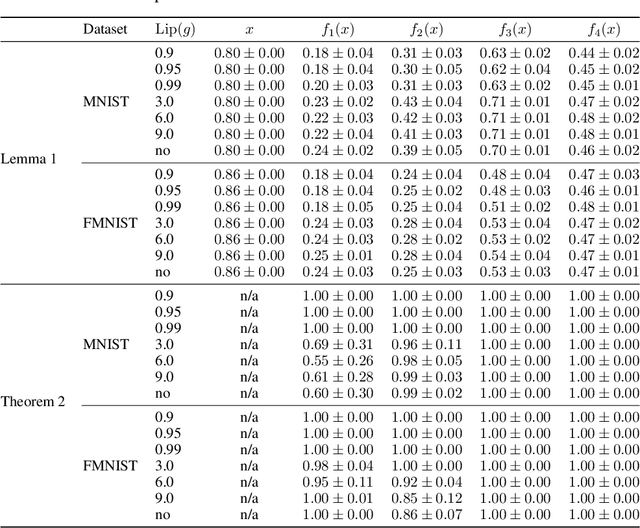
Improving Deterministic Uncertainty Estimation in Deep Learning for Classification and Regression
Feb 22, 2021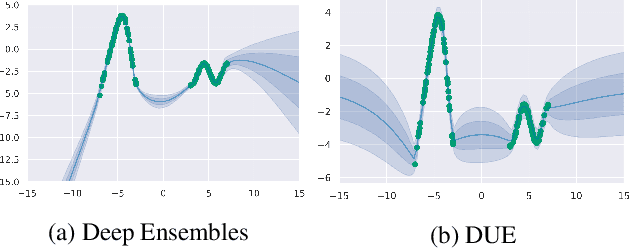

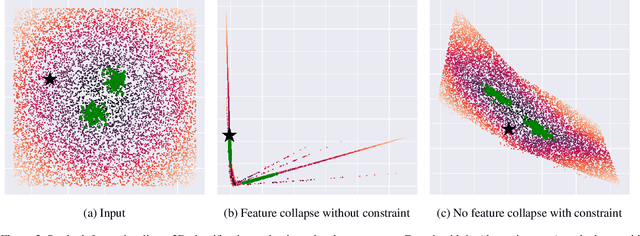
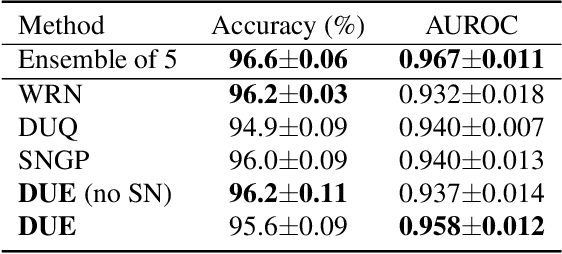
We propose a new model that estimates uncertainty in a single forward pass and works on both classification and regression problems. Our approach combines a bi-Lipschitz feature extractor with an inducing point approximate Gaussian process, offering robust and principled uncertainty estimation. This can be seen as a refinement of Deep Kernel Learning (DKL), with our changes allowing DKL to match softmax neural networks accuracy. Our method overcomes the limitations of previous work addressing deterministic uncertainty quantification, such as the dependence of uncertainty on ad hoc hyper-parameters. Our method matches SotA accuracy, 96.2% on CIFAR-10, while maintaining the speed of softmax models, and provides uncertainty estimates that outperform previous single forward pass uncertainty models. Finally, we demonstrate our method on a recently introduced benchmark for uncertainty in regression: treatment deferral in causal models for personalized medicine.
Semi-supervised Learning of Galaxy Morphology using Equivariant Transformer Variational Autoencoders
Nov 17, 2020
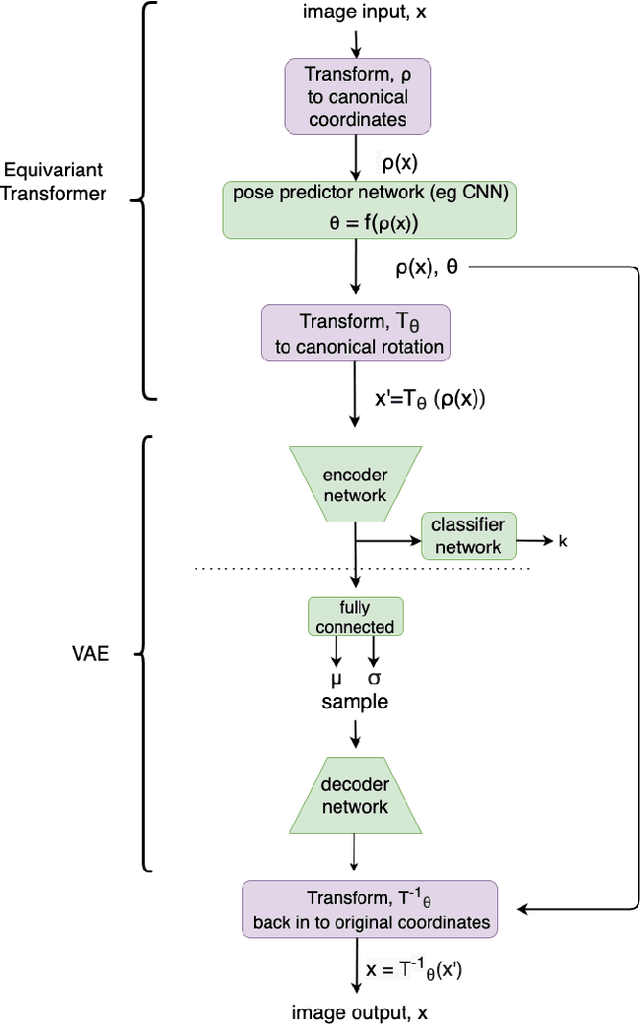
The growth in the number of galaxy images is much faster than the speed at which these galaxies can be labelled by humans. However, by leveraging the information present in the ever growing set of unlabelled images, semi-supervised learning could be an effective way of reducing the required labelling and increasing classification accuracy. We develop a Variational Autoencoder (VAE) with Equivariant Transformer layers with a classifier network from the latent space. We show that this novel architecture leads to improvements in accuracy when used for the galaxy morphology classification task on the Galaxy Zoo data set. In addition we show that pre-training the classifier network as part of the VAE using the unlabelled data leads to higher accuracy with fewer labels compared to exiting approaches. This novel VAE has the potential to automate galaxy morphology classification with reduced human labelling efforts.
Capsule Networks -- A Probabilistic Perspective
Apr 07, 2020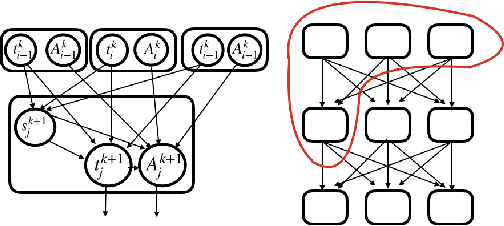
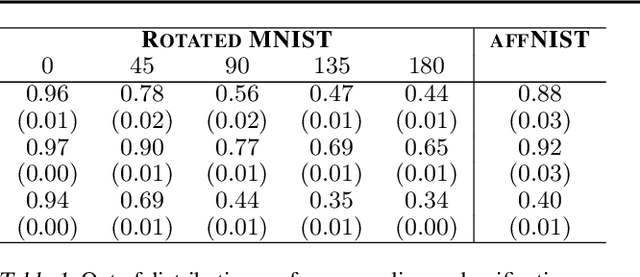
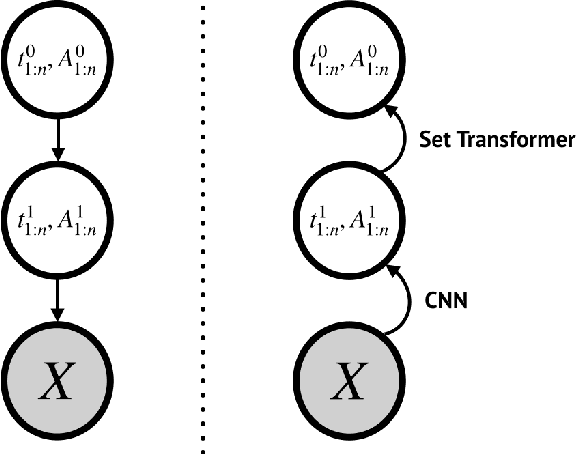
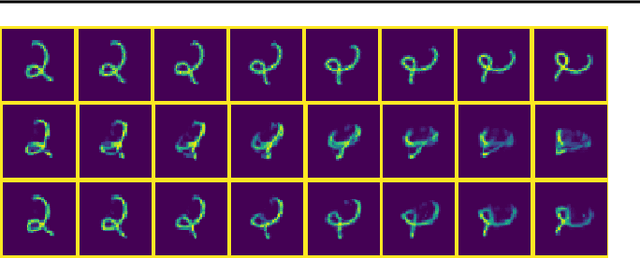
'Capsule' models try to explicitly represent the poses of objects, enforcing a linear relationship between an object's pose and that of its constituent parts. This modelling assumption should lead to robustness to viewpoint changes since the sub-object/super-object relationships are invariant to the poses of the object. We describe a probabilistic generative model which encodes such capsule assumptions, clearly separating the generative parts of the model from the inference mechanisms. With a variational bound we explore the properties of the generative model independently of the approximate inference scheme, and gain insights into failures of the capsule assumptions and inference amortisation. We experimentally demonstrate the applicability of our unified objective, and demonstrate the use of test time optimisation to solve problems inherent to amortised inference in our model.
Simple and Scalable Epistemic Uncertainty Estimation Using a Single Deep Deterministic Neural Network
Mar 04, 2020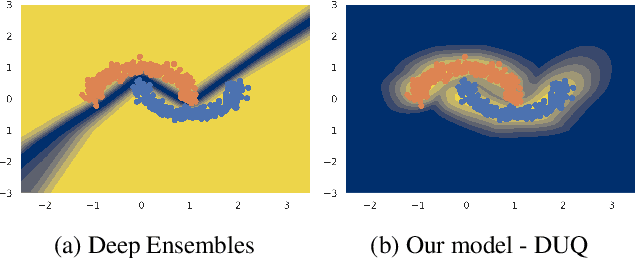

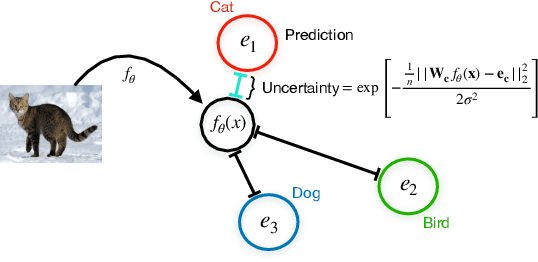

We propose a method for training a deterministic deep model that can find and reject out of distribution data points at test time with a single forward pass. Our approach, deterministic uncertainty quantification (DUQ), builds upon ideas of RBF networks. We scale training in these with a novel loss function and centroid updating scheme. By enforcing detectability of changes in the input using a gradient penalty, we are able to reliably detect out of distribution data. Our uncertainty quantification scales well to large datasets, and using a single model, we improve upon or match Deep Ensembles on notable difficult dataset pairs such as FashionMNIST vs. MNIST, and CIFAR-10 vs. SVHN, while maintaining competitive accuracy.
Try Depth Instead of Weight Correlations: Mean-field is a Less Restrictive Assumption for Deeper Networks
Feb 10, 2020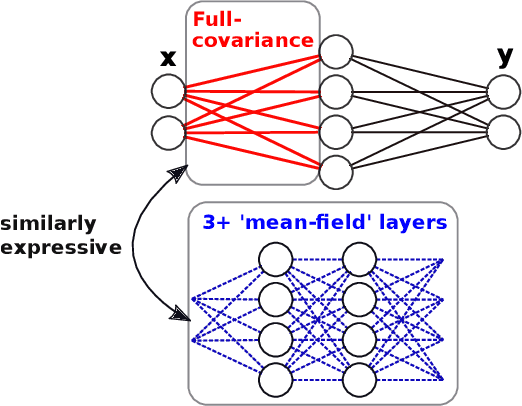
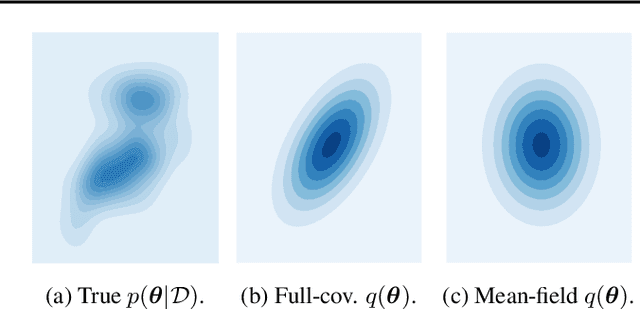
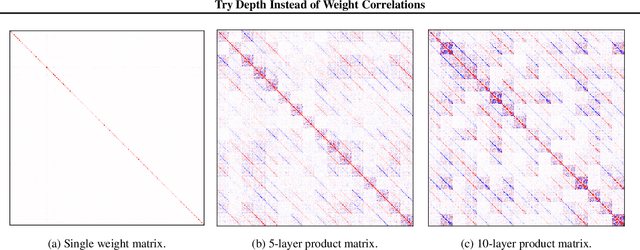
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive. We argue mathematically that full-covariance approximations only improve the ELBO if they improve the expected log-likelihood. We further show that deeper mean-field networks are able to express predictive distributions approximately equivalent to shallower full-covariance networks. We validate these observations empirically, demonstrating that deeper models decrease the divergence between diagonal- and full-covariance Gaussian fits to the true posterior.