 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpend Less, Reason Better: Budget-Aware Value Tree Search for LLM Agents
Mar 13, 2026Test-time scaling has become a dominant paradigm for improving LLM agent reliability, yet current approaches treat compute as an abundant resource, allowing agents to exhaust token and tool budgets on redundant steps or dead-end trajectories. Existing budget-aware methods either require expensive fine-tuning or rely on coarse, trajectory-level heuristics that cannot intervene mid-execution. We propose the Budget-Aware Value Tree (BAVT), a training-free inference-time framework that models multi-hop reasoning as a dynamic search tree guided by step-level value estimation within a single LLM backbone. Another key innovation is a budget-conditioned node selection mechanism that uses the remaining resource ratio as a natural scaling exponent over node values, providing a principled, parameter-free transition from broad exploration to greedy exploitation as the budget depletes. To combat the well-known overconfidence of LLM self-evaluation, BAVT employs a residual value predictor that scores relative progress rather than absolute state quality, enabling reliable pruning of uninformative or redundant tool calls. We further provide a theoretical convergence guarantee, proving that BAVT reaches a terminal answer with probability at least $1-ε$ under an explicit finite budget bound. Extensive evaluations on four multi-hop QA benchmarks across two model families demonstrate that BAVT consistently outperforms parallel sampling baselines. Most notably, BAVT under strict low-budget constraints surpasses baseline performance at $4\times$ the resource allocation, establishing that intelligent budget management fundamentally outperforms brute-force compute scaling.
When RAG Hurts: Diagnosing and Mitigating Attention Distraction in Retrieval-Augmented LVLMs
Jan 30, 2026While Retrieval-Augmented Generation (RAG) is one of the dominant paradigms for enhancing Large Vision-Language Models (LVLMs) on knowledge-based VQA tasks, recent work attributes RAG failures to insufficient attention towards the retrieved context, proposing to reduce the attention allocated to image tokens. In this work, we identify a distinct failure mode that previous study overlooked: Attention Distraction (AD). When the retrieved context is sufficient (highly relevant or including the correct answer), the retrieved text suppresses the visual attention globally, and the attention on image tokens shifts away from question-relevant regions. This leads to failures on questions the model could originally answer correctly without the retrieved text. To mitigate this issue, we propose MAD-RAG, a training-free intervention that decouples visual grounding from context integration through a dual-question formulation, combined with attention mixing to preserve image-conditioned evidence. Extensive experiments on OK-VQA, E-VQA, and InfoSeek demonstrate that MAD-RAG consistently outperforms existing baselines across different model families, yielding absolute gains of up to 4.76%, 9.20%, and 6.18% over the vanilla RAG baseline. Notably, MAD-RAG rectifies up to 74.68% of failure cases with negligible computational overhead.
Efficient and Context-Aware Label Propagation for Zero-/Few-Shot Training-Free Adaptation of Vision-Language Model
Dec 24, 2024



Vision-language models (VLMs) have revolutionized machine learning by leveraging large pre-trained models to tackle various downstream tasks. Despite improvements in label, training, and data efficiency, many state-of-the-art VLMs still require task-specific hyperparameter tuning and fail to fully exploit test samples. To overcome these challenges, we propose a graph-based approach for label-efficient adaptation and inference. Our method dynamically constructs a graph over text prompts, few-shot examples, and test samples, using label propagation for inference without task-specific tuning. Unlike existing zero-shot label propagation techniques, our approach requires no additional unlabeled support set and effectively leverages the test sample manifold through dynamic graph expansion. We further introduce a context-aware feature re-weighting mechanism to improve task adaptation accuracy. Additionally, our method supports efficient graph expansion, enabling real-time inductive inference. Extensive evaluations on downstream tasks, such as fine-grained categorization and out-of-distribution generalization, demonstrate the effectiveness of our approach.
On the Adversarial Risk of Test Time Adaptation: An Investigation into Realistic Test-Time Data Poisoning
Oct 07, 2024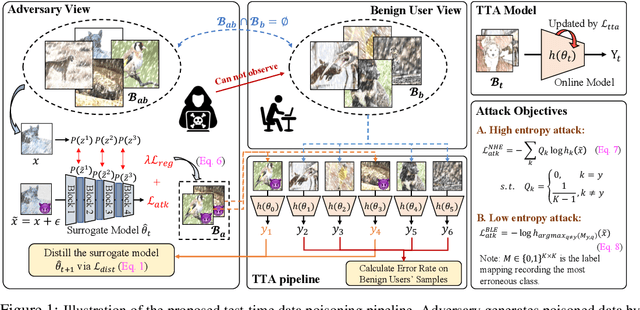



Test-time adaptation (TTA) updates the model weights during the inference stage using testing data to enhance generalization. However, this practice exposes TTA to adversarial risks. Existing studies have shown that when TTA is updated with crafted adversarial test samples, also known as test-time poisoned data, the performance on benign samples can deteriorate. Nonetheless, the perceived adversarial risk may be overstated if the poisoned data is generated under overly strong assumptions. In this work, we first review realistic assumptions for test-time data poisoning, including white-box versus grey-box attacks, access to benign data, attack budget, and more. We then propose an effective and realistic attack method that better produces poisoned samples without access to benign samples, and derive an effective in-distribution attack objective. We also design two TTA-aware attack objectives. Our benchmarks of existing attack methods reveal that the TTA methods are more robust than previously believed. In addition, we analyze effective defense strategies to help develop adversarially robust TTA methods.
Exploring Human-in-the-Loop Test-Time Adaptation by Synergizing Active Learning and Model Selection
May 29, 2024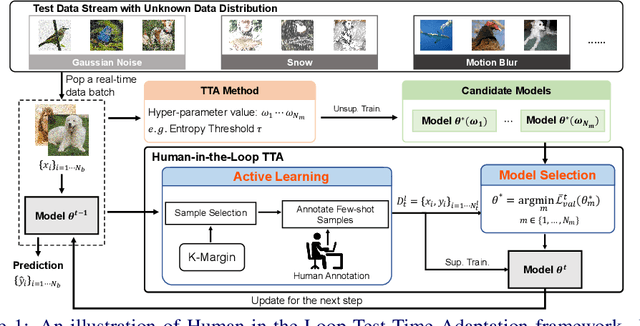
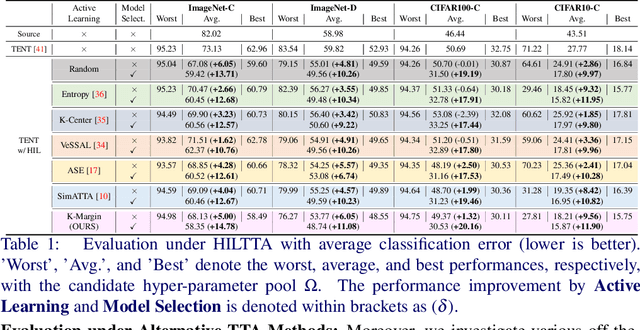
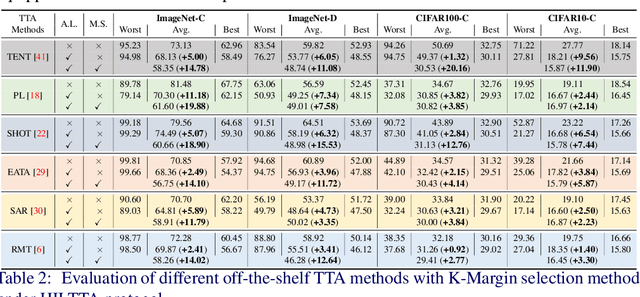
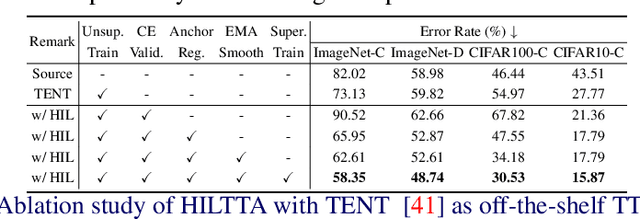
Existing test-time adaptation (TTA) approaches often adapt models with the unlabeled testing data stream. A recent attempt relaxed the assumption by introducing limited human annotation, referred to as Human-In-the-Loop Test-Time Adaptation (HILTTA) in this study. The focus of existing HILTTA lies on selecting the most informative samples to label, a.k.a. active learning. In this work, we are motivated by a pitfall of TTA, i.e. sensitive to hyper-parameters, and propose to approach HILTTA by synergizing active learning and model selection. Specifically, we first select samples for human annotation (active learning) and then use the labeled data to select optimal hyper-parameters (model selection). A sample selection strategy is tailored for choosing samples by considering the balance between active learning and model selection purposes. We demonstrate on 4 TTA datasets that the proposed HILTTA approach is compatible with off-the-shelf TTA methods which outperform the state-of-the-art HILTTA methods and stream-based active learning methods. Importantly, our proposed method can always prevent choosing the worst hyper-parameters on all off-the-shelf TTA methods. The source code will be released upon publication.
Dynamic Shuffle: An Efficient Channel Mixture Method
Oct 04, 2023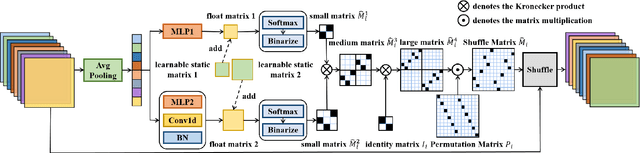
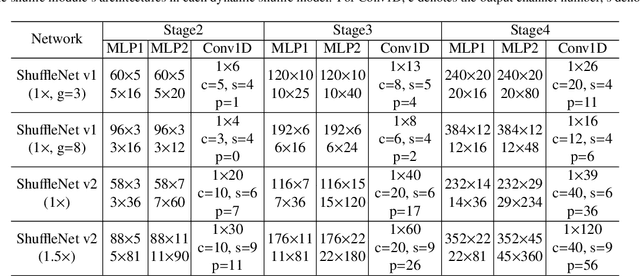
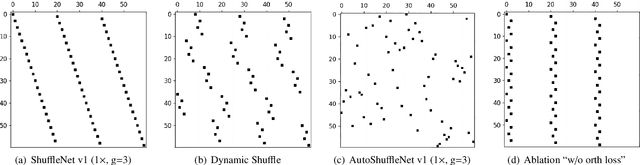
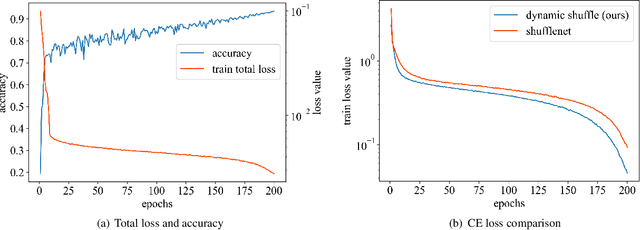
The redundancy of Convolutional neural networks not only depends on weights but also depends on inputs. Shuffling is an efficient operation for mixing channel information but the shuffle order is usually pre-defined. To reduce the data-dependent redundancy, we devise a dynamic shuffle module to generate data-dependent permutation matrices for shuffling. Since the dimension of permutation matrix is proportional to the square of the number of input channels, to make the generation process efficiently, we divide the channels into groups and generate two shared small permutation matrices for each group, and utilize Kronecker product and cross group shuffle to obtain the final permutation matrices. To make the generation process learnable, based on theoretical analysis, softmax, orthogonal regularization, and binarization are employed to asymptotically approximate the permutation matrix. Dynamic shuffle adaptively mixes channel information with negligible extra computation and memory occupancy. Experiment results on image classification benchmark datasets CIFAR-10, CIFAR-100, Tiny ImageNet and ImageNet have shown that our method significantly increases ShuffleNets' performance. Adding dynamic generated matrix with learnable static matrix, we further propose static-dynamic-shuffle and show that it can serve as a lightweight replacement of ordinary pointwise convolution.
On the Robustness of Open-World Test-Time Training: Self-Training with Dynamic Prototype Expansion
Aug 19, 2023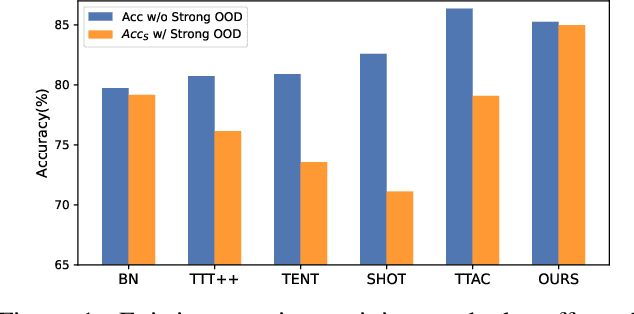
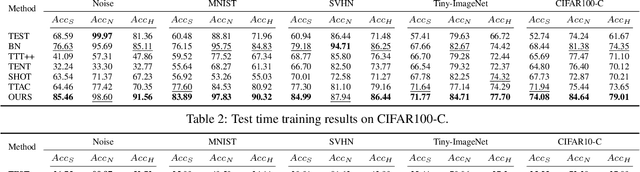

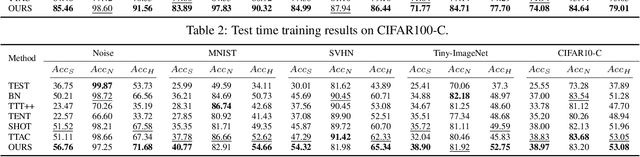
Generalizing deep learning models to unknown target domain distribution with low latency has motivated research into test-time training/adaptation (TTT/TTA). Existing approaches often focus on improving test-time training performance under well-curated target domain data. As figured out in this work, many state-of-the-art methods fail to maintain the performance when the target domain is contaminated with strong out-of-distribution (OOD) data, a.k.a. open-world test-time training (OWTTT). The failure is mainly due to the inability to distinguish strong OOD samples from regular weak OOD samples. To improve the robustness of OWTTT we first develop an adaptive strong OOD pruning which improves the efficacy of the self-training TTT method. We further propose a way to dynamically expand the prototypes to represent strong OOD samples for an improved weak/strong OOD data separation. Finally, we regularize self-training with distribution alignment and the combination yields the state-of-the-art performance on 5 OWTTT benchmarks. The code is available at https://github.com/Yushu-Li/OWTTT.
A Noise-Robust Fast Sparse Bayesian Learning Model
Aug 20, 2019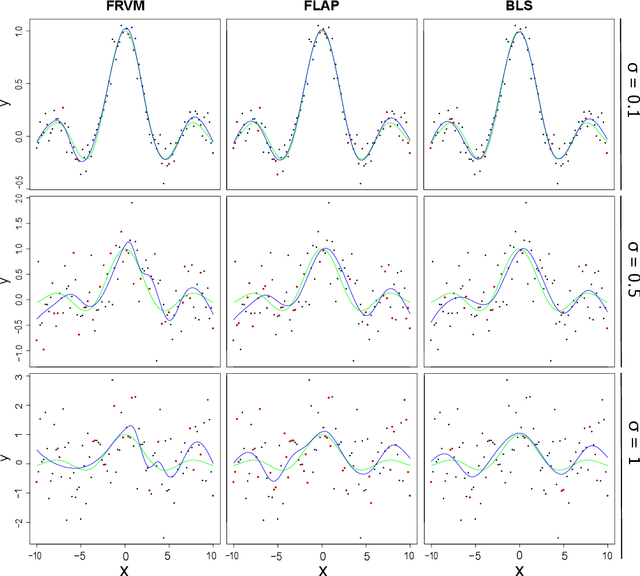
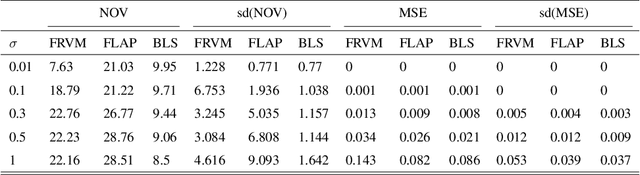
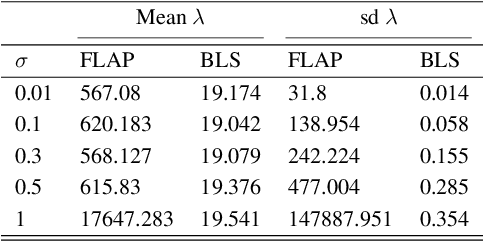
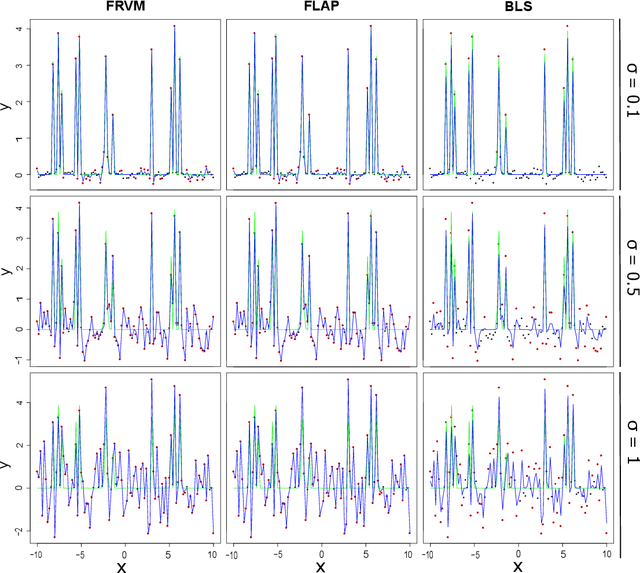
This paper utilizes the hierarchical model structure from the Bayesian Lasso in the Sparse Bayesian Learning process to develop a new type of probabilistic supervised learning approach. This approach has several performance advantages, such as being fast, sparse and especially robust to the variance in random noise. The hierarchical model structure in this Bayesian framework is designed in such a way that the priors do not only penalize the unnecessary complexity of the model but also depend on the variance of the random noise in the data. The hyperparameters in the model are estimated by the Fast Marginal Likelihood Maximization algorithm and can achieve low computational cost and faster learning process. We compare our methodology with two other popular Sparse Bayesian Learning models: The Relevance Vector Machine and a sparse Bayesian model that has been used for signal reconstruction in compressive sensing. We show that our method will generally provide more sparse solutions and be more flexible and stable when data is polluted by high variance noise.