 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDA-UGC: Detailed Image Quality Analysis via Visual Distortion Assessment for UGC Images
Aug 18, 2025Recent advances in Multimodal Large Language Models (MLLMs) have introduced a paradigm shift for Image Quality Assessment (IQA) from unexplainable image quality scoring to explainable IQA, demonstrating practical applications like quality control and optimization guidance. However, current explainable IQA methods not only inadequately use the same distortion criteria to evaluate both User-Generated Content (UGC) and AI-Generated Content (AIGC) images, but also lack detailed quality analysis for monitoring image quality and guiding image restoration. In this study, we establish the first large-scale Visual Distortion Assessment Instruction Tuning Dataset for UGC images, termed ViDA-UGC, which comprises 11K images with fine-grained quality grounding, detailed quality perception, and reasoning quality description data. This dataset is constructed through a distortion-oriented pipeline, which involves human subject annotation and a Chain-of-Thought (CoT) assessment framework. This framework guides GPT-4o to generate quality descriptions by identifying and analyzing UGC distortions, which helps capturing rich low-level visual features that inherently correlate with distortion patterns. Moreover, we carefully select 476 images with corresponding 6,149 question answer pairs from ViDA-UGC and invite a professional team to ensure the accuracy and quality of GPT-generated information. The selected and revised data further contribute to the first UGC distortion assessment benchmark, termed ViDA-UGC-Bench. Experimental results demonstrate the effectiveness of the ViDA-UGC and CoT framework for consistently enhancing various image quality analysis abilities across multiple base MLLMs on ViDA-UGC-Bench and Q-Bench, even surpassing GPT-4o.
Small Object Few-shot Segmentation for Vision-based Industrial Inspection
Jul 31, 2024



Vision-based industrial inspection (VII) aims to locate defects quickly and accurately. Supervised learning under a close-set setting and industrial anomaly detection, as two common paradigms in VII, face different problems in practical applications. The former is that various and sufficient defects are difficult to obtain, while the latter is that specific defects cannot be located. To solve these problems, in this paper, we focus on the few-shot semantic segmentation (FSS) method, which can locate unseen defects conditioned on a few annotations without retraining. Compared to common objects in natural images, the defects in VII are small. This brings two problems to current FSS methods: 1 distortion of target semantics and 2 many false positives for backgrounds. To alleviate these problems, we propose a small object few-shot segmentation (SOFS) model. The key idea for alleviating 1 is to avoid the resizing of the original image and correctly indicate the intensity of target semantics. SOFS achieves this idea via the non-resizing procedure and the prototype intensity downsampling of support annotations. To alleviate 2, we design an abnormal prior map in SOFS to guide the model to reduce false positives and propose a mixed normal Dice loss to preferentially prevent the model from predicting false positives. SOFS can achieve FSS and few-shot anomaly detection determined by support masks. Diverse experiments substantiate the superior performance of SOFS. Code is available at https://github.com/zhangzilongc/SOFS.
UniDoorManip: Learning Universal Door Manipulation Policy Over Large-scale and Diverse Door Manipulation Environments
Mar 12, 2024Learning a universal manipulation policy encompassing doors with diverse categories, geometries and mechanisms, is crucial for future embodied agents to effectively work in complex and broad real-world scenarios. Due to the limited datasets and unrealistic simulation environments, previous works fail to achieve good performance across various doors. In this work, we build a novel door manipulation environment reflecting different realistic door manipulation mechanisms, and further equip this environment with a large-scale door dataset covering 6 door categories with hundreds of door bodies and handles, making up thousands of different door instances. Additionally, to better emulate real-world scenarios, we introduce a mobile robot as the agent and use the partial and occluded point cloud as the observation, which are not considered in previous works while possessing significance for real-world implementations. To learn a universal policy over diverse doors, we propose a novel framework disentangling the whole manipulation process into three stages, and integrating them by training in the reversed order of inference. Extensive experiments validate the effectiveness of our designs and demonstrate our framework's strong performance. Code, data and videos are avaible on https://unidoormanip.github.io/.
CA2: Class-Agnostic Adaptive Feature Adaptation for One-class Classification
Sep 04, 2023



One-class classification (OCC), i.e., identifying whether an example belongs to the same distribution as the training data, is essential for deploying machine learning models in the real world. Adapting the pre-trained features on the target dataset has proven to be a promising paradigm for improving OCC performance. Existing methods are constrained by assumptions about the number of classes. This contradicts the real scenario where the number of classes is unknown. In this work, we propose a simple class-agnostic adaptive feature adaptation method (CA2). We generalize the center-based method to unknown classes and optimize this objective based on the prior existing in the pre-trained network, i.e., pre-trained features that belong to the same class are adjacent. CA2 is validated to consistently improve OCC performance across a spectrum of training data classes, spanning from 1 to 1024, outperforming current state-of-the-art methods. Code is available at https://github.com/zhangzilongc/CA2.
R-Mixup: Riemannian Mixup for Biological Networks
Jun 05, 2023



Biological networks are commonly used in biomedical and healthcare domains to effectively model the structure of complex biological systems with interactions linking biological entities. However, due to their characteristics of high dimensionality and low sample size, directly applying deep learning models on biological networks usually faces severe overfitting. In this work, we propose R-MIXUP, a Mixup-based data augmentation technique that suits the symmetric positive definite (SPD) property of adjacency matrices from biological networks with optimized training efficiency. The interpolation process in R-MIXUP leverages the log-Euclidean distance metrics from the Riemannian manifold, effectively addressing the swelling effect and arbitrarily incorrect label issues of vanilla Mixup. We demonstrate the effectiveness of R-MIXUP with five real-world biological network datasets on both regression and classification tasks. Besides, we derive a commonly ignored necessary condition for identifying the SPD matrices of biological networks and empirically study its influence on the model performance. The code implementation can be found in Appendix E.
Industrial Anomaly Detection with Domain Shift: A Real-world Dataset and Masked Multi-scale Reconstruction
Apr 05, 2023



Industrial anomaly detection (IAD) is crucial for automating industrial quality inspection. The diversity of the datasets is the foundation for developing comprehensive IAD algorithms. Existing IAD datasets focus on the diversity of data categories, overlooking the diversity of domains within the same data category. In this paper, to bridge this gap, we propose the Aero-engine Blade Anomaly Detection (AeBAD) dataset, consisting of two sub-datasets: the single-blade dataset and the video anomaly detection dataset of blades. Compared to existing datasets, AeBAD has the following two characteristics: 1.) The target samples are not aligned and at different scales. 2.) There is a domain shift between the distribution of normal samples in the test set and the training set, where the domain shifts are mainly caused by the changes in illumination and view. Based on this dataset, we observe that current state-of-the-art (SOTA) IAD methods exhibit limitations when the domain of normal samples in the test set undergoes a shift. To address this issue, we propose a novel method called masked multi-scale reconstruction (MMR), which enhances the model's capacity to deduce causality among patches in normal samples by a masked reconstruction task. MMR achieves superior performance compared to SOTA methods on the AeBAD dataset. Furthermore, MMR achieves competitive performance with SOTA methods to detect the anomalies of different types on the MVTec AD dataset. Code and dataset are available at https://github.com/zhangzilongc/MMR.
Brain Network Transformer
Oct 15, 2022

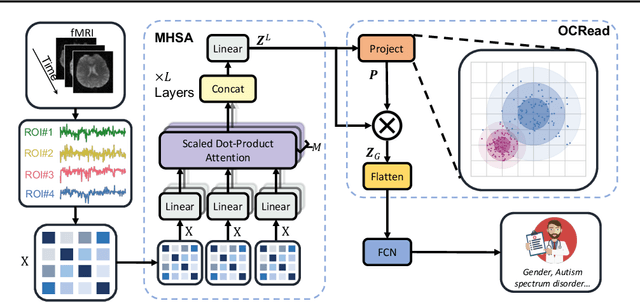
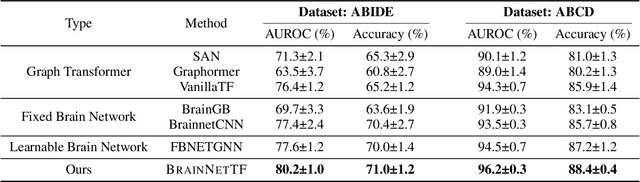
Human brains are commonly modeled as networks of Regions of Interest (ROIs) and their connections for the understanding of brain functions and mental disorders. Recently, Transformer-based models have been studied over different types of data, including graphs, shown to bring performance gains widely. In this work, we study Transformer-based models for brain network analysis. Driven by the unique properties of data, we model brain networks as graphs with nodes of fixed size and order, which allows us to (1) use connection profiles as node features to provide natural and low-cost positional information and (2) learn pair-wise connection strengths among ROIs with efficient attention weights across individuals that are predictive towards downstream analysis tasks. Moreover, we propose an Orthonormal Clustering Readout operation based on self-supervised soft clustering and orthonormal projection. This design accounts for the underlying functional modules that determine similar behaviors among groups of ROIs, leading to distinguishable cluster-aware node embeddings and informative graph embeddings. Finally, we re-standardize the evaluation pipeline on the only one publicly available large-scale brain network dataset of ABIDE, to enable meaningful comparison of different models. Experiment results show clear improvements of our proposed Brain Network Transformer on both the public ABIDE and our restricted ABCD datasets. The implementation is available at https://github.com/Wayfear/BrainNetworkTransformer.