 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Action Conditions from Instructional Manuals for Instruction Understanding
May 25, 2022
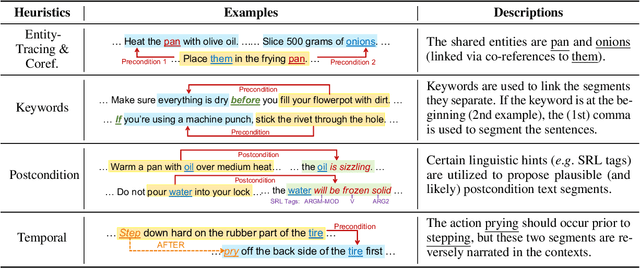

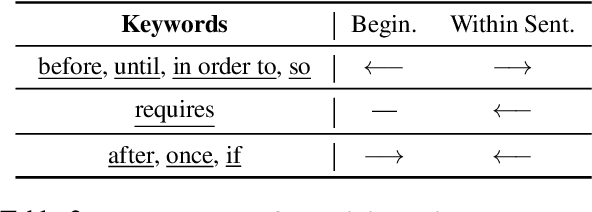
The ability to infer pre- and postconditions of an action is vital for comprehending complex instructions, and is essential for applications such as autonomous instruction-guided agents and assistive AI that supports humans to perform physical tasks. In this work, we propose a task dubbed action condition inference, and collecting a high-quality, human annotated dataset of preconditions and postconditions of actions in instructional manuals. We propose a weakly supervised approach to automatically construct large-scale training instances from online instructional manuals, and curate a densely human-annotated and validated dataset to study how well the current NLP models can infer action-condition dependencies in the instruction texts. We design two types of models differ by whether contextualized and global information is leveraged, as well as various combinations of heuristics to construct the weak supervisions. Our experimental results show a >20% F1-score improvement with considering the entire instruction contexts and a >6% F1-score benefit with the proposed heuristics.
Understanding Procedural Knowledge by Sequencing Multimodal Instructional Manuals
Oct 16, 2021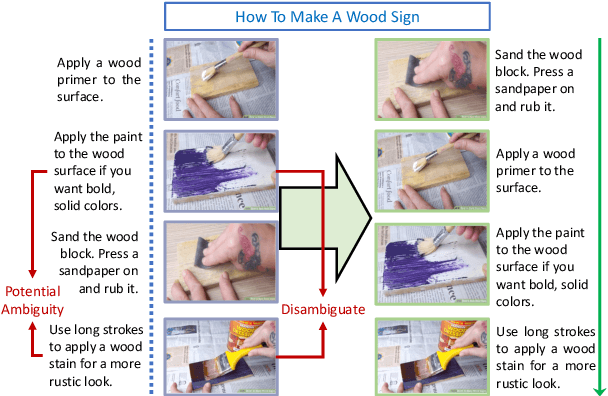
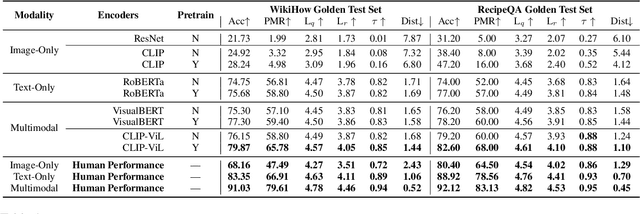
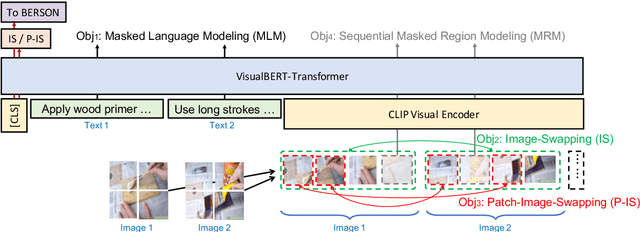

The ability to sequence unordered events is an essential skill to comprehend and reason about real world task procedures, which often requires thorough understanding of temporal common sense and multimodal information, as these procedures are often communicated through a combination of texts and images. Such capability is essential for applications such as sequential task planning and multi-source instruction summarization. While humans are capable of reasoning about and sequencing unordered multimodal procedural instructions, whether current machine learning models have such essential capability is still an open question. In this work, we benchmark models' capability of reasoning over and sequencing unordered multimodal instructions by curating datasets from popular online instructional manuals and collecting comprehensive human annotations. We find models not only perform significantly worse than humans but also seem incapable of efficiently utilizing the multimodal information. To improve machines' performance on multimodal event sequencing, we propose sequentiality-aware pretraining techniques that exploit the sequential alignment properties of both texts and images, resulting in > 5% significant improvements.