 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo RWKV:Video Action Recognition Based RWKV
Paper and Code
Nov 08, 2024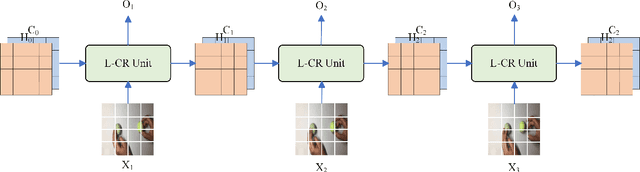
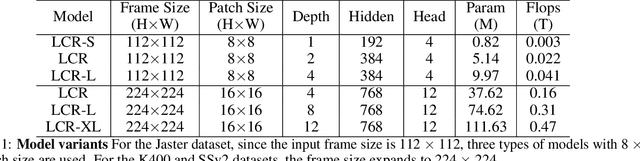
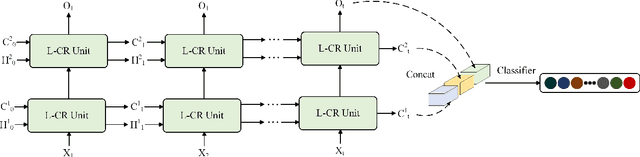
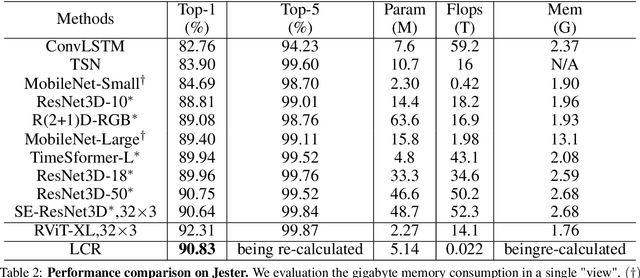
To address the challenges of high computational costs and long-distance dependencies in exist ing video understanding methods, such as CNNs and Transformers, this work introduces RWKV to the video domain in a novel way. We propose a LSTM CrossRWKV (LCR) framework, designed for spatiotemporal representation learning to tackle the video understanding task. Specifically, the proposed linear complexity LCR incorporates a novel Cross RWKV gate to facilitate interaction be tween current frame edge information and past features, enhancing the focus on the subject through edge features and globally aggregating inter-frame features over time. LCR stores long-term mem ory for video processing through an enhanced LSTM recurrent execution mechanism. By leveraging the Cross RWKV gate and recurrent execution, LCR effectively captures both spatial and temporal features. Additionally, the edge information serves as a forgetting gate for LSTM, guiding long-term memory management.Tube masking strategy reduces redundant information in food and reduces overfitting.These advantages enable LSTM CrossRWKV to set a new benchmark in video under standing, offering a scalable and efficient solution for comprehensive video analysis. All code and models are publicly available.