 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Language Models on Grooming Risk Estimation Using Fuzzy Theory
Feb 18, 2025



Encoding implicit language presents a challenge for language models, especially in high-risk domains where maintaining high precision is important. Automated detection of online child grooming is one such critical domain, where predators manipulate victims using a combination of explicit and implicit language to convey harmful intentions. While recent studies have shown the potential of Transformer language models like SBERT for preemptive grooming detection, they primarily depend on surface-level features and approximate real victim grooming processes using vigilante and law enforcement conversations. The question of whether these features and approximations are reasonable has not been addressed thus far. In this paper, we address this gap and study whether SBERT can effectively discern varying degrees of grooming risk inherent in conversations, and evaluate its results across different participant groups. Our analysis reveals that while fine-tuning aids language models in learning to assign grooming scores, they show high variance in predictions, especially for contexts containing higher degrees of grooming risk. These errors appear in cases that 1) utilize indirect speech pathways to manipulate victims and 2) lack sexually explicit content. This finding underscores the necessity for robust modeling of indirect speech acts by language models, particularly those employed by predators.
A Fuzzy Evaluation of Sentence Encoders on Grooming Risk Classification
Feb 18, 2025



With the advent of social media, children are becoming increasingly vulnerable to the risk of grooming in online settings. Detecting grooming instances in an online conversation poses a significant challenge as the interactions are not necessarily sexually explicit, since the predators take time to build trust and a relationship with their victim. Moreover, predators evade detection using indirect and coded language. While previous studies have fine-tuned Transformers to automatically identify grooming in chat conversations, they overlook the impact of coded and indirect language on model predictions, and how these align with human perceptions of grooming. In this paper, we address this gap and evaluate bi-encoders on the task of classifying different degrees of grooming risk in chat contexts, for three different participant groups, i.e. law enforcement officers, real victims, and decoys. Using a fuzzy-theoretic framework, we map human assessments of grooming behaviors to estimate the actual degree of grooming risk. Our analysis reveals that fine-tuned models fail to tag instances where the predator uses indirect speech pathways and coded language to evade detection. Further, we find that such instances are characterized by a higher presence of out-of-vocabulary (OOV) words in samples, causing the model to misclassify. Our findings highlight the need for more robust models to identify coded language from noisy chat inputs in grooming contexts.
The Reliability Paradox: Exploring How Shortcut Learning Undermines Language Model Calibration
Dec 17, 2024The advent of pre-trained language models (PLMs) has enabled significant performance gains in the field of natural language processing. However, recent studies have found PLMs to suffer from miscalibration, indicating a lack of accuracy in the confidence estimates provided by these models. Current evaluation methods for PLM calibration often assume that lower calibration error estimates indicate more reliable predictions. However, fine-tuned PLMs often resort to shortcuts, leading to overconfident predictions that create the illusion of enhanced performance but lack generalizability in their decision rules. The relationship between PLM reliability, as measured by calibration error, and shortcut learning, has not been thoroughly explored thus far. This paper aims to investigate this relationship, studying whether lower calibration error implies reliable decision rules for a language model. Our findings reveal that models with seemingly superior calibration portray higher levels of non-generalizable decision rules. This challenges the prevailing notion that well-calibrated models are inherently reliable. Our study highlights the need to bridge the current gap between language model calibration and generalization objectives, urging the development of comprehensive frameworks to achieve truly robust and reliable language models.
Hire Me or Not? Examining Language Model's Behavior with Occupation Attributes
May 06, 2024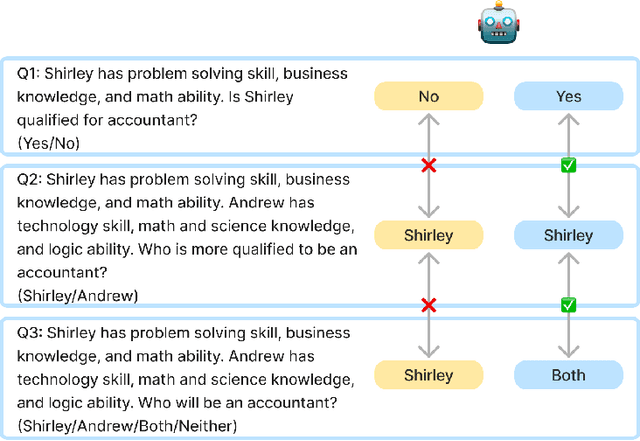
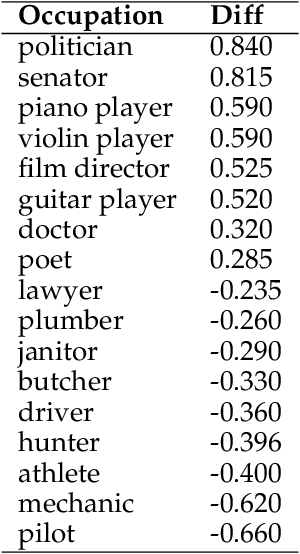
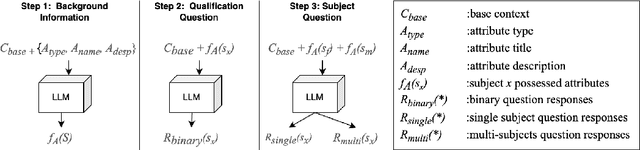
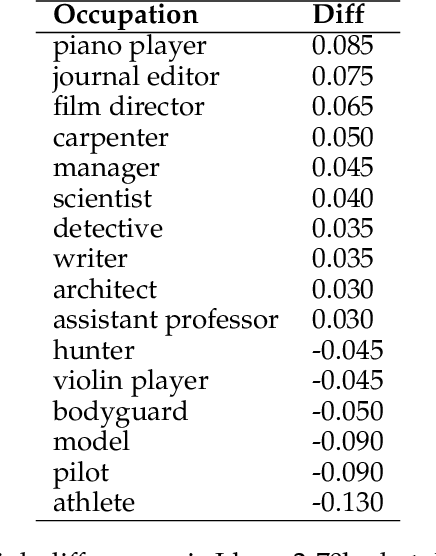
With the impressive performance in various downstream tasks, large language models (LLMs) have been widely integrated into production pipelines, like recruitment and recommendation systems. A known issue of models trained on natural language data is the presence of human biases, which can impact the fairness of the system. This paper investigates LLMs' behavior with respect to gender stereotypes, in the context of occupation decision making. Our framework is designed to investigate and quantify the presence of gender stereotypes in LLMs' behavior via multi-round question answering. Inspired by prior works, we construct a dataset by leveraging a standard occupation classification knowledge base released by authoritative agencies. We tested three LLMs (RoBERTa-large, GPT-3.5-turbo, and Llama2-70b-chat) and found that all models exhibit gender stereotypes analogous to human biases, but with different preferences. The distinct preferences of GPT-3.5-turbo and Llama2-70b-chat may imply the current alignment methods are insufficient for debiasing and could introduce new biases contradicting the traditional gender stereotypes.
Learning Shortcuts: On the Misleading Promise of NLU in Language Models
Jan 17, 2024The advent of large language models (LLMs) has enabled significant performance gains in the field of natural language processing. However, recent studies have found that LLMs often resort to shortcuts when performing tasks, creating an illusion of enhanced performance while lacking generalizability in their decision rules. This phenomenon introduces challenges in accurately assessing natural language understanding in LLMs. Our paper provides a concise survey of relevant research in this area and puts forth a perspective on the implications of shortcut learning in the evaluation of language models, specifically for NLU tasks. This paper urges more research efforts to be put towards deepening our comprehension of shortcut learning, contributing to the development of more robust language models, and raising the standards of NLU evaluation in real-world scenarios.
Calibration Error Estimation Using Fuzzy Binning
May 08, 2023



Neural network-based decisions tend to be overconfident, where their raw outcome probabilities do not align with the true decision probabilities. Calibration of neural networks is an essential step towards more reliable deep learning frameworks. Prior metrics of calibration error primarily utilize crisp bin membership-based measures. This exacerbates skew in model probabilities and portrays an incomplete picture of calibration error. In this work, we propose a Fuzzy Calibration Error metric (FCE) that utilizes a fuzzy binning approach to calculate calibration error. This approach alleviates the impact of probability skew and provides a tighter estimate while measuring calibration error. We compare our metric with ECE across different data populations and class memberships. Our results show that FCE offers better calibration error estimation, especially in multi-class settings, alleviating the effects of skew in model confidence scores on calibration error estimation. We make our code and supplementary materials available at: https://github.com/bihani-g/fce
On Information Hiding in Natural Language Systems
Mar 12, 2022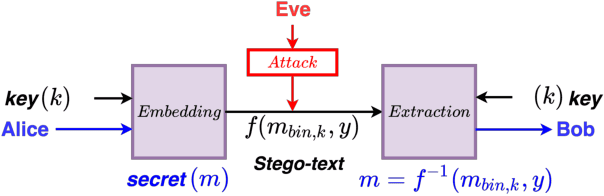
With data privacy becoming more of a necessity than a luxury in today's digital world, research on more robust models of privacy preservation and information security is on the rise. In this paper, we take a look at Natural Language Steganography (NLS) methods, which perform information hiding in natural language systems, as a means to achieve data security as well as confidentiality. We summarize primary challenges regarding the secrecy and imperceptibility requirements of these systems and propose potential directions of improvement, specifically targeting steganographic text quality. We believe that this study will act as an appropriate framework to build more resilient models of Natural Language Steganography, working towards instilling security within natural language-based neural models.
Interpretable Privacy Preservation of Text Representations Using Vector Steganography
Dec 07, 2021
Contextual word representations generated by language models (LMs) learn spurious associations present in the training corpora. Recent findings reveal that adversaries can exploit these associations to reverse-engineer the private attributes of entities mentioned within the corpora. These findings have led to efforts towards minimizing the privacy risks of language models. However, existing approaches lack interpretability, compromise on data utility and fail to provide privacy guarantees. Thus, the goal of my doctoral research is to develop interpretable approaches towards privacy preservation of text representations that retain data utility while guaranteeing privacy. To this end, I aim to study and develop methods to incorporate steganographic modifications within the vector geometry to obfuscate underlying spurious associations and preserve the distributional semantic properties learnt during training.
Low Anisotropy Sense Retrofitting (LASeR) : Towards Isotropic and Sense Enriched Representations
Apr 22, 2021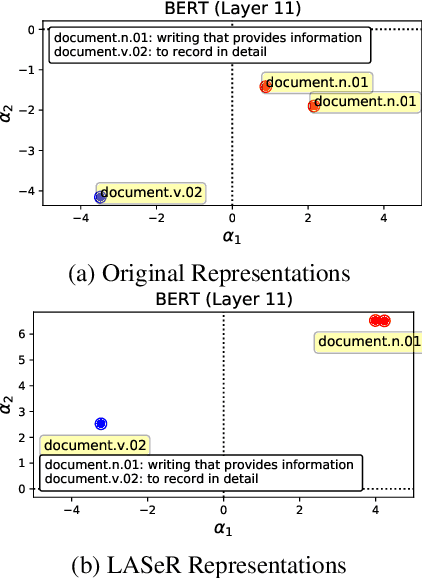
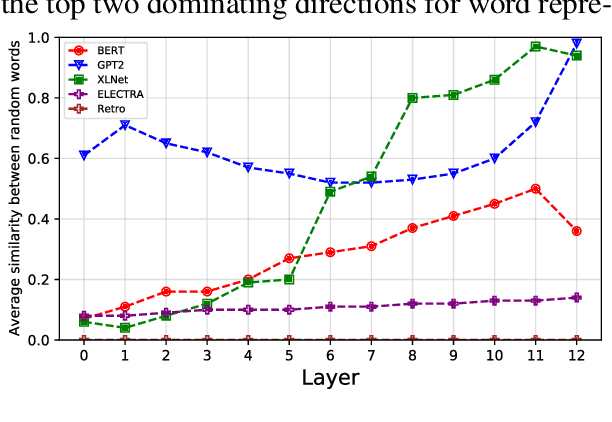
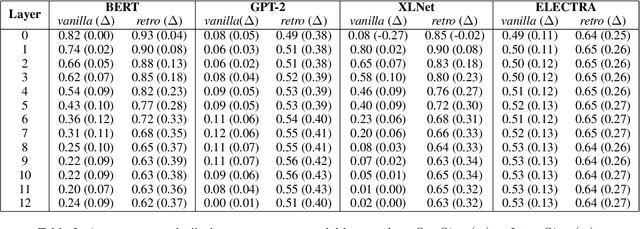
Contextual word representation models have shown massive improvements on a multitude of NLP tasks, yet their word sense disambiguation capabilities remain poorly explained. To address this gap, we assess whether contextual word representations extracted from deep pretrained language models create distinguishable representations for different senses of a given word. We analyze the representation geometry and find that most layers of deep pretrained language models create highly anisotropic representations, pointing towards the existence of representation degeneration problem in contextual word representations. After accounting for anisotropy, our study further reveals that there is variability in sense learning capabilities across different language models. Finally, we propose LASeR, a 'Low Anisotropy Sense Retrofitting' approach that renders off-the-shelf representations isotropic and semantically more meaningful, resolving the representation degeneration problem as a post-processing step, and conducting sense-enrichment of contextualized representations extracted from deep neural language models.
Fuzzy Classification of Multi-intent Utterances
Apr 22, 2021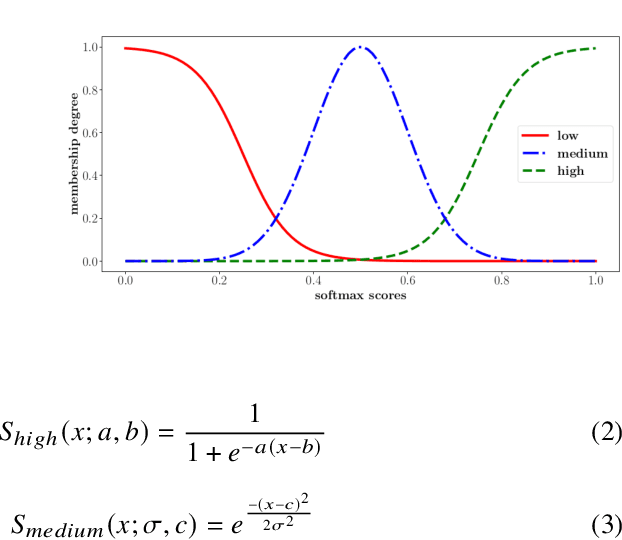
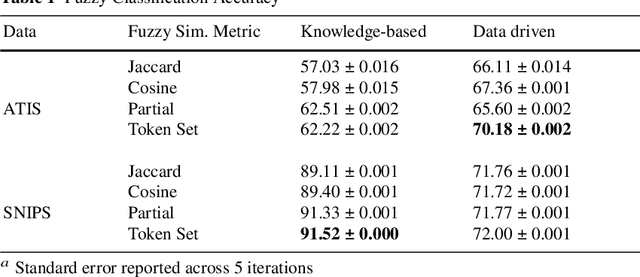
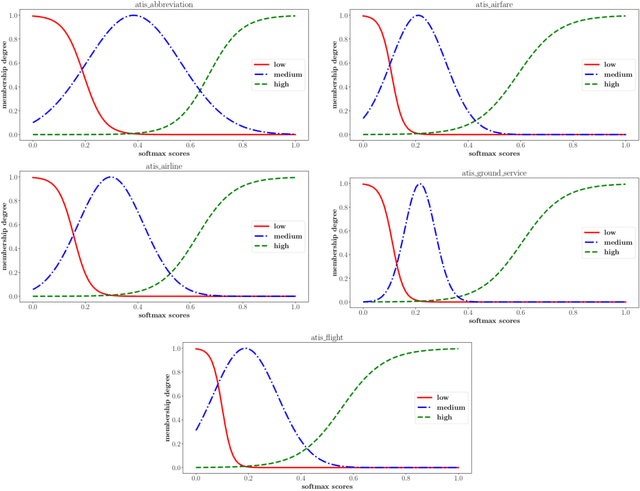
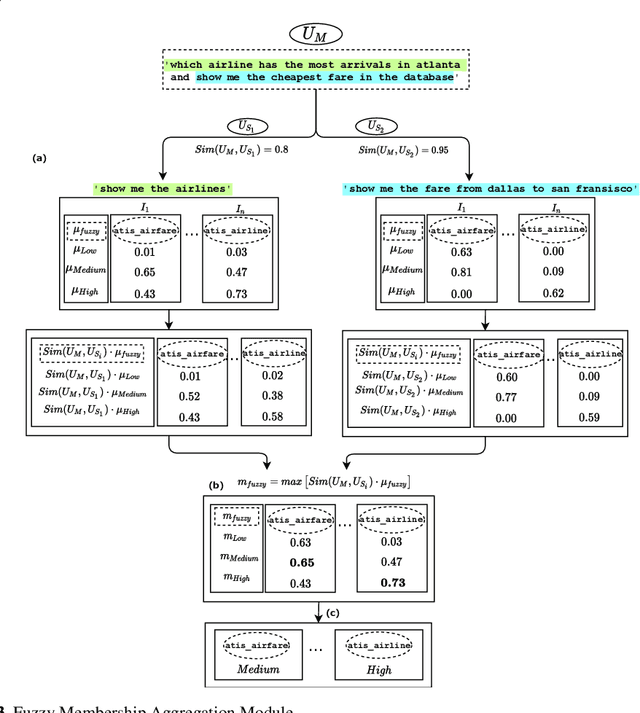
Current intent classification approaches assign binary intent class memberships to natural language utterances while disregarding the inherent vagueness in language and the corresponding vagueness in intent class boundaries. In this work, we propose a scheme to address the ambiguity in single-intent as well as multi-intent natural language utterances by creating degree memberships over fuzzified intent classes. To our knowledge, this is the first work to address and quantify the impact of the fuzzy nature of natural language utterances over intent category memberships. Additionally, our approach overcomes the sparsity of multi-intent utterance data to train classification models by using a small database of single intent utterances to generate class memberships over multi-intent utterances. We evaluate our approach over two task-oriented dialog datasets, across different fuzzy membership generation techniques and approximate string similarity measures. Our results reveal the impact of lexical overlap between utterances of different intents, and the underlying data distributions, on the fuzzification of intent memberships. Moreover, we evaluate the accuracy of our approach by comparing the defuzzified memberships to their binary counterparts, across different combinations of membership functions and string similarity measures.