 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolating Item and User Fairness in Recommendation Systems
Jun 12, 2023Online platforms employ recommendation systems to enhance customer engagement and drive revenue. However, in a multi-sided platform where the platform interacts with diverse stakeholders such as sellers (items) and customers (users), each with their own desired outcomes, finding an appropriate middle ground becomes a complex operational challenge. In this work, we investigate the ``price of fairness'', which captures the platform's potential compromises when balancing the interests of different stakeholders. Motivated by this, we propose a fair recommendation framework where the platform maximizes its revenue while interpolating between item and user fairness constraints. We further examine the fair recommendation problem in a more realistic yet challenging online setting, where the platform lacks knowledge of user preferences and can only observe binary purchase decisions. To address this, we design a low-regret online optimization algorithm that preserves the platform's revenue while achieving fairness for both items and users. Finally, we demonstrate the effectiveness of our framework and proposed method via a case study on MovieLens data.
Dynamic Bandits with an Auto-Regressive Temporal Structure
Oct 28, 2022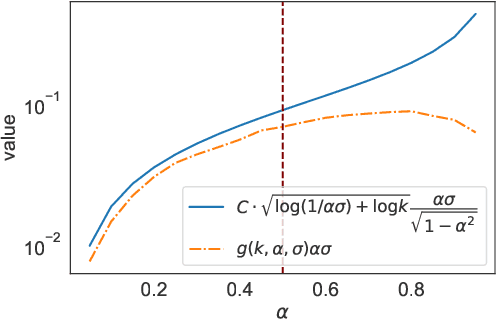

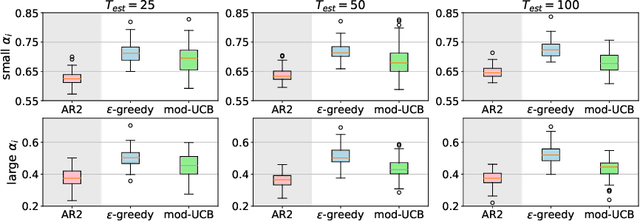
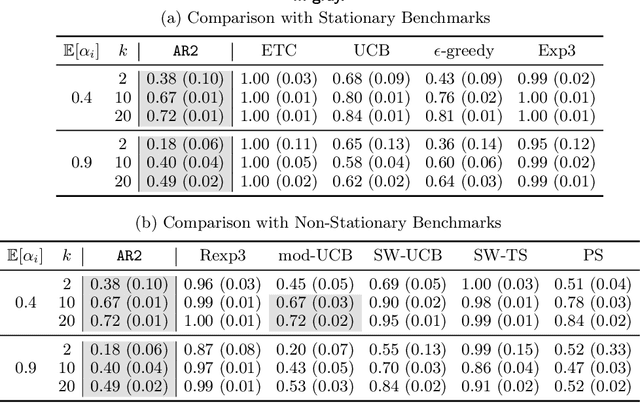
Multi-armed bandit (MAB) problems are mainly studied under two extreme settings known as stochastic and adversarial. These two settings, however, do not capture realistic environments such as search engines and marketing and advertising, in which rewards stochastically change in time. Motivated by that, we introduce and study a dynamic MAB problem with stochastic temporal structure, where the expected reward of each arm is governed by an auto-regressive (AR) model. Due to the dynamic nature of the rewards, simple "explore and commit" policies fail, as all arms have to be explored continuously over time. We formalize this by characterizing a per-round regret lower bound, where the regret is measured against a strong (dynamic) benchmark. We then present an algorithm whose per-round regret almost matches our regret lower bound. Our algorithm relies on two mechanisms: (i) alternating between recently pulled arms and unpulled arms with potential, and (ii) restarting. These mechanisms enable the algorithm to dynamically adapt to changes and discard irrelevant past information at a suitable rate. In numerical studies, we further demonstrate the strength of our algorithm under different types of non-stationary settings.
Online Learning and Matching for Resource Allocation Problems
Nov 18, 2019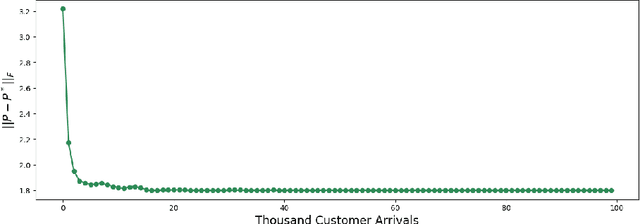
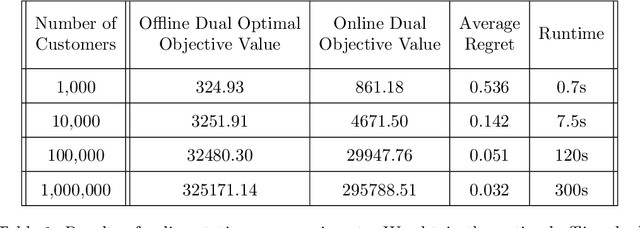
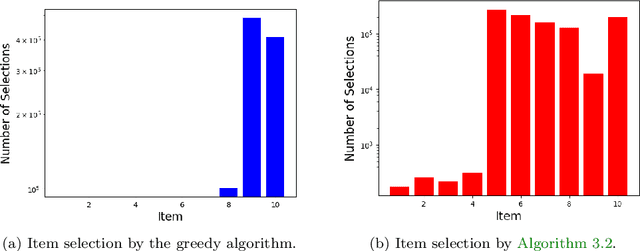
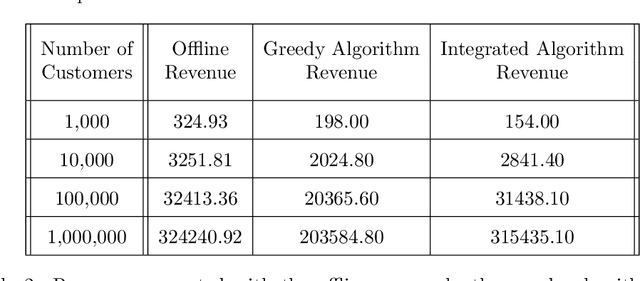
In order for an e-commerce platform to maximize its revenue, it must recommend customers items they are most likely to purchase. However, the company often has business constraints on these items, such as the number of each item in stock. In this work, our goal is to recommend items to users as they arrive on a webpage sequentially, in an online manner, in order to maximize reward for a company, but also satisfy budget constraints. We first approach the simpler online problem in which the customers arrive as a stationary Poisson process, and present an integrated algorithm that performs online optimization and online learning together. We then make the model more complicated but more realistic, treating the arrival processes as non-stationary Poisson processes. To deal with heterogeneous customer arrivals, we propose a time segmentation algorithm that converts a non-stationary problem into a series of stationary problems. Experiments conducted on large-scale synthetic data demonstrate the effectiveness and efficiency of our proposed approaches on solving constrained resource allocation problems.