 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Approach to Carbon Dioxide Emission Analysis in High Human Development Index Countries using Statistical and Machine Learning Techniques
May 01, 2024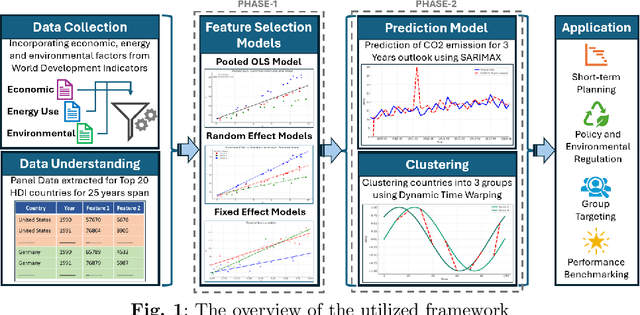
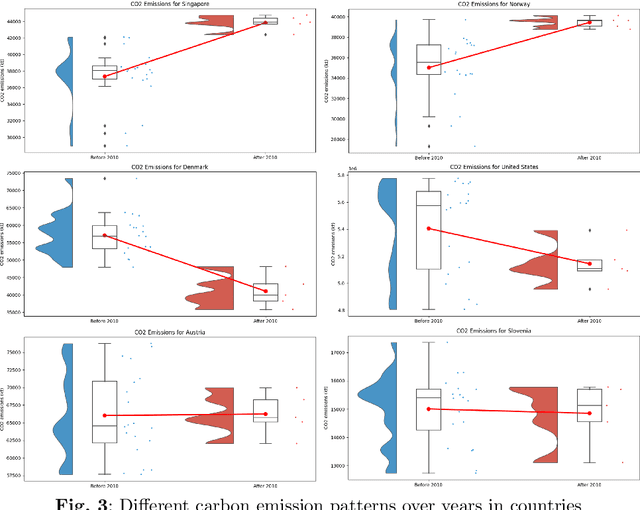

Reducing Carbon dioxide (CO2) emission is vital at both global and national levels, given their significant role in exacerbating climate change. CO2 emission, stemming from a variety of industrial and economic activities, are major contributors to the greenhouse effect and global warming, posing substantial obstacles in addressing climate issues. It's imperative to forecast CO2 emission trends and classify countries based on their emission patterns to effectively mitigate worldwide carbon emission. This paper presents an in-depth comparative study on the determinants of CO2 emission in twenty countries with high Human Development Index (HDI), exploring factors related to economy, environment, energy use, and renewable resources over a span of 25 years. The study unfolds in two distinct phases: initially, statistical techniques such as Ordinary Least Squares (OLS), fixed effects, and random effects models are applied to pinpoint significant determinants of CO2 emission. Following this, the study leverages supervised and unsupervised machine learning (ML) methods to further scrutinize and understand the factors influencing CO2 emission. Seasonal AutoRegressive Integrated Moving Average with eXogenous variables (SARIMAX), a supervised ML model, is first used to predict emission trends from historical data, offering practical insights for policy formulation. Subsequently, Dynamic Time Warping (DTW), an unsupervised learning approach, is used to group countries by similar emission patterns. The dual-phase approach utilized in this study significantly improves the accuracy of CO2 emission predictions while also providing a deeper insight into global emission trends. By adopting this thorough analytical framework, nations can develop more focused and effective carbon reduction policies, playing a vital role in the global initiative to combat climate change.
Winning through Collaboration by Applying Federated Learning in Manufacturing Industry
Feb 27, 2023



In manufacturing settings, data collection and analysis is often a time-consuming, challenging, and costly process. It also hinders the use of advanced machine learning and data-driven methods which requires a substantial amount of offline training data to generate good results. It is particularly challenging for small manufacturers who do not share the resources of a large enterprise. Recently, with the introduction of the Internet of Things (IoT), data can be collected in an integrated manner across the factory in real-time, sent to the cloud for advanced analysis, and used to update the machine learning model sequentially. Nevertheless, small manufacturers face two obstacles in reaping the benefits of IoT: they may be unable to afford or generate enough data to operate a private cloud, and they may be hesitant to share their raw data with a public cloud. Federated learning (FL) is an emerging concept of collaborative learning that can help small-scale industries address these issues and learn from each other without sacrificing their privacy. It can bring together diverse and geographically dispersed manufacturers under the same analytics umbrella to create a win-win situation. However, the widespread adoption of FL across multiple manufacturing organizations remains a significant challenge. This work aims to identify and illustrate these challenges and provide potential solutions to overcome them.