 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo RWKV:Video Action Recognition Based RWKV
Nov 08, 2024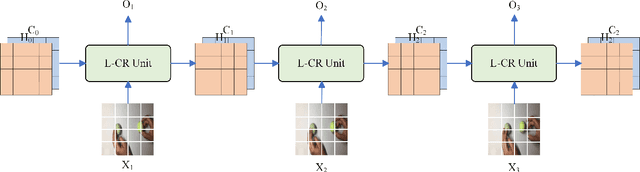
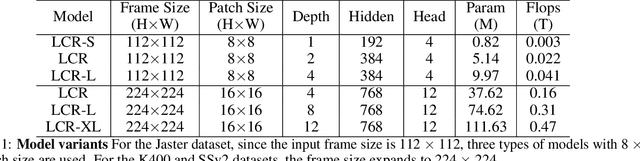
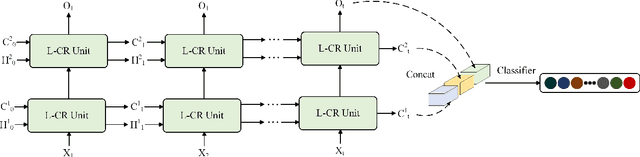
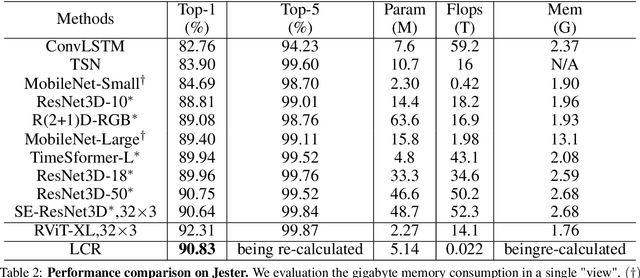
To address the challenges of high computational costs and long-distance dependencies in exist ing video understanding methods, such as CNNs and Transformers, this work introduces RWKV to the video domain in a novel way. We propose a LSTM CrossRWKV (LCR) framework, designed for spatiotemporal representation learning to tackle the video understanding task. Specifically, the proposed linear complexity LCR incorporates a novel Cross RWKV gate to facilitate interaction be tween current frame edge information and past features, enhancing the focus on the subject through edge features and globally aggregating inter-frame features over time. LCR stores long-term mem ory for video processing through an enhanced LSTM recurrent execution mechanism. By leveraging the Cross RWKV gate and recurrent execution, LCR effectively captures both spatial and temporal features. Additionally, the edge information serves as a forgetting gate for LSTM, guiding long-term memory management.Tube masking strategy reduces redundant information in food and reduces overfitting.These advantages enable LSTM CrossRWKV to set a new benchmark in video under standing, offering a scalable and efficient solution for comprehensive video analysis. All code and models are publicly available.
Which bits went where? Past and future transfer entropy decomposition with the information bottleneck
Nov 07, 2024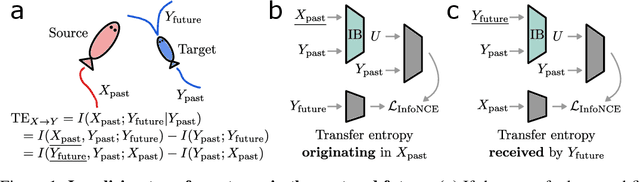
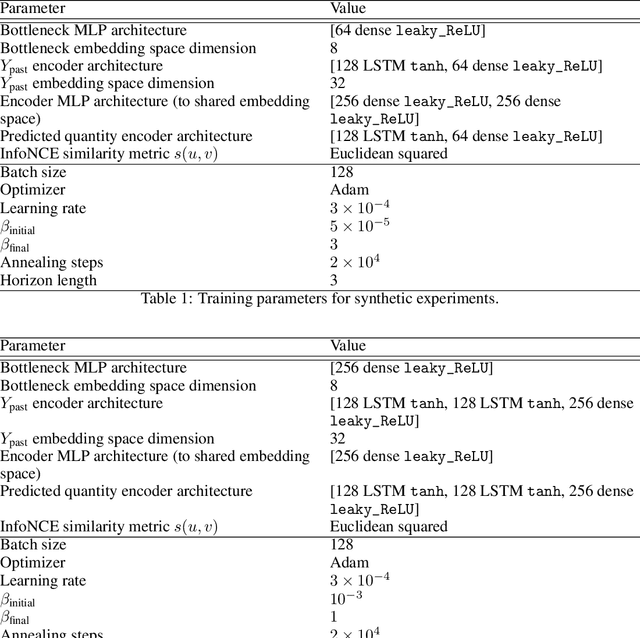
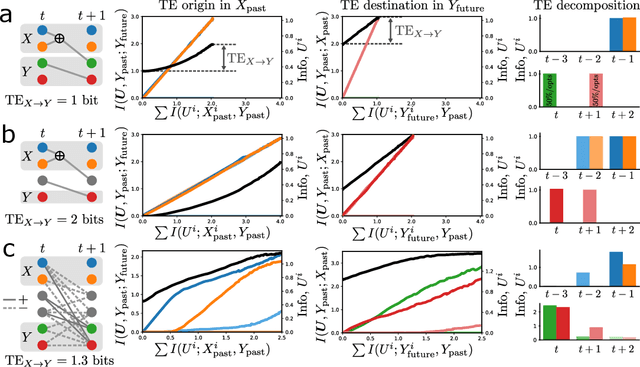
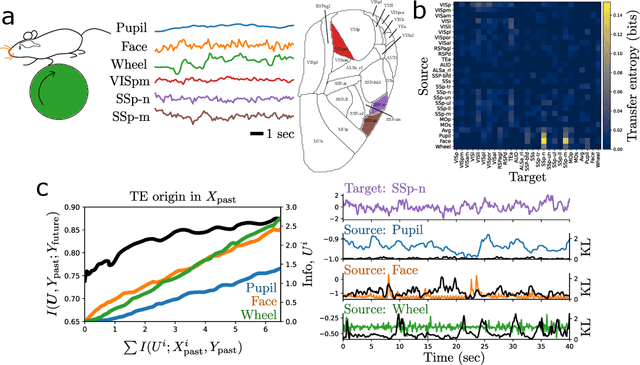
Whether the system under study is a shoal of fish, a collection of neurons, or a set of interacting atmospheric and oceanic processes, transfer entropy measures the flow of information between time series and can detect possible causal relationships. Much like mutual information, transfer entropy is generally reported as a single value summarizing an amount of shared variation, yet a more fine-grained accounting might illuminate much about the processes under study. Here we propose to decompose transfer entropy and localize the bits of variation on both sides of information flow: that of the originating process's past and that of the receiving process's future. We employ the information bottleneck (IB) to compress the time series and identify the transferred entropy. We apply our method to decompose the transfer entropy in several synthetic recurrent processes and an experimental mouse dataset of concurrent behavioral and neural activity. Our approach highlights the nuanced dynamics within information flow, laying a foundation for future explorations into the intricate interplay of temporal processes in complex systems.
Dynamic Shuffle: An Efficient Channel Mixture Method
Oct 04, 2023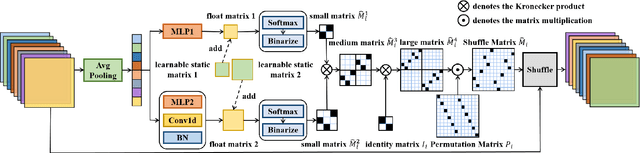
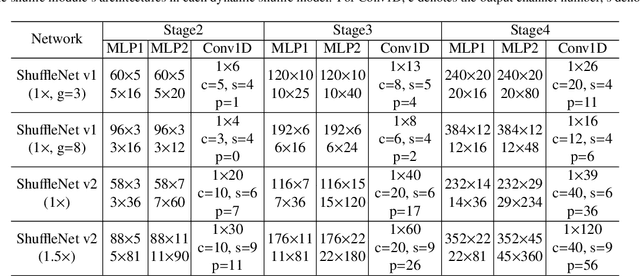
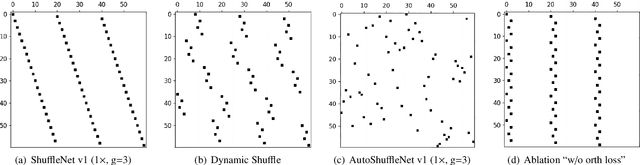
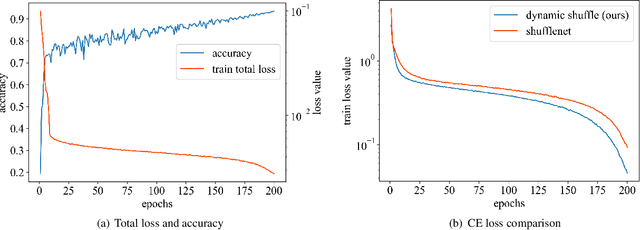
The redundancy of Convolutional neural networks not only depends on weights but also depends on inputs. Shuffling is an efficient operation for mixing channel information but the shuffle order is usually pre-defined. To reduce the data-dependent redundancy, we devise a dynamic shuffle module to generate data-dependent permutation matrices for shuffling. Since the dimension of permutation matrix is proportional to the square of the number of input channels, to make the generation process efficiently, we divide the channels into groups and generate two shared small permutation matrices for each group, and utilize Kronecker product and cross group shuffle to obtain the final permutation matrices. To make the generation process learnable, based on theoretical analysis, softmax, orthogonal regularization, and binarization are employed to asymptotically approximate the permutation matrix. Dynamic shuffle adaptively mixes channel information with negligible extra computation and memory occupancy. Experiment results on image classification benchmark datasets CIFAR-10, CIFAR-100, Tiny ImageNet and ImageNet have shown that our method significantly increases ShuffleNets' performance. Adding dynamic generated matrix with learnable static matrix, we further propose static-dynamic-shuffle and show that it can serve as a lightweight replacement of ordinary pointwise convolution.
Early Autism Diagnosis based on Path Signature and Siamese Unsupervised Feature Compressor
Jul 12, 2023



Autism Spectrum Disorder (ASD) has been emerging as a growing public health threat. Early diagnosis of ASD is crucial for timely, effective intervention and treatment. However, conventional diagnosis methods based on communications and behavioral patterns are unreliable for children younger than 2 years of age. Given evidences of neurodevelopmental abnormalities in ASD infants, we resort to a novel deep learning-based method to extract key features from the inherently scarce, class-imbalanced, and heterogeneous structural MR images for early autism diagnosis. Specifically, we propose a Siamese verification framework to extend the scarce data, and an unsupervised compressor to alleviate data imbalance by extracting key features. We also proposed weight constraints to cope with sample heterogeneity by giving different samples different voting weights during validation, and we used Path Signature to unravel meaningful developmental features from the two-time point data longitudinally. Extensive experiments have shown that our method performed well under practical scenarios, transcending existing machine learning methods.