 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Privacy Preservation of Text Representations Using Vector Steganography
Paper and Code
Dec 07, 2021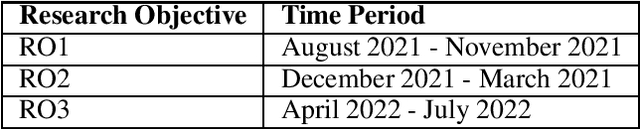
Contextual word representations generated by language models (LMs) learn spurious associations present in the training corpora. Recent findings reveal that adversaries can exploit these associations to reverse-engineer the private attributes of entities mentioned within the corpora. These findings have led to efforts towards minimizing the privacy risks of language models. However, existing approaches lack interpretability, compromise on data utility and fail to provide privacy guarantees. Thus, the goal of my doctoral research is to develop interpretable approaches towards privacy preservation of text representations that retain data utility while guaranteeing privacy. To this end, I aim to study and develop methods to incorporate steganographic modifications within the vector geometry to obfuscate underlying spurious associations and preserve the distributional semantic properties learnt during training.