 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemedR: Reward Engineering for Clinical Offline Reinforcement Learning via Tri-Drive Potential Functions
Feb 03, 2026Reinforcement Learning (RL) offers a powerful framework for optimizing dynamic treatment regimes (DTRs). However, clinical RL is fundamentally bottlenecked by reward engineering: the challenge of defining signals that safely and effectively guide policy learning in complex, sparse offline environments. Existing approaches often rely on manual heuristics that fail to generalize across diverse pathologies. To address this, we propose an automated pipeline leveraging Large Language Models (LLMs) for offline reward design and verification. We formulate the reward function using potential functions consisted of three core components: survival, confidence, and competence. We further introduce quantitative metrics to rigorously evaluate and select the optimal reward structure prior to deployment. By integrating LLM-driven domain knowledge, our framework automates the design of reward functions for specific diseases while significantly enhancing the performance of the resulting policies.
MedDreamer: Model-Based Reinforcement Learning with Latent Imagination on Complex EHRs for Clinical Decision Support
May 26, 2025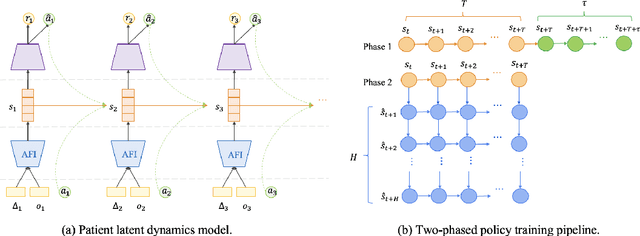
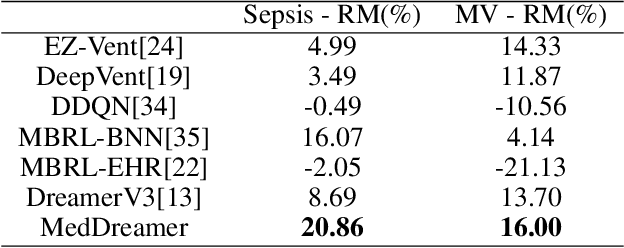
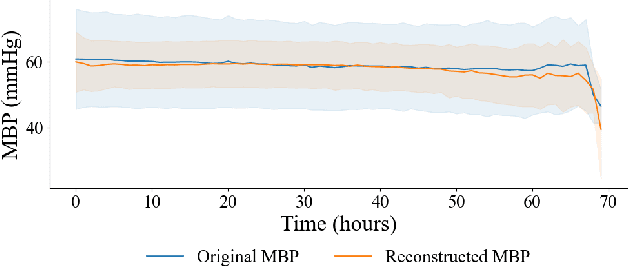
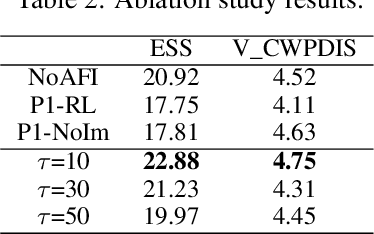
Timely and personalized treatment decisions are essential across a wide range of healthcare settings where patient responses vary significantly and evolve over time. Clinical data used to support these decisions are often irregularly sampled, sparse, and noisy. Existing decision support systems commonly rely on discretization and imputation, which can distort critical temporal dynamics and degrade decision quality. Moreover, they often overlook the clinical significance of irregular recording frequencies, filtering out patterns in how and when data is collected. Reinforcement Learning (RL) is a natural fit for clinical decision-making, enabling sequential, long-term optimization in dynamic, uncertain environments. However, most existing treatment recommendation systems are model-free and trained solely on offline data, making them sample-inefficient, sensitive to data quality, and poorly generalizable across tasks or cohorts. To address these limitations, we propose MedDreamer, a two-phase model-based RL framework for personalized treatment recommendation. MedDreamer uses a world model with an Adaptive Feature Integration (AFI) module to effectively model irregular, sparse clinical data. Through latent imagination, it simulates plausible patient trajectories to enhance learning, refining its policy using a mix of real and imagined experiences. This enables learning policies that go beyond suboptimal historical decisions while remaining grounded in clinical data. To our knowledge, this is the first application of latent imagination to irregular healthcare data. Evaluations on sepsis and mechanical ventilation (MV) treatment using two large-scale EHR datasets show that MedDreamer outperforms both model-free and model-based baselines in clinical outcomes and off-policy metrics.
Optimizing Vision Transformers with Data-Free Knowledge Transfer
Aug 12, 2024The groundbreaking performance of transformers in Natural Language Processing (NLP) tasks has led to their replacement of traditional Convolutional Neural Networks (CNNs), owing to the efficiency and accuracy achieved through the self-attention mechanism. This success has inspired researchers to explore the use of transformers in computer vision tasks to attain enhanced long-term semantic awareness. Vision transformers (ViTs) have excelled in various computer vision tasks due to their superior ability to capture long-distance dependencies using the self-attention mechanism. Contemporary ViTs like Data Efficient Transformers (DeiT) can effectively learn both global semantic information and local texture information from images, achieving performance comparable to traditional CNNs. However, their impressive performance comes with a high computational cost due to very large number of parameters, hindering their deployment on devices with limited resources like smartphones, cameras, drones etc. Additionally, ViTs require a large amount of data for training to achieve performance comparable to benchmark CNN models. Therefore, we identified two key challenges in deploying ViTs on smaller form factor devices: the high computational requirements of large models and the need for extensive training data. As a solution to these challenges, we propose compressing large ViT models using Knowledge Distillation (KD), which is implemented data-free to circumvent limitations related to data availability. Additionally, we conducted experiments on object detection within the same environment in addition to classification tasks. Based on our analysis, we found that datafree knowledge distillation is an effective method to overcome both issues, enabling the deployment of ViTs on less resourceconstrained devices.
A Comprehensive Review of Knowledge Distillation in Computer Vision
Apr 08, 2024



Deep learning techniques have been demonstrated to surpass preceding cutting-edge machine learning techniques in recent years, with computer vision being one of the most prominent examples. However, deep learning models suffer from significant drawbacks when deployed in resource-constrained environments due to their large model size and high complexity. Knowledge Distillation is one of the prominent solutions to overcome this challenge. This review paper examines the current state of research on knowledge distillation, a technique for compressing complex models into smaller and simpler ones. The paper provides an overview of the major principles and techniques associated with knowledge distillation and reviews the applications of knowledge distillation in the domain of computer vision. The review focuses on the benefits of knowledge distillation, as well as the problems that must be overcome to improve its effectiveness.
Exploring the Efficacy of Group-Normalization in Deep Learning Models for Alzheimer's Disease Classification
Apr 01, 2024



Batch Normalization is an important approach to advancing deep learning since it allows multiple networks to train simultaneously. A problem arises when normalizing along the batch dimension because B.N.'s error increases significantly as batch size shrinks because batch statistics estimates are inaccurate. As a result, computer vision tasks like detection, segmentation, and video, which require tiny batches based on memory consumption, aren't suitable for using Batch Normalization for larger model training and feature transfer. Here, we explore Group Normalization as an easy alternative to using Batch Normalization A Group Normalization is a channel normalization method in which each group is divided into different channels, and the corresponding mean and variance are calculated for each group. Group Normalization computations are accurate across a wide range of batch sizes and are independent of batch size. When trained using a large ImageNet database on ResNet-50, GN achieves a very low error rate of 10.6% compared to Batch Normalization. when a smaller batch size of only 2 is used. For usual batch sizes, the performance of G.N. is comparable to that of Batch Normalization, but at the same time, it outperforms other normalization techniques. Implementing Group Normalization as a direct alternative to B.N to combat the serious challenges faced by the Batch Normalization in deep learning models with comparable or improved classification accuracy. Additionally, Group Normalization can be naturally transferred from the pre-training to the fine-tuning phase. .
Harnessing The Power of Attention For Patch-Based Biomedical Image Classification
Apr 01, 2024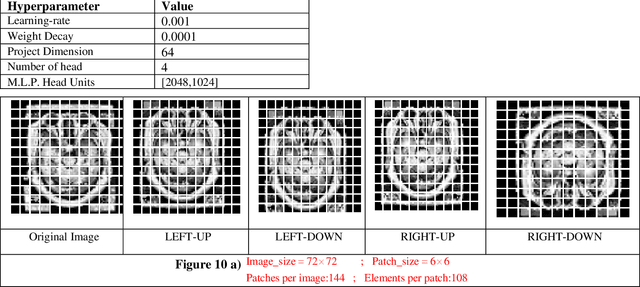
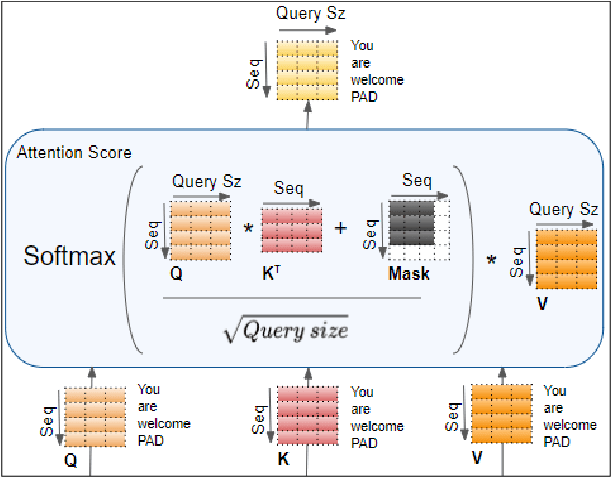
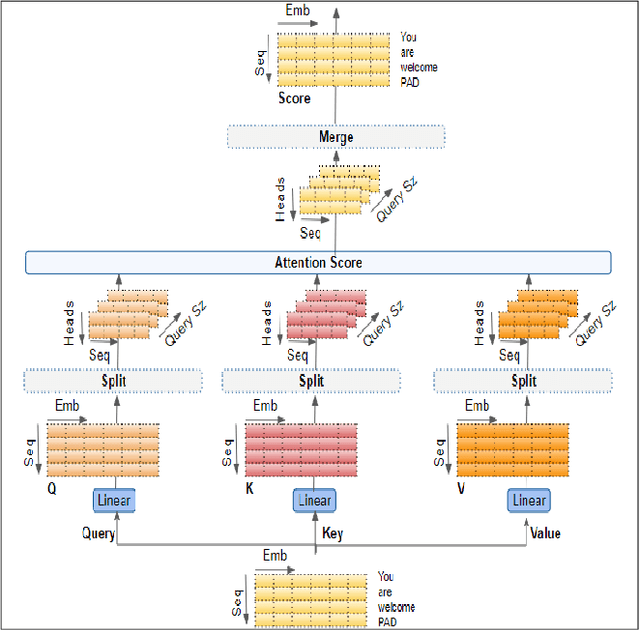
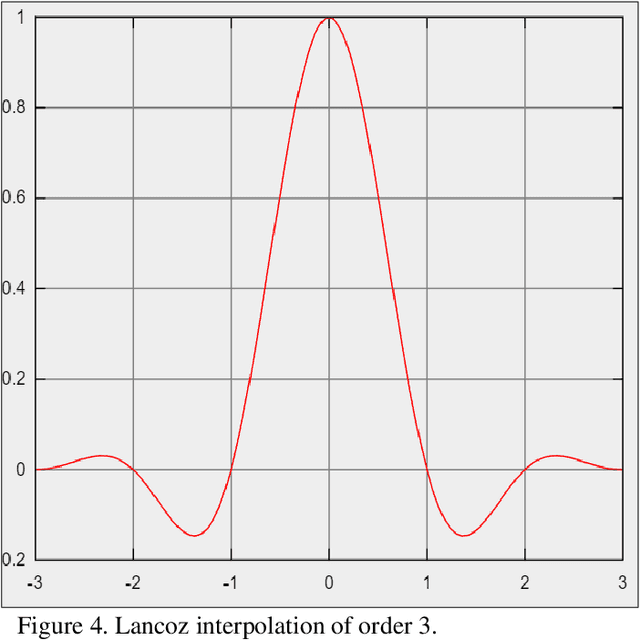
Biomedical image analysis can be facilitated by an innovative architecture rooted in self-attention mechanisms. The traditional convolutional neural network (CNN), characterized by fixed-sized windows, needs help capturing intricate spatial and temporal relations at the pixel level. The immutability of CNN filter weights post-training further restricts input fluctuations. Recognizing these limitations, we propose a new paradigm of attention-based models instead of convolutions. As an alternative to traditional CNNs, these models demonstrate robust modelling capabilities and the ability to grasp comprehensive long-range contextual information efficiently. Providing a solution to critical challenges faced by attention-based vision models such as inductive bias, weight sharing, receptive field limitations, and data handling in high resolution, our work combines non-overlapping (vanilla patching) with novel overlapped Shifted Patching Techniques (S.P.T.s) to induce local context that enhances model generalization. Moreover, we examine the novel Lancoz5 interpolation technique, which adapts variable image sizes to higher resolutions. Experimental evidence validates our model's generalization effectiveness, comparing favourably with existing approaches. Attention-based methods are particularly effective with ample data, especially when advanced data augmentation methodologies are integrated to strengthen their robustness.
Distilling Inductive Bias: Knowledge Distillation Beyond Model Compression
Oct 10, 2023With the rapid development of computer vision, Vision Transformers (ViTs) offer the tantalizing prospect of unified information processing across visual and textual domains. But due to the lack of inherent inductive biases in ViTs, they require enormous amount of data for training. To make their applications practical, we introduce an innovative ensemble-based distillation approach distilling inductive bias from complementary lightweight teacher models. Prior systems relied solely on convolution-based teaching. However, this method incorporates an ensemble of light teachers with different architectural tendencies, such as convolution and involution, to instruct the student transformer jointly. Because of these unique inductive biases, instructors can accumulate a wide range of knowledge, even from readily identifiable stored datasets, which leads to enhanced student performance. Our proposed framework also involves precomputing and storing logits in advance, essentially the unnormalized predictions of the model. This optimization can accelerate the distillation process by eliminating the need for repeated forward passes during knowledge distillation, significantly reducing the computational burden and enhancing efficiency.
Knowledge Distillation in Vision Transformers: A Critical Review
Feb 04, 2023In Natural Language Processing (NLP), Transformers have already revolutionized the field by utilizing an attention-based encoder-decoder model. Recently, some pioneering works have employed Transformer-like architectures in Computer Vision (CV) and they have reported outstanding performance of these architectures in tasks such as image classification, object detection, and semantic segmentation. Vision Transformers (ViTs) have demonstrated impressive performance improvements over Convolutional Neural Networks (CNNs) due to their competitive modelling capabilities. However, these architectures demand massive computational resources which makes these models difficult to be deployed in the resource-constrained applications. Many solutions have been developed to combat this issue, such as compressive transformers and compression functions such as dilated convolution, min-max pooling, 1D convolution, etc. Model compression has recently attracted considerable research attention as a potential remedy. A number of model compression methods have been proposed in the literature such as weight quantization, weight multiplexing, pruning and Knowledge Distillation (KD). However, techniques like weight quantization, pruning and weight multiplexing typically involve complex pipelines for performing the compression. KD has been found to be a simple and much effective model compression technique that allows a relatively simple model to perform tasks almost as accurately as a complex model. This paper discusses various approaches based upon KD for effective compression of ViT models. The paper elucidates the role played by KD in reducing the computational and memory requirements of these models. The paper also presents the various challenges faced by ViTs that are yet to be resolved.