 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Survey and Benchmark of Learned Distance Indexes for Road Networks
Feb 03, 2026The calculation of shortest-path distances in road networks is a core operation in navigation systems, location-based services, and spatial analytics. Although classical algorithms, e.g., Dijkstra's algorithm, provide exact answers, their latency is prohibitive for modern real-time, large-scale deployments. Over the past two decades, numerous distance indexes have been proposed to speed up query processing for shortest distance queries. More recently, with the advancement in machine learning (ML), researchers have designed and proposed ML-based distance indexes to answer approximate shortest path and distance queries efficiently. However, a comprehensive and systematic evaluation of these ML-based approaches is lacking. This paper presents the first empirical survey of ML-based distance indexes on road networks, evaluating them along four key dimensions: Training time, query latency, storage, and accuracy. Using seven real-world road networks and workload-driven query datasets derived from trajectory data, we benchmark ten representative ML techniques and compare them against strong classical non-ML baselines, highlighting key insights and practical trade-offs. We release a unified open-source codebase to support reproducibility and future research on learned distance indexes.
P-MOSS: Learned Scheduling For Indexes Over NUMA Servers Using Low-Level Hardware Statistics
Nov 05, 2024


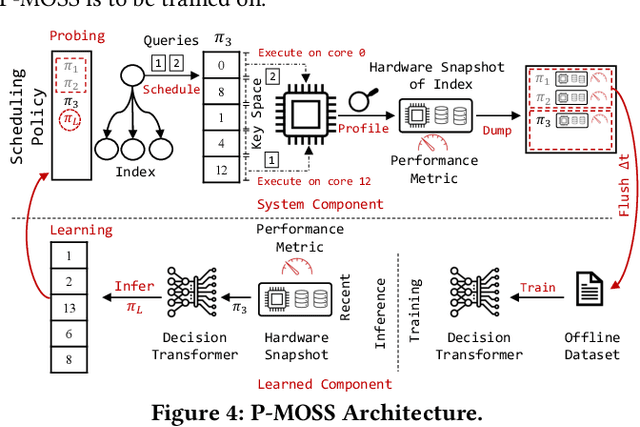
Ever since the Dennard scaling broke down in the early 2000s and the frequency of the CPU stalled, vendors have started to increase the core count in each CPU chip at the expense of introducing heterogeneity, thus ushering the era of NUMA processors. Since then, the heterogeneity in the design space of hardware has only increased to the point that DBMS performance may vary significantly up to an order of magnitude in modern servers. An important factor that affects performance includes the location of the logical cores where the DBMS queries are scheduled, and the locations of the data that the queries access. This paper introduces P-MOSS, a learned spatial scheduling framework that schedules query execution to certain logical cores, and places data accordingly to certain integrated memory controllers (IMC), to integrate hardware consciousness into the system. In the spirit of hardware-software synergy, P-MOSS solely guides its scheduling decision based on low-level hardware statistics collected by performance monitoring counters with the aid of a Decision Transformer. Experimental evaluation is performed in the context of the B-tree and R-tree indexes. Performance results demonstrate that P-MOSS has up to 6x improvement over traditional schedules in terms of query throughput.
A Survey of Learned Indexes for the Multi-dimensional Space
Mar 11, 2024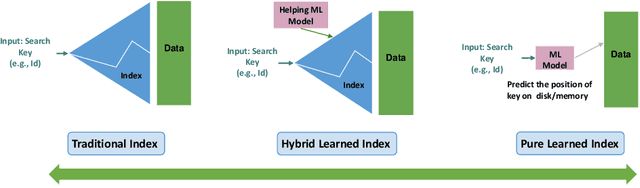


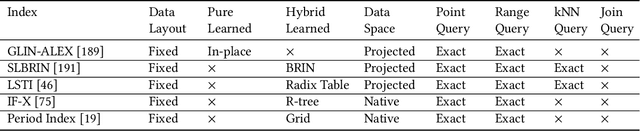
A recent research trend involves treating database index structures as Machine Learning (ML) models. In this domain, single or multiple ML models are trained to learn the mapping from keys to positions inside a data set. This class of indexes is known as "Learned Indexes." Learned indexes have demonstrated improved search performance and reduced space requirements for one-dimensional data. The concept of one-dimensional learned indexes has naturally been extended to multi-dimensional (e.g., spatial) data, leading to the development of "Learned Multi-dimensional Indexes". This survey focuses on learned multi-dimensional index structures. Specifically, it reviews the current state of this research area, explains the core concepts behind each proposed method, and classifies these methods based on several well-defined criteria. We present a taxonomy that classifies and categorizes each learned multi-dimensional index, and survey the existing literature on learned multi-dimensional indexes according to this taxonomy. Additionally, we present a timeline to illustrate the evolution of research on learned indexes. Finally, we highlight several open challenges and future research directions in this emerging and highly active field.
The "AI+R"-tree: An Instance-optimized R-tree
Jul 01, 2022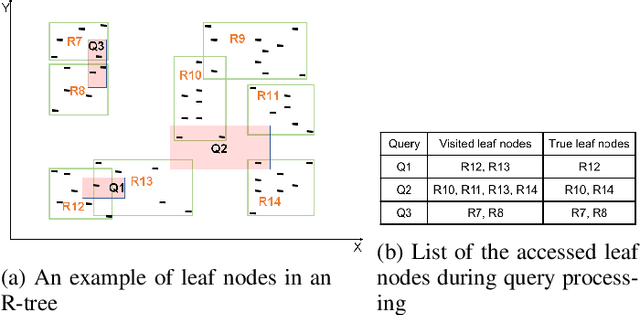

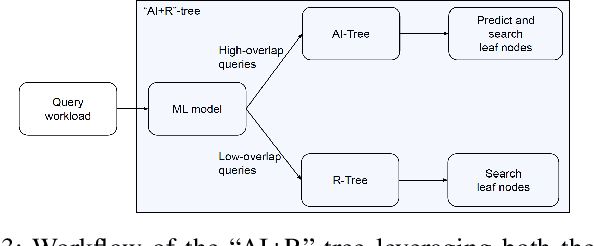
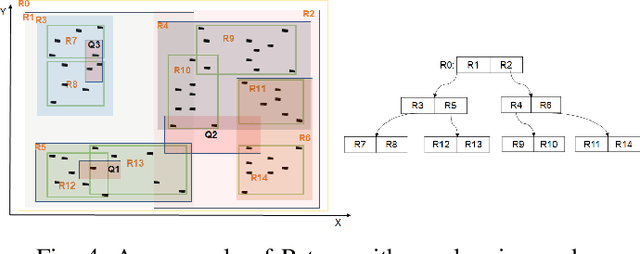
The emerging class of instance-optimized systems has shown potential to achieve high performance by specializing to a specific data and query workloads. Particularly, Machine Learning (ML) techniques have been applied successfully to build various instance-optimized components (e.g., learned indexes). This paper investigates to leverage ML techniques to enhance the performance of spatial indexes, particularly the R-tree, for a given data and query workloads. As the areas covered by the R-tree index nodes overlap in space, upon searching for a specific point in space, multiple paths from root to leaf may potentially be explored. In the worst case, the entire R-tree could be searched. In this paper, we define and use the overlap ratio to quantify the degree of extraneous leaf node accesses required by a range query. The goal is to enhance the query performance of a traditional R-tree for high-overlap range queries as they tend to incur long running-times. We introduce a new AI-tree that transforms the search operation of an R-tree into a multi-label classification task to exclude the extraneous leaf node accesses. Then, we augment a traditional R-tree to the AI-tree to form a hybrid "AI+R"-tree. The "AI+R"-tree can automatically differentiate between the high- and low-overlap queries using a learned model. Thus, the "AI+R"-tree processes high-overlap queries using the AI-tree, and the low-overlap queries using the R-tree. Experiments on real datasets demonstrate that the "AI+R"-tree can enhance the query performance over a traditional R-tree by up to 500%.