 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Cheetah: A Novel Quadrupedal Robot with a 3-DOF Active Spine Learning Agile Locomotion
May 27, 2026The biological spine of quadrupeds enables sagittal flexion/extension, lateral bending, and axial rotation, playing a crucial role in highly agile and dexterous locomotion. While numerous studies have integrated active spinal joints into quadrupedal robots to enhance agility, most designs simplify control complexity by reducing spinal degrees of freedom (DOF), failing to achieve the spatial tri-axial rotation characteristic of biological spines. Consequently, replicating a multi-DOF biomimetic spine and effectively leveraging it to empower the agile locomotion of quadrupedal robots remains a significant research challenge. In this study, we present S-Cheetah, a quadrupedal robot featuring a 3-DOF bio-inspired serial active spine capable of biomimetic spatial tri-axial rotation. To empower the robot to fully utilize this active spine, we developed a specialized reinforcement learning framework to actively promote the engagement of the introduced spine and maximize the robot's locomotive capabilities by integrating an acceleration curriculum learning strategy with tailored reward functions, such as a gallop gait reward, a spine undulation reward, and a spine steering reward. Experimental results demonstrate that S-Cheetah can achieve a peak speed of 6.9 m/s using the rotary G2 gallop gait and an in-place turning rate of 7.2 rad/s. Besides, the system exhibits an emergent, feline-inspired aerial self-righting capability, allowing it to land stably on four feet from arbitrary orientations during free fall. Finally, through extensive evaluations across diverse locomotion tasks, we prove that the introduction of the proposed 3-DOF spine comprehensively enhances the locomotive agility of quadrupedal robots. Project website: himmy-robotics.github.io/scheetah
TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
May 25, 2026Sparse-view 3D reconstruction is increasingly addressed with feed-forward splatting networks that predict explicit primitives directly from images. Yet most existing methods remain centered on Gaussian primitives and expose surfaces only indirectly: extracting a usable mesh for downstream simulation, physics reasoning, or embodied interaction still requires expensive post-hoc steps that break the feed-forward promise. This limitation is especially pronounced in pose-free settings, where scene structure and camera parameters must be estimated jointly from sparse observations. We present TriSplat, a feed-forward reconstruction network that represents scenes with oriented triangle primitives and directly exports simulation-ready mesh scenes from a single forward pass. Given input images, the network predicts local 3D point maps, triangle attributes, camera poses, and optional intrinsics. Rather than regressing triangle orientation as an unconstrained latent variable, our approach constructs geometry normals from the predicted point maps, refines them with an image-conditioned normal head, and converts them into stable local frames for triangle parameterization. A mono-normal bootstrap schedule further stabilizes early training, while opacity and blur scheduling progressively sharpens the learned surface representation for direct mesh extraction. Experiments on RealEstate10K and DL3DV show that this representation produces more geometry-faithful reconstructions than Gaussian feed-forward baselines while maintaining competitive novel-view rendering quality. Because the rendering primitives are themselves surface triangles, the output can be directly ingested by physics engines, collision detectors, and standard rendering pipelines without any conversion, making it a practical simulation-ready solution for feed-forward 3D scene reconstruction.
Depth3DLane: Monocular 3D Lane Detection via Depth Prior Distillation
Apr 25, 2025



Monocular 3D lane detection is challenging due to the difficulty in capturing depth information from single-camera images. A common strategy involves transforming front-view (FV) images into bird's-eye-view (BEV) space through inverse perspective mapping (IPM), facilitating lane detection using BEV features. However, IPM's flat-ground assumption and loss of contextual information lead to inaccuracies in reconstructing 3D information, especially height. In this paper, we introduce a BEV-based framework to address these limitations and improve 3D lane detection accuracy. Our approach incorporates a Hierarchical Depth-Aware Head that provides multi-scale depth features, mitigating the flat-ground assumption by enhancing spatial awareness across varying depths. Additionally, we leverage Depth Prior Distillation to transfer semantic depth knowledge from a teacher model, capturing richer structural and contextual information for complex lane structures. To further refine lane continuity and ensure smooth lane reconstruction, we introduce a Conditional Random Field module that enforces spatial coherence in lane predictions. Extensive experiments validate that our method achieves state-of-the-art performance in terms of z-axis error and outperforms other methods in the field in overall performance. The code is released at: https://anonymous.4open.science/r/Depth3DLane-DCDD.
Technical Report: The Graph Spectral Token -- Enhancing Graph Transformers with Spectral Information
Apr 08, 2024Graph Transformers have emerged as a powerful alternative to Message-Passing Graph Neural Networks (MP-GNNs) to address limitations such as over-squashing of information exchange. However, incorporating graph inductive bias into transformer architectures remains a significant challenge. In this report, we propose the Graph Spectral Token, a novel approach to directly encode graph spectral information, which captures the global structure of the graph, into the transformer architecture. By parameterizing the auxiliary [CLS] token and leaving other tokens representing graph nodes, our method seamlessly integrates spectral information into the learning process. We benchmark the effectiveness of our approach by enhancing two existing graph transformers, GraphTrans and SubFormer. The improved GraphTrans, dubbed GraphTrans-Spec, achieves over 10% improvements on large graph benchmark datasets while maintaining efficiency comparable to MP-GNNs. SubFormer-Spec demonstrates strong performance across various datasets.
Transformers are efficient hierarchical chemical graph learners
Oct 02, 2023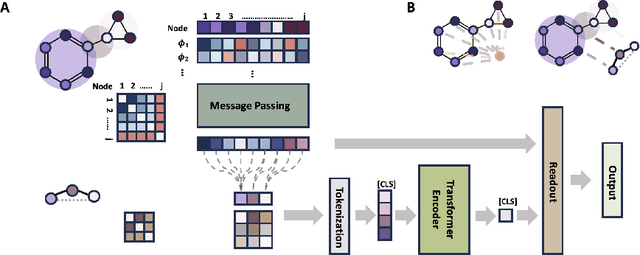

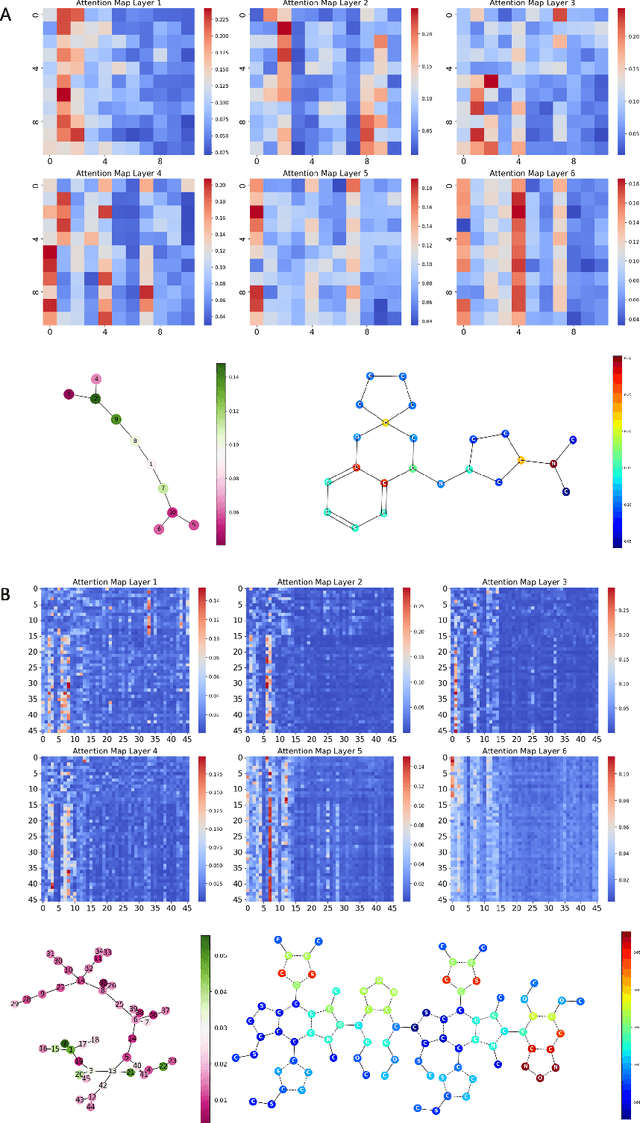
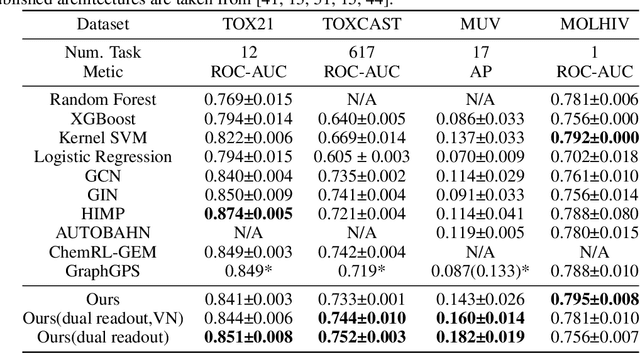
Transformers, adapted from natural language processing, are emerging as a leading approach for graph representation learning. Contemporary graph transformers often treat nodes or edges as separate tokens. This approach leads to computational challenges for even moderately-sized graphs due to the quadratic scaling of self-attention complexity with token count. In this paper, we introduce SubFormer, a graph transformer that operates on subgraphs that aggregate information by a message-passing mechanism. This approach reduces the number of tokens and enhances learning long-range interactions. We demonstrate SubFormer on benchmarks for predicting molecular properties from chemical structures and show that it is competitive with state-of-the-art graph transformers at a fraction of the computational cost, with training times on the order of minutes on a consumer-grade graphics card. We interpret the attention weights in terms of chemical structures. We show that SubFormer exhibits limited over-smoothing and avoids over-squashing, which is prevalent in traditional graph neural networks.
R-Mixup: Riemannian Mixup for Biological Networks
Jun 05, 2023



Biological networks are commonly used in biomedical and healthcare domains to effectively model the structure of complex biological systems with interactions linking biological entities. However, due to their characteristics of high dimensionality and low sample size, directly applying deep learning models on biological networks usually faces severe overfitting. In this work, we propose R-MIXUP, a Mixup-based data augmentation technique that suits the symmetric positive definite (SPD) property of adjacency matrices from biological networks with optimized training efficiency. The interpolation process in R-MIXUP leverages the log-Euclidean distance metrics from the Riemannian manifold, effectively addressing the swelling effect and arbitrarily incorrect label issues of vanilla Mixup. We demonstrate the effectiveness of R-MIXUP with five real-world biological network datasets on both regression and classification tasks. Besides, we derive a commonly ignored necessary condition for identifying the SPD matrices of biological networks and empirically study its influence on the model performance. The code implementation can be found in Appendix E.
Group-Equivariant Neural Networks with Fusion Diagrams
Nov 14, 2022Many learning tasks in physics and chemistry involve global spatial symmetries as well as permutational symmetry between particles. The standard approach to such problems is equivariant neural networks, which employ tensor products between various tensors that transform under the spatial group. However, as the number of different tensors and the complexity of relationships between them increases, the bookkeeping associated with ensuring parsimony as well as equivariance quickly becomes nontrivial. In this paper, we propose to use fusion diagrams, a technique widely used in simulating SU($2$)-symmetric quantum many-body problems, to design new equivariant components for use in equivariant neural networks. This yields a diagrammatic approach to constructing new neural network architectures. We show that when applied to particles in a given local neighborhood, the resulting components, which we call fusion blocks, are universal approximators of any continuous equivariant function defined on the neighborhood. As a practical demonstration, we incorporate a fusion block into a pre-existing equivariant architecture (Cormorant) and show that it improves performance on benchmark molecular learning tasks.
On the Super-exponential Quantum Speedup of Equivariant Quantum Machine Learning Algorithms with SU Symmetry
Jul 15, 2022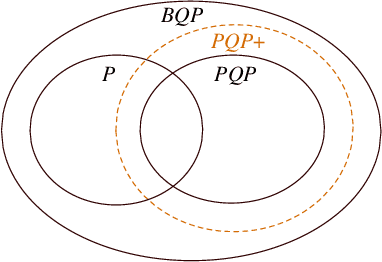
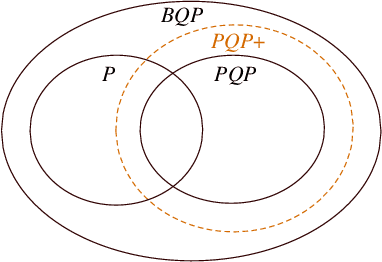
We introduce a framework of the equivariant convolutional algorithms which is tailored for a number of machine-learning tasks on physical systems with arbitrary SU($d$) symmetries. It allows us to enhance a natural model of quantum computation--permutational quantum computing (PQC) [Quantum Inf. Comput., 10, 470-497 (2010)] --and defines a more powerful model: PQC+. While PQC was shown to be effectively classically simulatable, we exhibit a problem which can be efficiently solved on PQC+ machine, whereas the best known classical algorithms runs in $O(n!n^2)$ time, thus providing strong evidence against PQC+ being classically simulatable. We further discuss practical quantum machine learning algorithms which can be carried out in the paradigm of PQC+.
Speeding up Learning Quantum States through Group Equivariant Convolutional Quantum Ans{ä}tze
Dec 14, 2021
We develop a theoretical framework for $S_n$-equivariant quantum convolutional circuits, building on and significantly generalizing Jordan's Permutational Quantum Computing (PQC) formalism. We show that quantum circuits are a natural choice for Fourier space neural architectures affording a super-exponential speedup in computing the matrix elements of $S_n$-Fourier coefficients compared to the best known classical Fast Fourier Transform (FFT) over the symmetric group. In particular, we utilize the Okounkov-Vershik approach to prove Harrow's statement (Ph.D. Thesis 2005 p.160) on the equivalence between $\operatorname{SU}(d)$- and $S_n$-irrep bases and to establish the $S_n$-equivariant Convolutional Quantum Alternating Ans{\"a}tze ($S_n$-CQA) using Young-Jucys-Murphy (YJM) elements. We prove that $S_n$-CQA are dense, thus expressible within each $S_n$-irrep block, which may serve as a universal model for potential future quantum machine learning and optimization applications. Our method provides another way to prove the universality of Quantum Approximate Optimization Algorithm (QAOA), from the representation-theoretical point of view. Our framework can be naturally applied to a wide array of problems with global $\operatorname{SU}(d)$ symmetry. We present numerical simulations to showcase the effectiveness of the ans{\"a}tze to find the sign structure of the ground state of the $J_1$--$J_2$ antiferromagnetic Heisenberg model on the rectangular and Kagome lattices. Our work identifies quantum advantage for a specific machine learning problem, and provides the first application of the celebrated Okounkov-Vershik's representation theory to machine learning and quantum physics.