 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Model Compression Improve NLP Fairness
Paper and Code
Jan 21, 2022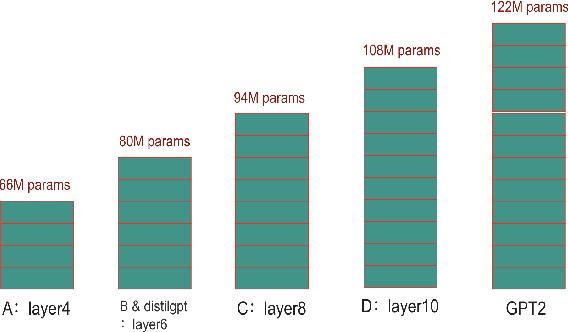
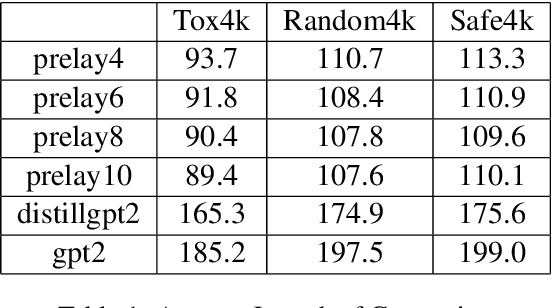
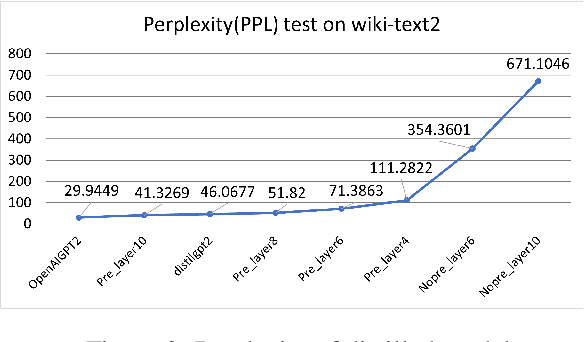
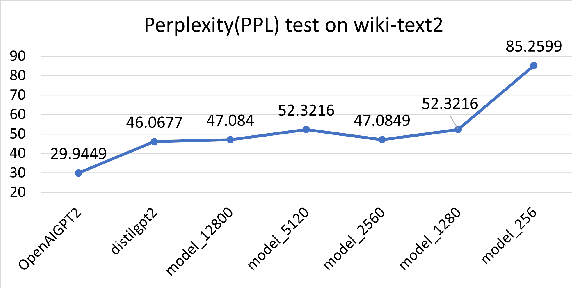
Model compression techniques are receiving increasing attention; however, the effect of compression on model fairness is still under explored. This is the first paper to examine the effect of distillation and pruning on the toxicity and bias of generative language models. We test Knowledge Distillation and Pruning methods on the GPT2 model and found a consistent pattern of toxicity and bias reduction after model distillation; this result can be potentially interpreted by existing line of research which describes model compression as a regularization technique; our work not only serves as a reference for safe deployment of compressed models, but also extends the discussion of "compression as regularization" into the setting of neural LMs, and hints at the possibility of using compression to develop fairer models.