 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing The Power of Attention For Patch-Based Biomedical Image Classification
Apr 01, 2024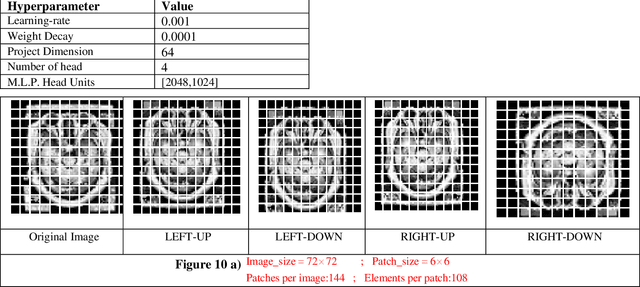
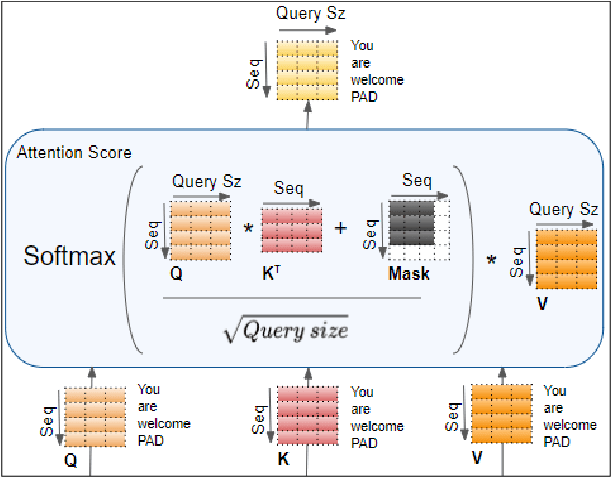
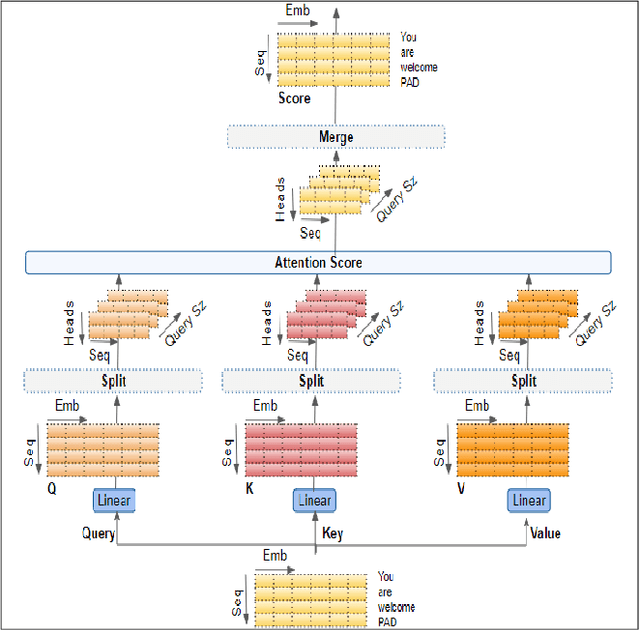
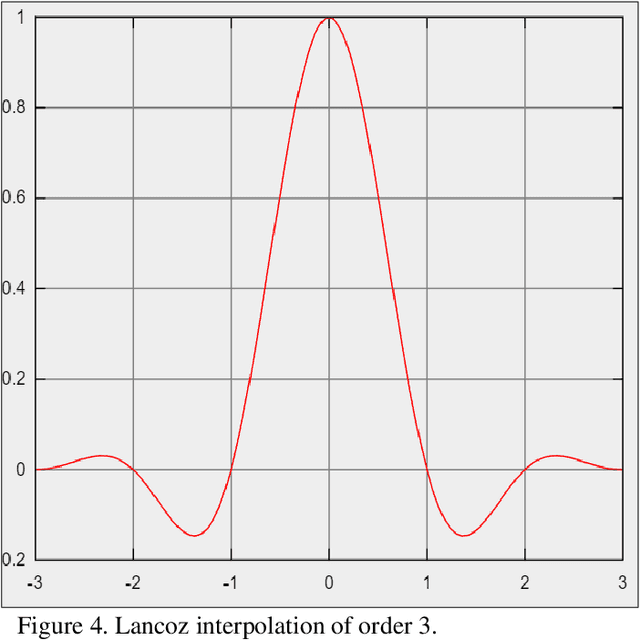
Biomedical image analysis can be facilitated by an innovative architecture rooted in self-attention mechanisms. The traditional convolutional neural network (CNN), characterized by fixed-sized windows, needs help capturing intricate spatial and temporal relations at the pixel level. The immutability of CNN filter weights post-training further restricts input fluctuations. Recognizing these limitations, we propose a new paradigm of attention-based models instead of convolutions. As an alternative to traditional CNNs, these models demonstrate robust modelling capabilities and the ability to grasp comprehensive long-range contextual information efficiently. Providing a solution to critical challenges faced by attention-based vision models such as inductive bias, weight sharing, receptive field limitations, and data handling in high resolution, our work combines non-overlapping (vanilla patching) with novel overlapped Shifted Patching Techniques (S.P.T.s) to induce local context that enhances model generalization. Moreover, we examine the novel Lancoz5 interpolation technique, which adapts variable image sizes to higher resolutions. Experimental evidence validates our model's generalization effectiveness, comparing favourably with existing approaches. Attention-based methods are particularly effective with ample data, especially when advanced data augmentation methodologies are integrated to strengthen their robustness.
Exploring the Efficacy of Group-Normalization in Deep Learning Models for Alzheimer's Disease Classification
Apr 01, 2024



Batch Normalization is an important approach to advancing deep learning since it allows multiple networks to train simultaneously. A problem arises when normalizing along the batch dimension because B.N.'s error increases significantly as batch size shrinks because batch statistics estimates are inaccurate. As a result, computer vision tasks like detection, segmentation, and video, which require tiny batches based on memory consumption, aren't suitable for using Batch Normalization for larger model training and feature transfer. Here, we explore Group Normalization as an easy alternative to using Batch Normalization A Group Normalization is a channel normalization method in which each group is divided into different channels, and the corresponding mean and variance are calculated for each group. Group Normalization computations are accurate across a wide range of batch sizes and are independent of batch size. When trained using a large ImageNet database on ResNet-50, GN achieves a very low error rate of 10.6% compared to Batch Normalization. when a smaller batch size of only 2 is used. For usual batch sizes, the performance of G.N. is comparable to that of Batch Normalization, but at the same time, it outperforms other normalization techniques. Implementing Group Normalization as a direct alternative to B.N to combat the serious challenges faced by the Batch Normalization in deep learning models with comparable or improved classification accuracy. Additionally, Group Normalization can be naturally transferred from the pre-training to the fine-tuning phase. .