 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers are efficient hierarchical chemical graph learners
Paper and Code
Oct 02, 2023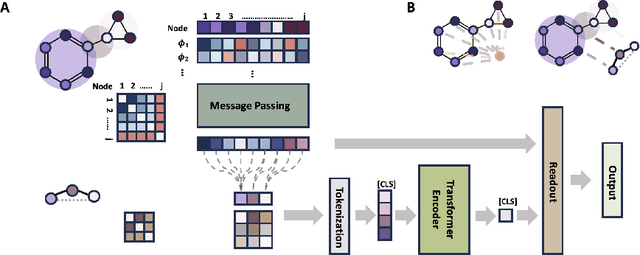

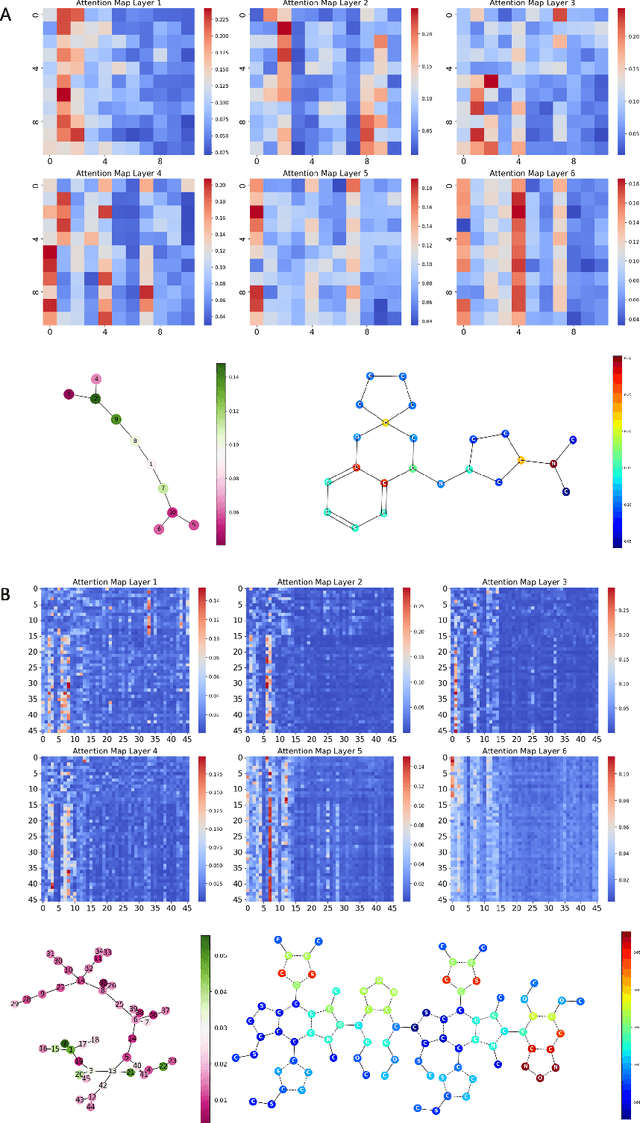
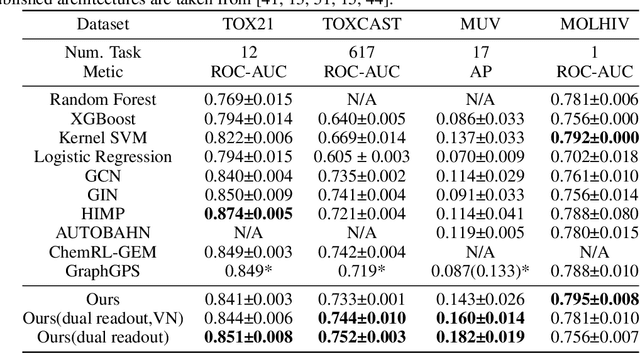
Transformers, adapted from natural language processing, are emerging as a leading approach for graph representation learning. Contemporary graph transformers often treat nodes or edges as separate tokens. This approach leads to computational challenges for even moderately-sized graphs due to the quadratic scaling of self-attention complexity with token count. In this paper, we introduce SubFormer, a graph transformer that operates on subgraphs that aggregate information by a message-passing mechanism. This approach reduces the number of tokens and enhances learning long-range interactions. We demonstrate SubFormer on benchmarks for predicting molecular properties from chemical structures and show that it is competitive with state-of-the-art graph transformers at a fraction of the computational cost, with training times on the order of minutes on a consumer-grade graphics card. We interpret the attention weights in terms of chemical structures. We show that SubFormer exhibits limited over-smoothing and avoids over-squashing, which is prevalent in traditional graph neural networks.