 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Time Warping for Multiple Time Series Alignment
Feb 22, 2025Time Series Alignment is a critical task in signal processing with numerous real-world applications. In practice, signals often exhibit temporal shifts and scaling, making classification on raw data prone to errors. This paper introduces a novel approach for Multiple Time Series Alignment (MTSA) leveraging Deep Learning techniques. While most existing methods primarily address Multiple Sequence Alignment (MSA) for protein and DNA sequences, there remains a significant gap in alignment methodologies for numerical time series. Additionally, conventional approaches typically focus on pairwise alignment, whereas our proposed method aligns all signals in a multiple manner (all the signals are aligned together at once). This innovation not only enhances alignment efficiency but also significantly improves computational speed. By decomposing into piece-wise linear sections, we introduce varying levels of complexity into the warping function. Additionally, our method ensures the satisfaction of three warping constraints: boundary, monotonicity, and continuity conditions. The utilization of a deep convolutional network allows us to employ a new loss function, addressing some limitations of Dynamic Time Warping (DTW). Experimental results on the UCR Archive 2018, comprising 129 time series datasets, demonstrate that employing our approach to align signals significantly enhances classification accuracy and warping average and also reduces the run time across the majority of these datasets.
A Low-Computational Video Synopsis Framework with a Standard Dataset
Sep 08, 2024Video synopsis is an efficient method for condensing surveillance videos. This technique begins with the detection and tracking of objects, followed by the creation of object tubes. These tubes consist of sequences, each containing chronologically ordered bounding boxes of a unique object. To generate a condensed video, the first step involves rearranging the object tubes to maximize the number of non-overlapping objects in each frame. Then, these tubes are stitched to a background image extracted from the source video. The lack of a standard dataset for the video synopsis task hinders the comparison of different video synopsis models. This paper addresses this issue by introducing a standard dataset, called SynoClip, designed specifically for the video synopsis task. SynoClip includes all the necessary features needed to evaluate various models directly and effectively. Additionally, this work introduces a video synopsis model, called FGS, with low computational cost. The model includes an empty-frame object detector to identify frames empty of any objects, facilitating efficient utilization of the deep object detector. Moreover, a tube grouping algorithm is proposed to maintain relationships among tubes in the synthesized video. This is followed by a greedy tube rearrangement algorithm, which efficiently determines the start time of each tube. Finally, the proposed model is evaluated using the proposed dataset. The source code, fine-tuned object detection model, and tutorials are available at https://github.com/Ramtin-ma/VideoSynopsis-FGS.
Dynamic Changes of Brain Network during Epileptic Seizure
Oct 04, 2023



Epilepsy is a neurological disorder identified by sudden and recurrent seizures, which are believed to be accompanied by distinct changes in brain dynamics. Exploring the dynamic changes of brain network states during seizures can pave the way for improving the diagnosis and treatment of patients with epilepsy. In this paper, the connectivity brain network is constructed using the phase lag index (PLI) measurement within five frequency bands, and graph-theoretic techniques are employed to extract topological features from the brain network. Subsequently, an unsupervised clustering approach is used to examine the state transitions of the brain network during seizures. Our findings demonstrate that the level of brain synchrony during the seizure period is higher than the pre-seizure and post-seizure periods in the theta, alpha, and beta bands, while it decreases in the gamma bands. These changes in synchronization also lead to alterations in the topological features of functional brain networks during seizures. Additionally, our results suggest that the dynamics of the brain during seizures are more complex than the traditional three-state model (pre-seizure, seizure, and post-seizure) and the brain network state exhibits a slower rate of change during the seizure period compared to the pre-seizure and post-seizure periods.
Video alignment using unsupervised learning of local and global features
Apr 13, 2023In this paper, we tackle the problem of video alignment, the process of matching the frames of a pair of videos containing similar actions. The main challenge in video alignment is that accurate correspondence should be established despite the differences in the execution processes and appearances between the two videos. We introduce an unsupervised method for alignment that uses global and local features of the frames. In particular, we introduce effective features for each video frame by means of three machine vision tools: person detection, pose estimation, and VGG network. Then the features are processed and combined to construct a multidimensional time series that represent the video. The resulting time series are used to align videos of the same actions using a novel version of dynamic time warping named Diagonalized Dynamic Time Warping(DDTW). The main advantage of our approach is that no training is required, which makes it applicable for any new type of action without any need to collect training samples for it. For evaluation, we considered video synchronization and phase classification tasks on the Penn action dataset. Also, for an effective evaluation of the video synchronization task, we present a new metric called Enclosed Area Error(EAE). The results show that our method outperforms previous state-of-the-art methods, such as TCC and other self-supervised and supervised methods.
Face: Fast, Accurate and Context-Aware Audio Annotation and Classification
Mar 07, 2023This paper presents a context-aware framework for feature selection and classification procedures to realize a fast and accurate audio event annotation and classification. The context-aware design starts with exploring feature extraction techniques to find an appropriate combination to select a set resulting in remarkable classification accuracy with minimal computational effort. The exploration for feature selection also embraces an investigation of audio Tempo representation, an advantageous feature extraction method missed by previous works in the environmental audio classification research scope. The proposed annotation method considers outlier, inlier, and hard-to-predict data samples to realize context-aware Active Learning, leading to the average accuracy of 90% when only 15% of data possess initial annotation. Our proposed algorithm for sound classification obtained average prediction accuracy of 98.05% on the UrbanSound8K dataset. The notebooks containing our source codes and implementation results are available at https://github.com/gitmehrdad/FACE.
Elderly Fall Detection Using CCTV Cameras under Partial Occlusion of the Subjects Body
Aug 15, 2022



One of the possible dangers that older people face in their daily lives is falling. Occlusion is one of the biggest challenges of vision-based fall detection systems and degrades their detection performance considerably. To tackle this problem, we synthesize specifically-designed occluded videos for training fall detection systems using existing datasets. Then, by defining a new cost function, we introduce a framework for weighted training of fall detection models using occluded and un-occluded videos, which can be applied to any learnable fall detection system. Finally, we use both a non-deep and deep model to evaluate the effect of the proposed weighted training method. Experiments show that the proposed method can improve the classification accuracy by 36% for a non-deep model and 55% for a deep model in occlusion conditions. Moreover, it is shown that the proposed training framework can also significantly improve the detection performance of a deep network on normal un-occluded samples.
Temporal Analysis of Functional Brain Connectivity for EEG-based Emotion Recognition
Dec 23, 2021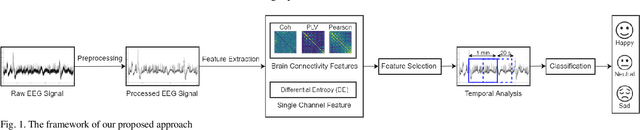
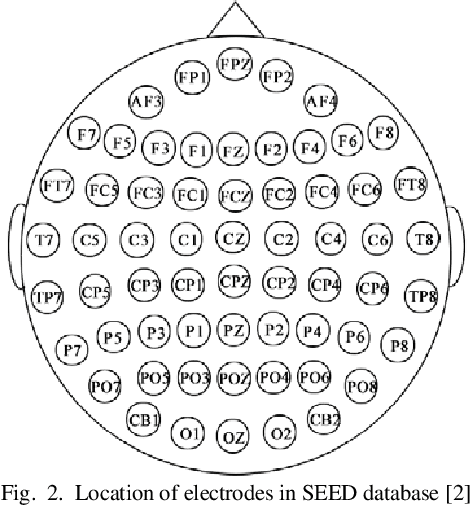
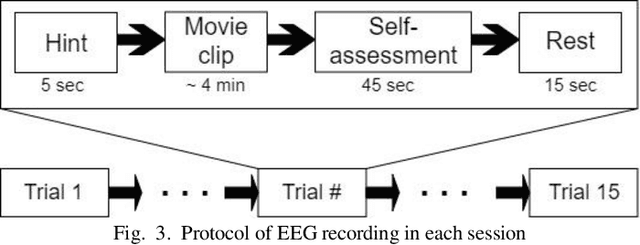

EEG signals in emotion recognition absorb special attention owing to their high temporal resolution and their information about what happens in the brain. Different regions of brain work together to process information and meanwhile the activity of brain changes during the time. Therefore, the investigation of the connection between different brain areas and their temporal patterns plays an important role in neuroscience. In this study, we investigate the emotion classification performance using functional connectivity features in different frequency bands and compare them with the classification performance using differential entropy feature, which has been previously used for this task. Moreover, we investigate the effect of using different time periods on the classification performance. Our results on publicly available SEED dataset show that as time goes on, emotions become more stable and the classification accuracy increases. Among different time periods, we achieve the highest classification accuracy using the time period of 140s-end. In this time period, the accuracy is improved by 4 to 6% compared to using the entire signal. The mean accuracy of about 88% is obtained using any of the Pearson correlation coefficient, coherence, and phase locking value features and SVM. Therefore, functional connectivity features lead to better classification accuracy than DE features (with the mean accuracy of 84.89%) using the proposed framework. Finally, in a relatively fair comparison, we show that using the best time interval and SVM, we achieve better accuracy than using Recurrent Neural Networks which need large amount of data and have high computational cost.
Temporal Action Localization Using Gated Recurrent Units
Aug 07, 2021
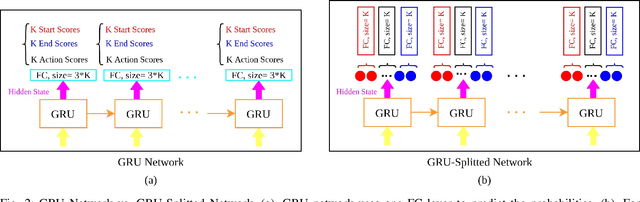
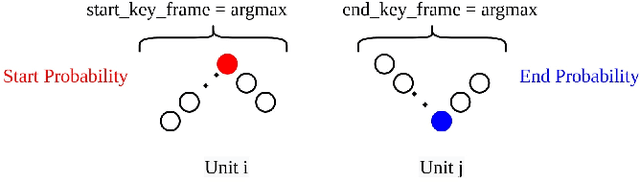
Temporal Action Localization (TAL) task in which the aim is to predict the start and end of each action and its class label has many applications in the real world. But due to its complexity, researchers have not reached great results compared to the action recognition task. The complexity is related to predicting precise start and end times for different actions in any video. In this paper, we propose a new network based on Gated Recurrent Unit (GRU) and two novel post-processing ideas for TAL task. Specifically, we propose a new design for the output layer of the GRU resulting in the so-called GRU-Splitted model. Moreover, linear interpolation is used to generate the action proposals with precise start and end times. Finally, to rank the generated proposals appropriately, we use a Learn to Rank (LTR) approach. We evaluated the performance of the proposed method on Thumos14 dataset. Results show the superiority of the performance of the proposed method compared to state-of-the-art. Especially in the mean Average Precision (mAP) metric at Intersection over Union (IoU) 0.7, we get 27.52% which is 5.12% better than that of state-of-the-art methods.
DTW-Merge: A Novel Data Augmentation Technique for Time Series Classification
Mar 01, 2021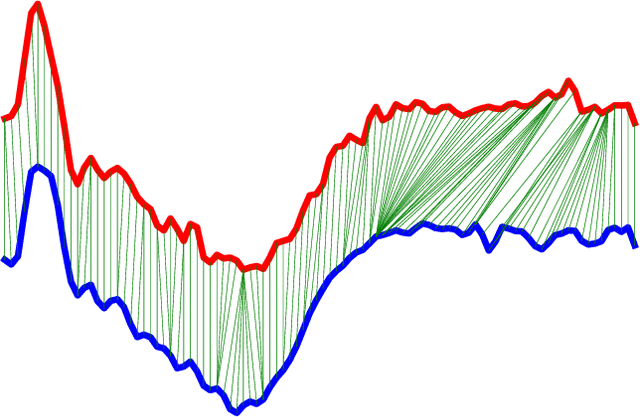
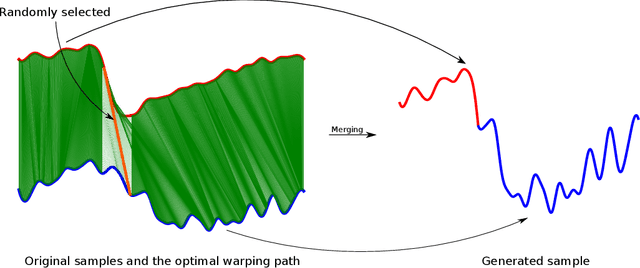
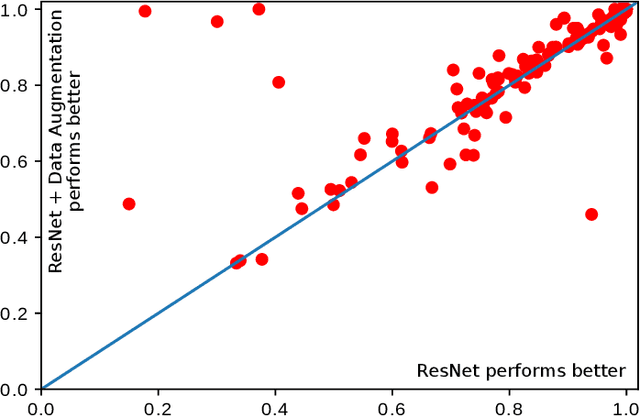
In recent years, neural networks achieved much success in various applications. The main challenge in training deep neural networks is the lack of sufficient data to improve the model's generalization and avoid overfitting. One of the solutions is to generate new training samples. This paper proposes a novel data augmentation method for time series based on Dynamic Time Warping. This method is inspired by the concept that warped parts of two time series have the same temporal properties. Exploiting the proposed approach with recently-introduced ResNet reveals the improvement of results on the 2018 UCR Time Series Classification Archive.
Tree-Based Optimization: A Meta-Algorithm for Metaheuristic Optimization
Sep 25, 2018
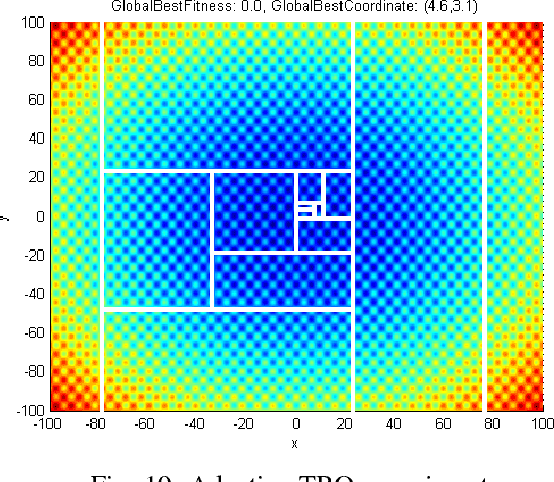
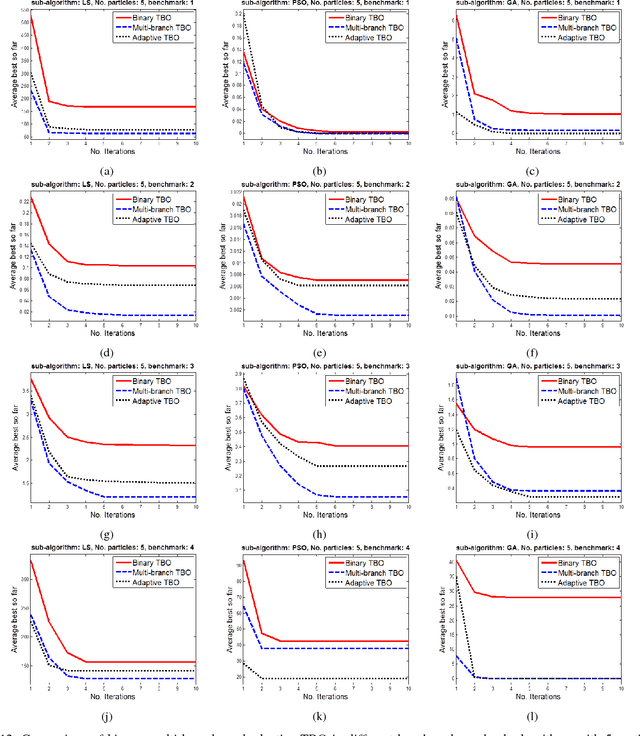
Designing search algorithms for finding global optima is one of the most active research fields, recently. These algorithms consist of two main categories, i.e., classic mathematical and metaheuristic algorithms. This article proposes a meta-algorithm, Tree-Based Optimization (TBO), which uses other heuristic optimizers as its sub-algorithms in order to improve the performance of search. The proposed algorithm is based on mathematical tree subject and improves performance and speed of search by iteratively removing parts of the search space having low fitness, in order to minimize and purify the search space. The experimental results on several well-known benchmarks show the outperforming performance of TBO algorithm in finding the global solution. Experiments on high dimensional search spaces show significantly better performance when using the TBO algorithm. The proposed algorithm improves the search algorithms in both accuracy and speed aspects, especially for high dimensional searching such as in VLSI CAD tools for Integrated Circuit (IC) design.