 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKANGURA: Kolmogorov-Arnold Network-Based Geometry-Aware Learning with Unified Representation Attention for 3D Modeling of Complex Structures
Nov 17, 2025Microbial Fuel Cells (MFCs) offer a promising pathway for sustainable energy generation by converting organic matter into electricity through microbial processes. A key factor influencing MFC performance is the anode structure, where design and material properties play a crucial role. Existing predictive models struggle to capture the complex geometric dependencies necessary to optimize these structures. To solve this problem, we propose KANGURA: Kolmogorov-Arnold Network-Based Geometry-Aware Learning with Unified Representation Attention. KANGURA introduces a new approach to three-dimensional (3D) machine learning modeling. It formulates prediction as a function decomposition problem, where Kolmogorov-Arnold Network (KAN)- based representation learning reconstructs geometric relationships without a conventional multi- layer perceptron (MLP). To refine spatial understanding, geometry-disentangled representation learning separates structural variations into interpretable components, while unified attention mechanisms dynamically enhance critical geometric regions. Experimental results demonstrate that KANGURA outperforms over 15 state-of-the-art (SOTA) models on the ModelNet40 benchmark dataset, achieving 92.7% accuracy, and excels in a real-world MFC anode structure problem with 97% accuracy. This establishes KANGURA as a robust framework for 3D geometric modeling, unlocking new possibilities for optimizing complex structures in advanced manufacturing and quality-driven engineering applications.
From Automation to Autonomy in Smart Manufacturing: A Bayesian Optimization Framework for Modeling Multi-Objective Experimentation and Sequential Decision Making
Apr 05, 2025Discovering novel materials with desired properties is essential for driving innovation. Industry 4.0 and smart manufacturing have promised transformative advances in this area through real-time data integration and automated production planning and control. However, the reliance on automation alone has often fallen short, lacking the flexibility needed for complex processes. To fully unlock the potential of smart manufacturing, we must evolve from automation to autonomous systems that go beyond rigid programming and can dynamically optimize the search for solutions. Current discovery approaches are often slow, requiring numerous trials to find optimal combinations, and costly, particularly when optimizing multiple properties simultaneously. This paper proposes a Bayesian multi-objective sequential decision-making (BMSDM) framework that can intelligently select experiments as manufacturing progresses, guiding us toward the discovery of optimal design faster and more efficiently. The framework leverages sequential learning through Bayesian Optimization, which iteratively refines a statistical model representing the underlying manufacturing process. This statistical model acts as a surrogate, allowing for efficient exploration and optimization without requiring numerous real-world experiments. This approach can significantly reduce the time and cost of data collection required by traditional experimental designs. The proposed framework is compared with traditional DoE methods and two other multi-objective optimization methods. Using a manufacturing dataset, we evaluate and compare the performance of these approaches across five evaluation metrics. BMSDM comprehensively outperforms the competing methods in multi-objective decision-making scenarios. Our proposed approach represents a significant leap forward in creating an intelligent autonomous platform capable of novel material discovery.
A Comprehensive Approach to Carbon Dioxide Emission Analysis in High Human Development Index Countries using Statistical and Machine Learning Techniques
May 01, 2024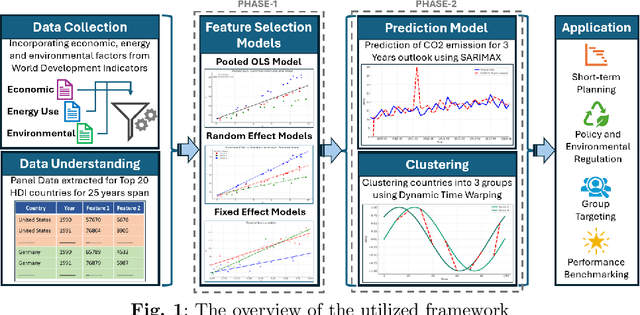
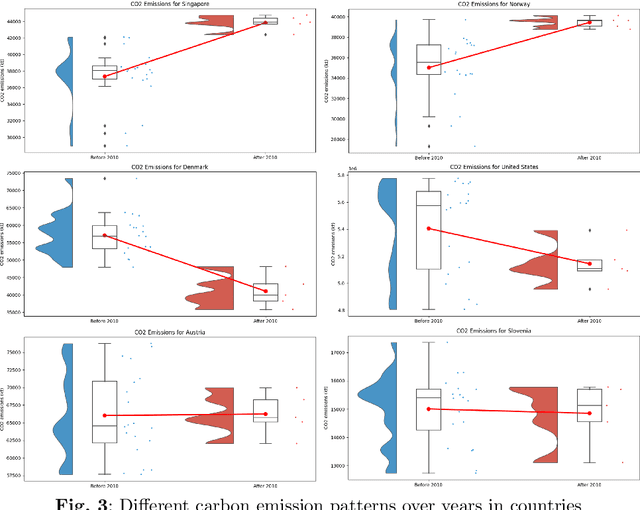

Reducing Carbon dioxide (CO2) emission is vital at both global and national levels, given their significant role in exacerbating climate change. CO2 emission, stemming from a variety of industrial and economic activities, are major contributors to the greenhouse effect and global warming, posing substantial obstacles in addressing climate issues. It's imperative to forecast CO2 emission trends and classify countries based on their emission patterns to effectively mitigate worldwide carbon emission. This paper presents an in-depth comparative study on the determinants of CO2 emission in twenty countries with high Human Development Index (HDI), exploring factors related to economy, environment, energy use, and renewable resources over a span of 25 years. The study unfolds in two distinct phases: initially, statistical techniques such as Ordinary Least Squares (OLS), fixed effects, and random effects models are applied to pinpoint significant determinants of CO2 emission. Following this, the study leverages supervised and unsupervised machine learning (ML) methods to further scrutinize and understand the factors influencing CO2 emission. Seasonal AutoRegressive Integrated Moving Average with eXogenous variables (SARIMAX), a supervised ML model, is first used to predict emission trends from historical data, offering practical insights for policy formulation. Subsequently, Dynamic Time Warping (DTW), an unsupervised learning approach, is used to group countries by similar emission patterns. The dual-phase approach utilized in this study significantly improves the accuracy of CO2 emission predictions while also providing a deeper insight into global emission trends. By adopting this thorough analytical framework, nations can develop more focused and effective carbon reduction policies, playing a vital role in the global initiative to combat climate change.
Binary Gaussian Copula Synthesis: A Novel Data Augmentation Technique to Advance ML-based Clinical Decision Support Systems for Early Prediction of Dialysis Among CKD Patients
Mar 01, 2024The Center for Disease Control estimates that over 37 million US adults suffer from chronic kidney disease (CKD), yet 9 out of 10 of these individuals are unaware of their condition due to the absence of symptoms in the early stages. It has a significant impact on patients' quality of life, particularly when it progresses to the need for dialysis. Early prediction of dialysis is crucial as it can significantly improve patient outcomes and assist healthcare providers in making timely and informed decisions. However, developing an effective machine learning (ML)-based Clinical Decision Support System (CDSS) for early dialysis prediction poses a key challenge due to the imbalanced nature of data. To address this challenge, this study evaluates various data augmentation techniques to understand their effectiveness on real-world datasets. We propose a new approach named Binary Gaussian Copula Synthesis (BGCS). BGCS is tailored for binary medical datasets and excels in generating synthetic minority data that mirrors the distribution of the original data. BGCS enhances early dialysis prediction by outperforming traditional methods in detecting dialysis patients. For the best ML model, Random Forest, BCGS achieved a 72% improvement, surpassing the state-of-the-art augmentation approaches. Also, we present a ML-based CDSS, designed to aid clinicians in making informed decisions. CDSS, which utilizes decision tree models, is developed to improve patient outcomes, identify critical variables, and thereby enable clinicians to make proactive decisions, and strategize treatment plans effectively for CKD patients who are more likely to require dialysis in the near future. Through comprehensive feature analysis and meticulous data preparation, we ensure that the CDSS's dialysis predictions are not only accurate but also actionable, providing a valuable tool in the management and treatment of CKD.
An Augmented Surprise-guided Sequential Learning Framework for Predicting the Melt Pool Geometry
Jan 10, 2024Metal Additive Manufacturing (MAM) has reshaped the manufacturing industry, offering benefits like intricate design, minimal waste, rapid prototyping, material versatility, and customized solutions. However, its full industry adoption faces hurdles, particularly in achieving consistent product quality. A crucial aspect for MAM's success is understanding the relationship between process parameters and melt pool characteristics. Integrating Artificial Intelligence (AI) into MAM is essential. Traditional machine learning (ML) methods, while effective, depend on large datasets to capture complex relationships, a significant challenge in MAM due to the extensive time and resources required for dataset creation. Our study introduces a novel surprise-guided sequential learning framework, SurpriseAF-BO, signaling a significant shift in MAM. This framework uses an iterative, adaptive learning process, modeling the dynamics between process parameters and melt pool characteristics with limited data, a key benefit in MAM's cyber manufacturing context. Compared to traditional ML models, our sequential learning method shows enhanced predictive accuracy for melt pool dimensions. Further improving our approach, we integrated a Conditional Tabular Generative Adversarial Network (CTGAN) into our framework, forming the CT-SurpriseAF-BO. This produces synthetic data resembling real experimental data, improving learning effectiveness. This enhancement boosts predictive precision without requiring additional physical experiments. Our study demonstrates the power of advanced data-driven techniques in cyber manufacturing and the substantial impact of sequential AI and ML, particularly in overcoming MAM's traditional challenges.
Accelerating material discovery with a threshold-driven hybrid acquisition policy-based Bayesian optimization
Nov 16, 2023Advancements in materials play a crucial role in technological progress. However, the process of discovering and developing materials with desired properties is often impeded by substantial experimental costs, extensive resource utilization, and lengthy development periods. To address these challenges, modern approaches often employ machine learning (ML) techniques such as Bayesian Optimization (BO), which streamline the search for optimal materials by iteratively selecting experiments that are most likely to yield beneficial results. However, traditional BO methods, while beneficial, often struggle with balancing the trade-off between exploration and exploitation, leading to sub-optimal performance in material discovery processes. This paper introduces a novel Threshold-Driven UCB-EI Bayesian Optimization (TDUE-BO) method, which dynamically integrates the strengths of Upper Confidence Bound (UCB) and Expected Improvement (EI) acquisition functions to optimize the material discovery process. Unlike the classical BO, our method focuses on efficiently navigating the high-dimensional material design space (MDS). TDUE-BO begins with an exploration-focused UCB approach, ensuring a comprehensive initial sweep of the MDS. As the model gains confidence, indicated by reduced uncertainty, it transitions to the more exploitative EI method, focusing on promising areas identified earlier. The UCB-to-EI switching policy dictated guided through continuous monitoring of the model uncertainty during each step of sequential sampling results in navigating through the MDS more efficiently while ensuring rapid convergence. The effectiveness of TDUE-BO is demonstrated through its application on three different material datasets, showing significantly better approximation and optimization performance over the EI and UCB-based BO methods in terms of the RMSE scores and convergence efficiency, respectively.
Strategic Data Augmentation with CTGAN for Smart Manufacturing: Enhancing Machine Learning Predictions of Paper Breaks in Pulp-and-Paper Production
Nov 15, 2023A significant challenge for predictive maintenance in the pulp-and-paper industry is the infrequency of paper breaks during the production process. In this article, operational data is analyzed from a paper manufacturing machine in which paper breaks are relatively rare but have a high economic impact. Utilizing a dataset comprising 18,398 instances derived from a quality assurance protocol, we address the scarcity of break events (124 cases) that pose a challenge for machine learning predictive models. With the help of Conditional Generative Adversarial Networks (CTGAN) and Synthetic Minority Oversampling Technique (SMOTE), we implement a novel data augmentation framework. This method ensures that the synthetic data mirrors the distribution of the real operational data but also seeks to enhance the performance metrics of predictive modeling. Before and after the data augmentation, we evaluate three different machine learning algorithms-Decision Trees (DT), Random Forest (RF), and Logistic Regression (LR). Utilizing the CTGAN-enhanced dataset, our study achieved significant improvements in predictive maintenance performance metrics. The efficacy of CTGAN in addressing data scarcity was evident, with the models' detection of machine breaks (Class 1) improving by over 30% for Decision Trees, 20% for Random Forest, and nearly 90% for Logistic Regression. With this methodological advancement, this study contributes to industrial quality control and maintenance scheduling by addressing rare event prediction in manufacturing processes.
Identification of the Factors Affecting the Reduction of Energy Consumption and Cost in Buildings Using Data Mining Techniques
May 15, 2023Optimizing energy consumption and coordination of utility systems have long been a concern of the building industry. Buildings are one of the largest energy consumers in the world, making their energy efficiency crucial for preventing waste and reducing costs. Additionally, buildings generate substantial amounts of raw data, which can be used to understand energy consumption patterns and assist in developing optimization strategies. Using a real-world dataset, this research aims to identify the factors that influence building cost reduction and energy consumption. To achieve this, we utilize three regression models (Lasso Regression, Decision Tree, and Random Forest) to predict primary fuel usage, electrical energy consumption, and cost savings in buildings. An analysis of the factors influencing energy consumption and cost reduction is conducted, and the decision tree algorithm is optimized using metaheuristics. By employing metaheuristic techniques, we fine-tune the decision tree algorithm's parameters and improve its accuracy. Finally, we review the most practical features of potential and nonpotential buildings that can reduce primary fuel usage, electrical energy consumption, and costs
A Data Driven Sequential Learning Framework to Accelerate and Optimize Multi-Objective Manufacturing Decisions
Apr 18, 2023Manufacturing advanced materials and products with a specific property or combination of properties is often warranted. To achieve that it is crucial to find out the optimum recipe or processing conditions that can generate the ideal combination of these properties. Most of the time, a sufficient number of experiments are needed to generate a Pareto front. However, manufacturing experiments are usually costly and even conducting a single experiment can be a time-consuming process. So, it's critical to determine the optimal location for data collection to gain the most comprehensive understanding of the process. Sequential learning is a promising approach to actively learn from the ongoing experiments, iteratively update the underlying optimization routine, and adapt the data collection process on the go. This paper presents a novel data-driven Bayesian optimization framework that utilizes sequential learning to efficiently optimize complex systems with multiple conflicting objectives. Additionally, this paper proposes a novel metric for evaluating multi-objective data-driven optimization approaches. This metric considers both the quality of the Pareto front and the amount of data used to generate it. The proposed framework is particularly beneficial in practical applications where acquiring data can be expensive and resource intensive. To demonstrate the effectiveness of the proposed algorithm and metric, the algorithm is evaluated on a manufacturing dataset. The results indicate that the proposed algorithm can achieve the actual Pareto front while processing significantly less data. It implies that the proposed data-driven framework can lead to similar manufacturing decisions with reduced costs and time.