 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-Corrected Margin-Based Deep Cross-Modal Hashing for Facial Image Retrieval
Paper and Code
Apr 03, 2020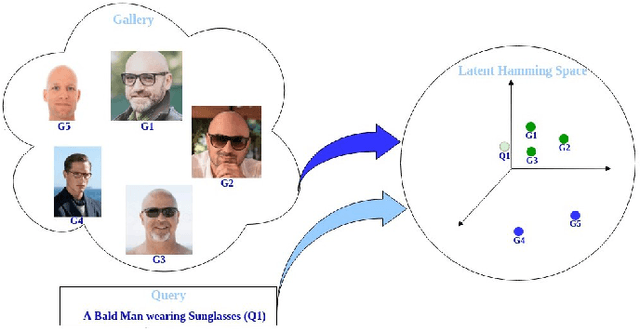
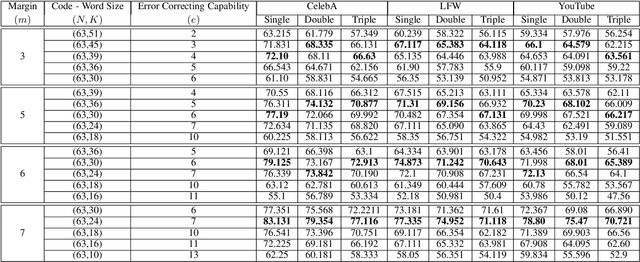
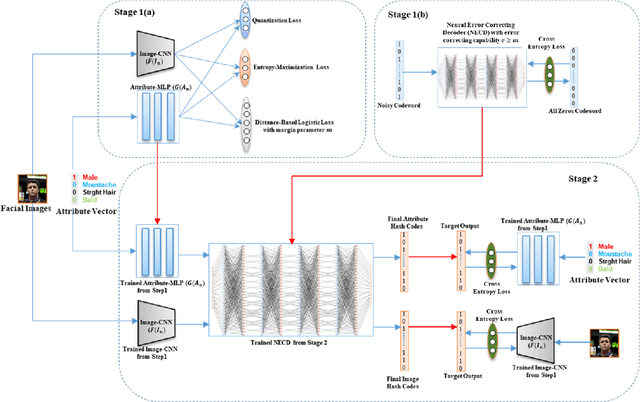
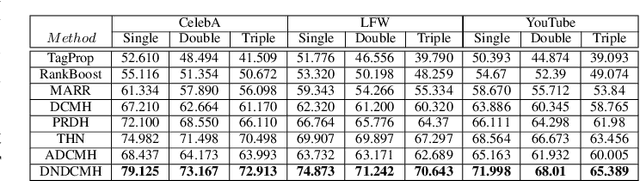
Cross-modal hashing facilitates mapping of heterogeneous multimedia data into a common Hamming space, which can beutilized for fast and flexible retrieval across different modalities. In this paper, we propose a novel cross-modal hashingarchitecture-deep neural decoder cross-modal hashing (DNDCMH), which uses a binary vector specifying the presence of certainfacial attributes as an input query to retrieve relevant face images from a database. The DNDCMH network consists of two separatecomponents: an attribute-based deep cross-modal hashing (ADCMH) module, which uses a margin (m)-based loss function toefficiently learn compact binary codes to preserve similarity between modalities in the Hamming space, and a neural error correctingdecoder (NECD), which is an error correcting decoder implemented with a neural network. The goal of NECD network in DNDCMH isto error correct the hash codes generated by ADCMH to improve the retrieval efficiency. The NECD network is trained such that it hasan error correcting capability greater than or equal to the margin (m) of the margin-based loss function. This results in NECD cancorrect the corrupted hash codes generated by ADCMH up to the Hamming distance of m. We have evaluated and comparedDNDCMH with state-of-the-art cross-modal hashing methods on standard datasets to demonstrate the superiority of our method.