 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Paper and Code
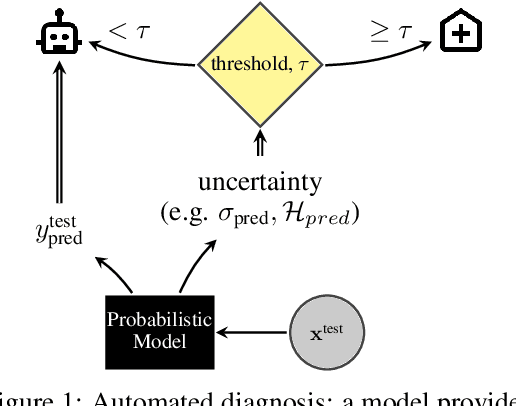
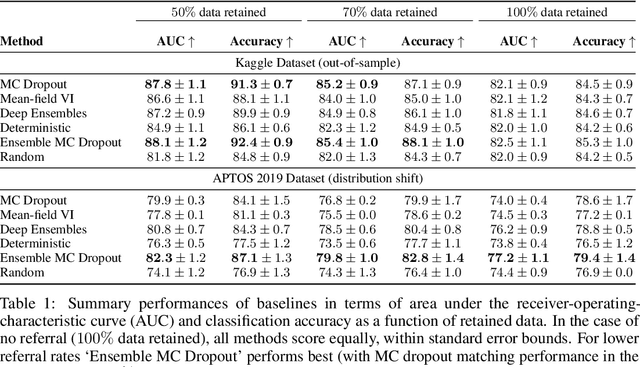
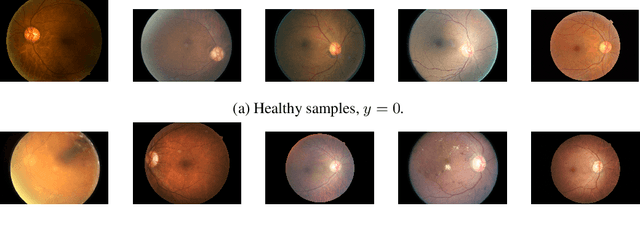
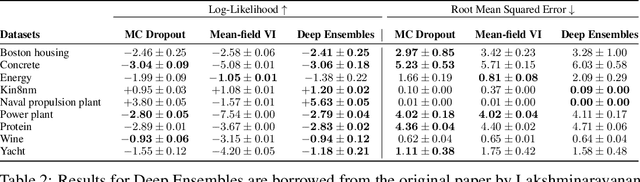
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give `better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on \emph{diabetic retinopathy diagnosis}. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-domain to reflect real-world use of model uncertainty in automated diagnosis. We develop multiple tasks that fall under this application, including out-of-distribution detection and robustness to distribution shift. We then perform a systematic comparison of well-tuned BDL techniques on the various tasks. From our comparison we conclude that some current techniques which solve benchmarks such as UCI `overfit' their uncertainty to the dataset---when evaluated on our benchmark these underperform in comparison to simpler baselines. The code for the benchmark, its baselines, and a simple API for evaluating new BDL tools are made available at https://github.com/oatml/bdl-benchmarks.