Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTry Depth Instead of Weight Correlations: Mean-field is a Less Restrictive Assumption for Deeper Networks
Paper and Code
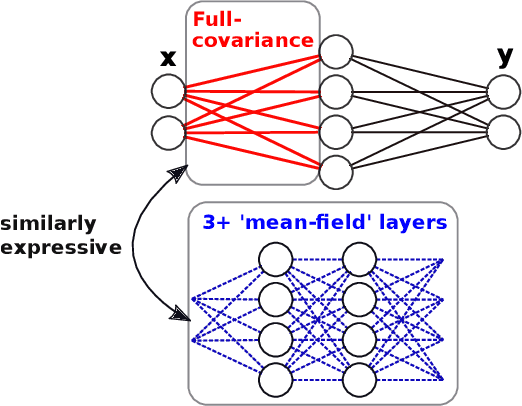
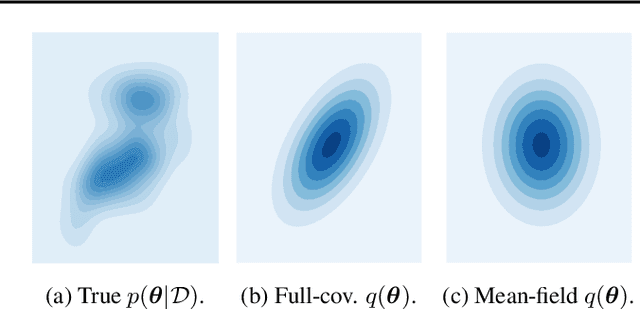
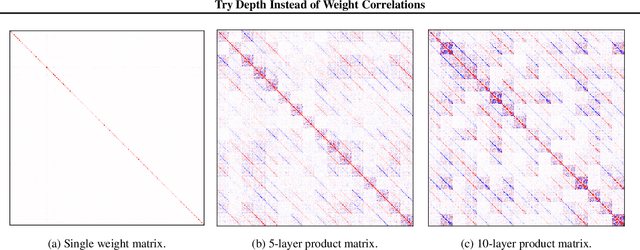
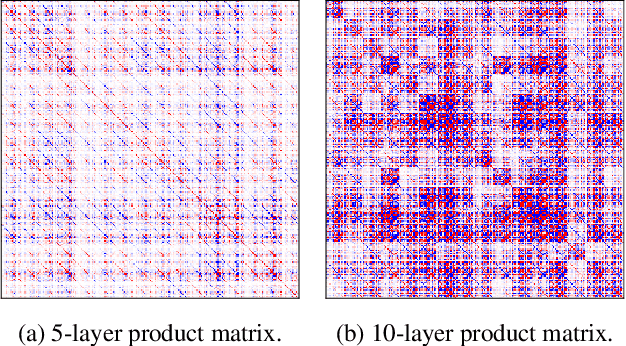
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive. We argue mathematically that full-covariance approximations only improve the ELBO if they improve the expected log-likelihood. We further show that deeper mean-field networks are able to express predictive distributions approximately equivalent to shallower full-covariance networks. We validate these observations empirically, demonstrating that deeper models decrease the divergence between diagonal- and full-covariance Gaussian fits to the true posterior.
View paper on