 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Information Hiding in Natural Language Systems
Paper and Code
Mar 12, 2022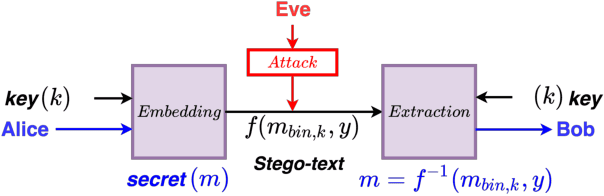
With data privacy becoming more of a necessity than a luxury in today's digital world, research on more robust models of privacy preservation and information security is on the rise. In this paper, we take a look at Natural Language Steganography (NLS) methods, which perform information hiding in natural language systems, as a means to achieve data security as well as confidentiality. We summarize primary challenges regarding the secrecy and imperceptibility requirements of these systems and propose potential directions of improvement, specifically targeting steganographic text quality. We believe that this study will act as an appropriate framework to build more resilient models of Natural Language Steganography, working towards instilling security within natural language-based neural models.