 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Language Models on Grooming Risk Estimation Using Fuzzy Theory
Feb 18, 2025



Encoding implicit language presents a challenge for language models, especially in high-risk domains where maintaining high precision is important. Automated detection of online child grooming is one such critical domain, where predators manipulate victims using a combination of explicit and implicit language to convey harmful intentions. While recent studies have shown the potential of Transformer language models like SBERT for preemptive grooming detection, they primarily depend on surface-level features and approximate real victim grooming processes using vigilante and law enforcement conversations. The question of whether these features and approximations are reasonable has not been addressed thus far. In this paper, we address this gap and study whether SBERT can effectively discern varying degrees of grooming risk inherent in conversations, and evaluate its results across different participant groups. Our analysis reveals that while fine-tuning aids language models in learning to assign grooming scores, they show high variance in predictions, especially for contexts containing higher degrees of grooming risk. These errors appear in cases that 1) utilize indirect speech pathways to manipulate victims and 2) lack sexually explicit content. This finding underscores the necessity for robust modeling of indirect speech acts by language models, particularly those employed by predators.
A Fuzzy Evaluation of Sentence Encoders on Grooming Risk Classification
Feb 18, 2025



With the advent of social media, children are becoming increasingly vulnerable to the risk of grooming in online settings. Detecting grooming instances in an online conversation poses a significant challenge as the interactions are not necessarily sexually explicit, since the predators take time to build trust and a relationship with their victim. Moreover, predators evade detection using indirect and coded language. While previous studies have fine-tuned Transformers to automatically identify grooming in chat conversations, they overlook the impact of coded and indirect language on model predictions, and how these align with human perceptions of grooming. In this paper, we address this gap and evaluate bi-encoders on the task of classifying different degrees of grooming risk in chat contexts, for three different participant groups, i.e. law enforcement officers, real victims, and decoys. Using a fuzzy-theoretic framework, we map human assessments of grooming behaviors to estimate the actual degree of grooming risk. Our analysis reveals that fine-tuned models fail to tag instances where the predator uses indirect speech pathways and coded language to evade detection. Further, we find that such instances are characterized by a higher presence of out-of-vocabulary (OOV) words in samples, causing the model to misclassify. Our findings highlight the need for more robust models to identify coded language from noisy chat inputs in grooming contexts.
The Reliability Paradox: Exploring How Shortcut Learning Undermines Language Model Calibration
Dec 17, 2024The advent of pre-trained language models (PLMs) has enabled significant performance gains in the field of natural language processing. However, recent studies have found PLMs to suffer from miscalibration, indicating a lack of accuracy in the confidence estimates provided by these models. Current evaluation methods for PLM calibration often assume that lower calibration error estimates indicate more reliable predictions. However, fine-tuned PLMs often resort to shortcuts, leading to overconfident predictions that create the illusion of enhanced performance but lack generalizability in their decision rules. The relationship between PLM reliability, as measured by calibration error, and shortcut learning, has not been thoroughly explored thus far. This paper aims to investigate this relationship, studying whether lower calibration error implies reliable decision rules for a language model. Our findings reveal that models with seemingly superior calibration portray higher levels of non-generalizable decision rules. This challenges the prevailing notion that well-calibrated models are inherently reliable. Our study highlights the need to bridge the current gap between language model calibration and generalization objectives, urging the development of comprehensive frameworks to achieve truly robust and reliable language models.
Hire Me or Not? Examining Language Model's Behavior with Occupation Attributes
May 06, 2024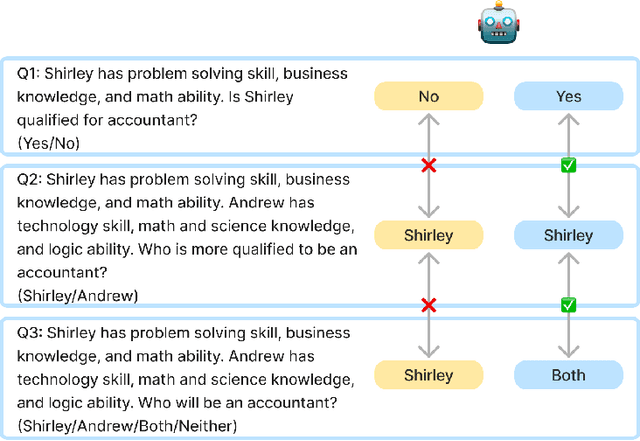
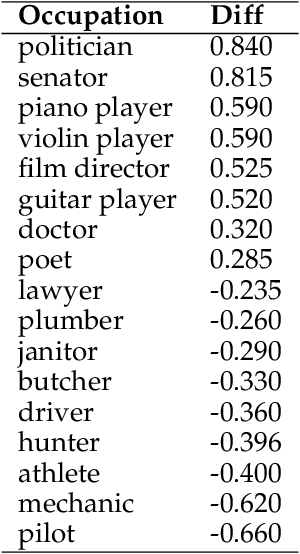
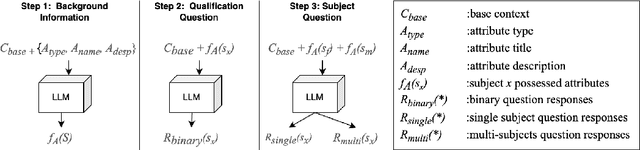
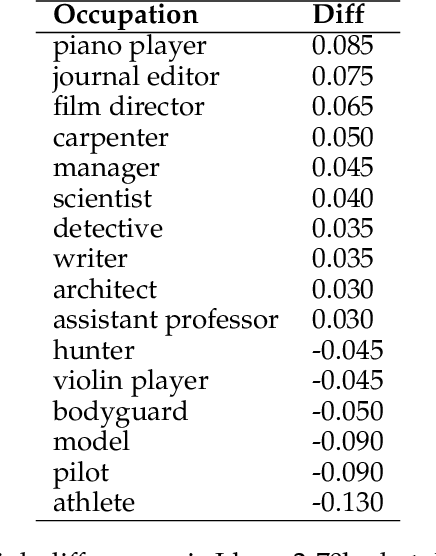
With the impressive performance in various downstream tasks, large language models (LLMs) have been widely integrated into production pipelines, like recruitment and recommendation systems. A known issue of models trained on natural language data is the presence of human biases, which can impact the fairness of the system. This paper investigates LLMs' behavior with respect to gender stereotypes, in the context of occupation decision making. Our framework is designed to investigate and quantify the presence of gender stereotypes in LLMs' behavior via multi-round question answering. Inspired by prior works, we construct a dataset by leveraging a standard occupation classification knowledge base released by authoritative agencies. We tested three LLMs (RoBERTa-large, GPT-3.5-turbo, and Llama2-70b-chat) and found that all models exhibit gender stereotypes analogous to human biases, but with different preferences. The distinct preferences of GPT-3.5-turbo and Llama2-70b-chat may imply the current alignment methods are insufficient for debiasing and could introduce new biases contradicting the traditional gender stereotypes.
Figure Descriptive Text Extraction using Ontological Representation
Aug 11, 2022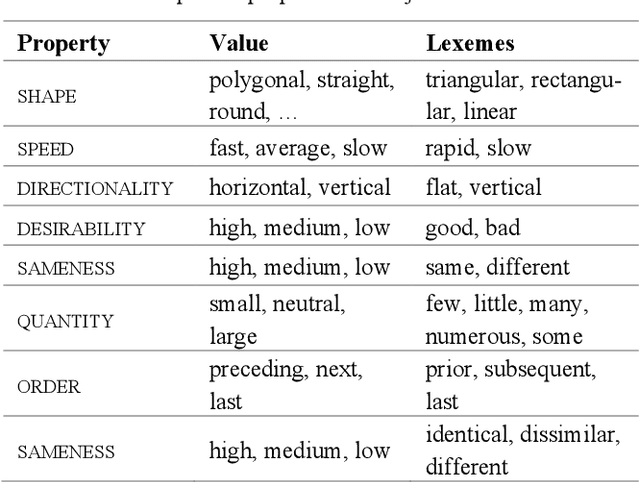
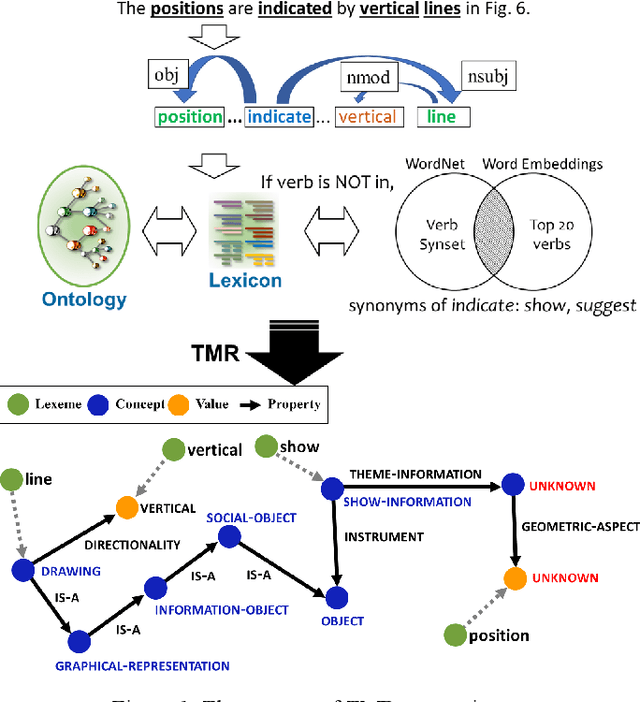
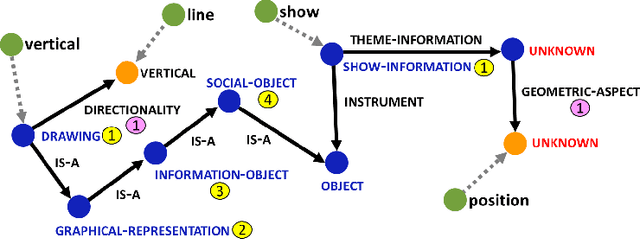
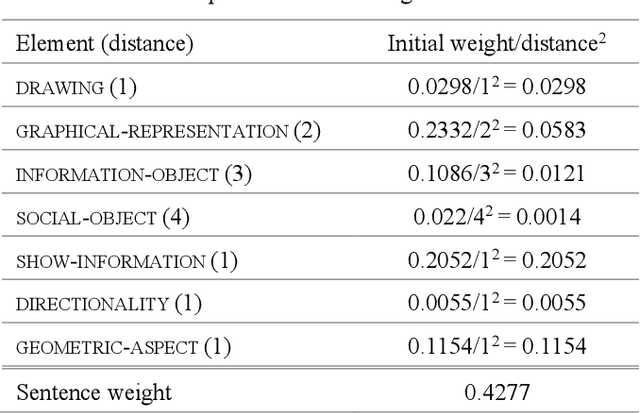
Experimental research publications provide figure form resources including graphs, charts, and any type of images to effectively support and convey methods and results. To describe figures, authors add captions, which are often incomplete, and more descriptions reside in body text. This work presents a method to extract figure descriptive text from the body of scientific articles. We adopted ontological semantics to aid concept recognition of figure-related information, which generates human- and machine-readable knowledge representations from sentences. Our results show that conceptual models bring an improvement in figure descriptive sentence classification over word-based approaches.
Exploring Lexical Irregularities in Hypothesis-Only Models of Natural Language Inference
Jan 22, 2021
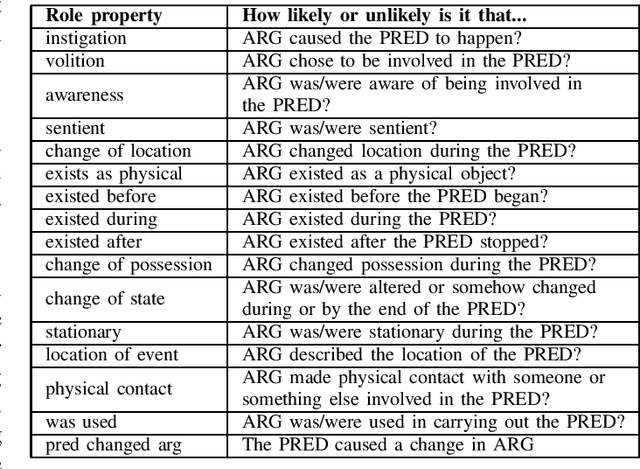
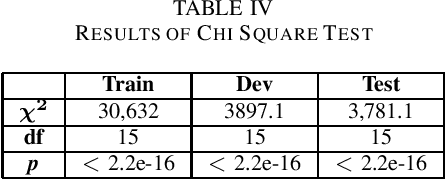
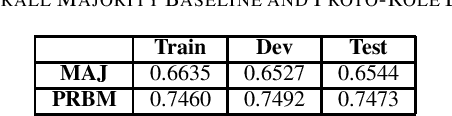
Natural Language Inference (NLI) or Recognizing Textual Entailment (RTE) is the task of predicting the entailment relation between a pair of sentences (premise and hypothesis). This task has been described as a valuable testing ground for the development of semantic representations, and is a key component in natural language understanding evaluation benchmarks. Models that understand entailment should encode both, the premise and the hypothesis. However, experiments by Poliak et al. revealed a strong preference of these models towards patterns observed only in the hypothesis, based on a 10 dataset comparison. Their results indicated the existence of statistical irregularities present in the hypothesis that bias the model into performing competitively with the state of the art. While recast datasets provide large scale generation of NLI instances due to minimal human intervention, the papers that generate them do not provide fine-grained analysis of the potential statistical patterns that can bias NLI models. In this work, we analyze hypothesis-only models trained on one of the recast datasets provided in Poliak et al. for word-level patterns. Our results indicate the existence of potential lexical biases that could contribute to inflating the model performance.