 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Lexical Irregularities in Hypothesis-Only Models of Natural Language Inference
Paper and Code

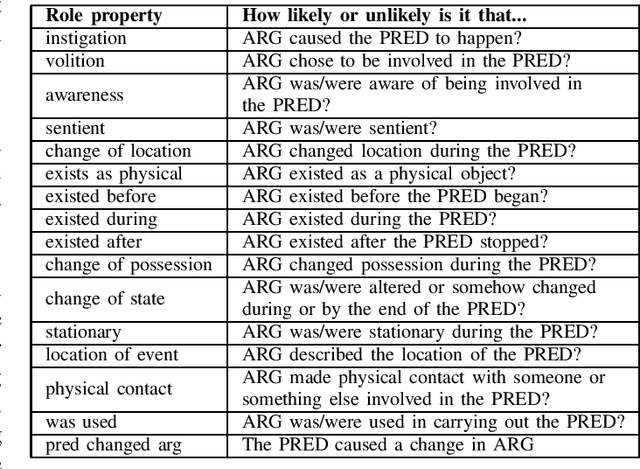
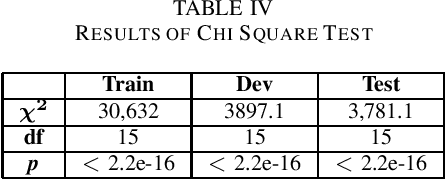
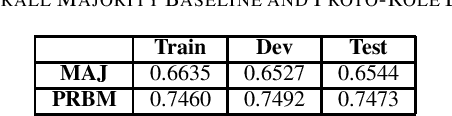
Natural Language Inference (NLI) or Recognizing Textual Entailment (RTE) is the task of predicting the entailment relation between a pair of sentences (premise and hypothesis). This task has been described as a valuable testing ground for the development of semantic representations, and is a key component in natural language understanding evaluation benchmarks. Models that understand entailment should encode both, the premise and the hypothesis. However, experiments by Poliak et al. revealed a strong preference of these models towards patterns observed only in the hypothesis, based on a 10 dataset comparison. Their results indicated the existence of statistical irregularities present in the hypothesis that bias the model into performing competitively with the state of the art. While recast datasets provide large scale generation of NLI instances due to minimal human intervention, the papers that generate them do not provide fine-grained analysis of the potential statistical patterns that can bias NLI models. In this work, we analyze hypothesis-only models trained on one of the recast datasets provided in Poliak et al. for word-level patterns. Our results indicate the existence of potential lexical biases that could contribute to inflating the model performance.