 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedSPOT: A Workflow-Aware Sequential Grounding Benchmark for Clinical GUI
Mar 20, 2026Despite the rapid progress of Multimodal Large Language Models (MLLMs), their ability to perform reliable visual grounding in high-stakes clinical software environments remains underexplored. Existing GUI benchmarks largely focus on isolated, single-step grounding queries, overlooking the sequential, workflow-driven reasoning required in real-world medical interfaces, where tasks evolve across independent steps and dynamic interface states. We introduce MedSPOT, a workflow-aware sequential grounding benchmark for clinical GUI environments. Unlike prior benchmarks that treat grounding as a standalone prediction task, MedSPOT models procedural interaction as a sequence of structured spatial decisions. The benchmark comprises 216 task-driven videos with 597 annotated keyframes, in which each task consists of 2 to 3 interdependent grounding steps within realistic medical workflows. This design captures interface hierarchies, contextual dependencies, and fine-grained spatial precision under evolving conditions. To evaluate procedural robustness, we propose a strict sequential evaluation protocol that terminates task assessment upon the first incorrect grounding prediction, explicitly measuring error propagation in multi-step workflows. We further introduce a comprehensive failure taxonomy, including edge bias, small-target errors, no prediction, near miss, far miss, and toolbar confusion, to enable systematic diagnosis of model behavior in clinical GUI settings. By shifting evaluation from isolated grounding to workflow-aware sequential reasoning, MedSPOT establishes a realistic and safety-critical benchmark for assessing multimodal models in medical software environments. Code and data are available at: https://github.com/Tajamul21/MedSPOT.
Insights into the Lottery Ticket Hypothesis and Iterative Magnitude Pruning
Mar 27, 2024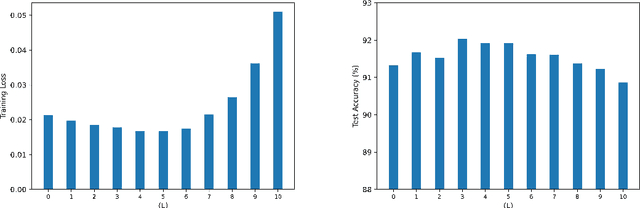
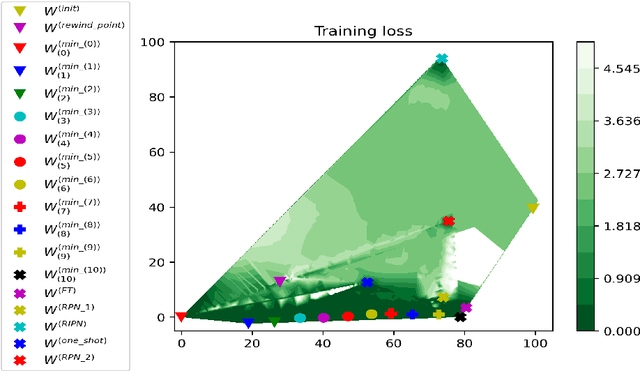
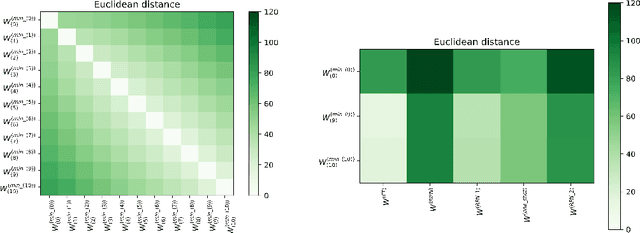
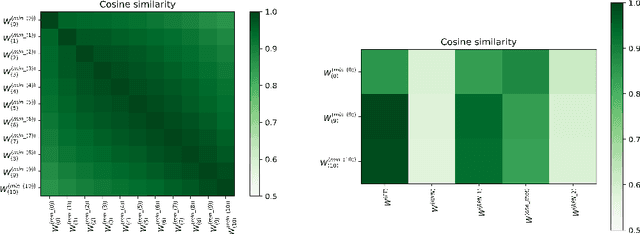
Lottery ticket hypothesis for deep neural networks emphasizes the importance of initialization used to re-train the sparser networks obtained using the iterative magnitude pruning process. An explanation for why the specific initialization proposed by the lottery ticket hypothesis tends to work better in terms of generalization (and training) performance has been lacking. Moreover, the underlying principles in iterative magnitude pruning, like the pruning of smaller magnitude weights and the role of the iterative process, lack full understanding and explanation. In this work, we attempt to provide insights into these phenomena by empirically studying the volume/geometry and loss landscape characteristics of the solutions obtained at various stages of the iterative magnitude pruning process.
Distilling Inductive Bias: Knowledge Distillation Beyond Model Compression
Oct 10, 2023
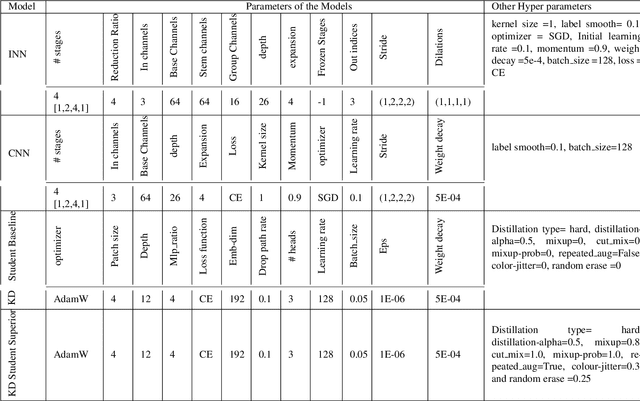

With the rapid development of computer vision, Vision Transformers (ViTs) offer the tantalizing prospect of unified information processing across visual and textual domains. But due to the lack of inherent inductive biases in ViTs, they require enormous amount of data for training. To make their applications practical, we introduce an innovative ensemble-based distillation approach distilling inductive bias from complementary lightweight teacher models. Prior systems relied solely on convolution-based teaching. However, this method incorporates an ensemble of light teachers with different architectural tendencies, such as convolution and involution, to instruct the student transformer jointly. Because of these unique inductive biases, instructors can accumulate a wide range of knowledge, even from readily identifiable stored datasets, which leads to enhanced student performance. Our proposed framework also involves precomputing and storing logits in advance, essentially the unnormalized predictions of the model. This optimization can accelerate the distillation process by eliminating the need for repeated forward passes during knowledge distillation, significantly reducing the computational burden and enhancing efficiency.
Knowledge Distillation in Vision Transformers: A Critical Review
Feb 04, 2023
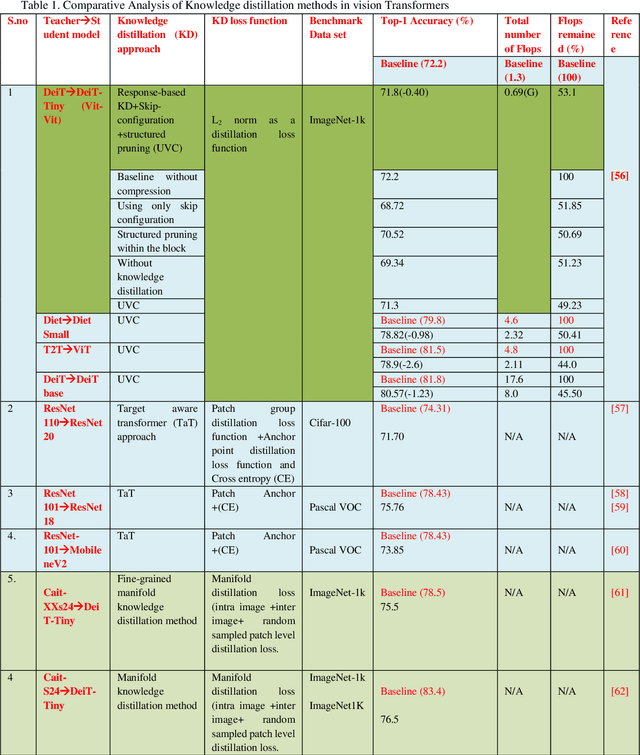
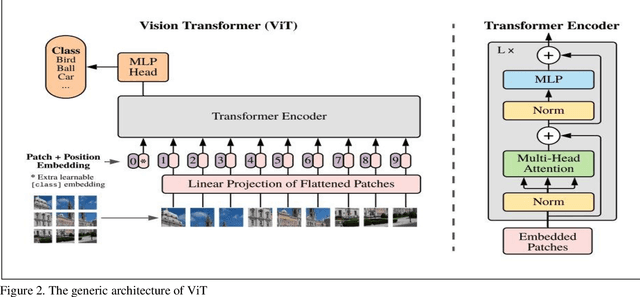
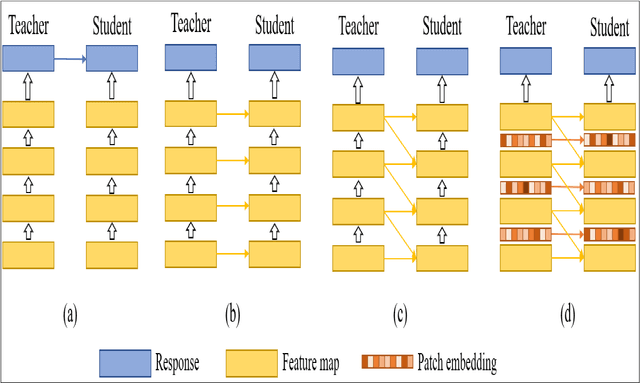
In Natural Language Processing (NLP), Transformers have already revolutionized the field by utilizing an attention-based encoder-decoder model. Recently, some pioneering works have employed Transformer-like architectures in Computer Vision (CV) and they have reported outstanding performance of these architectures in tasks such as image classification, object detection, and semantic segmentation. Vision Transformers (ViTs) have demonstrated impressive performance improvements over Convolutional Neural Networks (CNNs) due to their competitive modelling capabilities. However, these architectures demand massive computational resources which makes these models difficult to be deployed in the resource-constrained applications. Many solutions have been developed to combat this issue, such as compressive transformers and compression functions such as dilated convolution, min-max pooling, 1D convolution, etc. Model compression has recently attracted considerable research attention as a potential remedy. A number of model compression methods have been proposed in the literature such as weight quantization, weight multiplexing, pruning and Knowledge Distillation (KD). However, techniques like weight quantization, pruning and weight multiplexing typically involve complex pipelines for performing the compression. KD has been found to be a simple and much effective model compression technique that allows a relatively simple model to perform tasks almost as accurately as a complex model. This paper discusses various approaches based upon KD for effective compression of ViT models. The paper elucidates the role played by KD in reducing the computational and memory requirements of these models. The paper also presents the various challenges faced by ViTs that are yet to be resolved.