 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Selective Encryption Against Gradient Inversion Attacks
Aug 06, 2025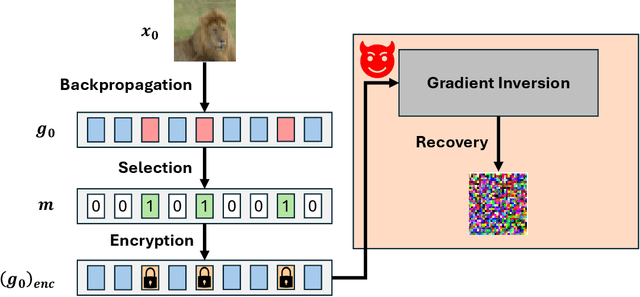

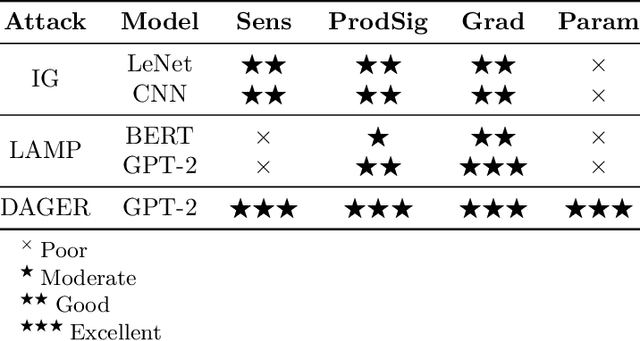

Gradient inversion attacks pose significant privacy threats to distributed training frameworks such as federated learning, enabling malicious parties to reconstruct sensitive local training data from gradient communications between clients and an aggregation server during the aggregation process. While traditional encryption-based defenses, such as homomorphic encryption, offer strong privacy guarantees without compromising model utility, they often incur prohibitive computational overheads. To mitigate this, selective encryption has emerged as a promising approach, encrypting only a subset of gradient data based on the data's significance under a certain metric. However, there have been few systematic studies on how to specify this metric in practice. This paper systematically evaluates selective encryption methods with different significance metrics against state-of-the-art attacks. Our findings demonstrate the feasibility of selective encryption in reducing computational overhead while maintaining resilience against attacks. We propose a distance-based significance analysis framework that provides theoretical foundations for selecting critical gradient elements for encryption. Through extensive experiments on different model architectures (LeNet, CNN, BERT, GPT-2) and attack types, we identify gradient magnitude as a generally effective metric for protection against optimization-based gradient inversions. However, we also observe that no single selective encryption strategy is universally optimal across all attack scenarios, and we provide guidelines for choosing appropriate strategies for different model architectures and privacy requirements.
Data Distribution Valuation
Oct 06, 2024
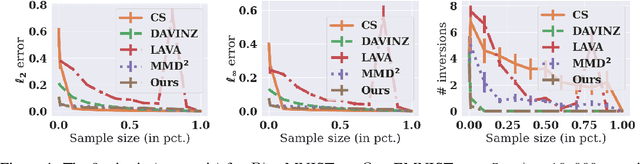

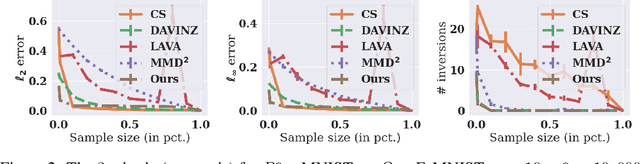
Data valuation is a class of techniques for quantitatively assessing the value of data for applications like pricing in data marketplaces. Existing data valuation methods define a value for a discrete dataset. However, in many use cases, users are interested in not only the value of the dataset, but that of the distribution from which the dataset was sampled. For example, consider a buyer trying to evaluate whether to purchase data from different vendors. The buyer may observe (and compare) only a small preview sample from each vendor, to decide which vendor's data distribution is most useful to the buyer and purchase. The core question is how should we compare the values of data distributions from their samples? Under a Huber characterization of the data heterogeneity across vendors, we propose a maximum mean discrepancy (MMD)-based valuation method which enables theoretically principled and actionable policies for comparing data distributions from samples. We empirically demonstrate that our method is sample-efficient and effective in identifying valuable data distributions against several existing baselines, on multiple real-world datasets (e.g., network intrusion detection, credit card fraud detection) and downstream applications (classification, regression).
Mixture-of-Linear-Experts for Long-term Time Series Forecasting
Dec 11, 2023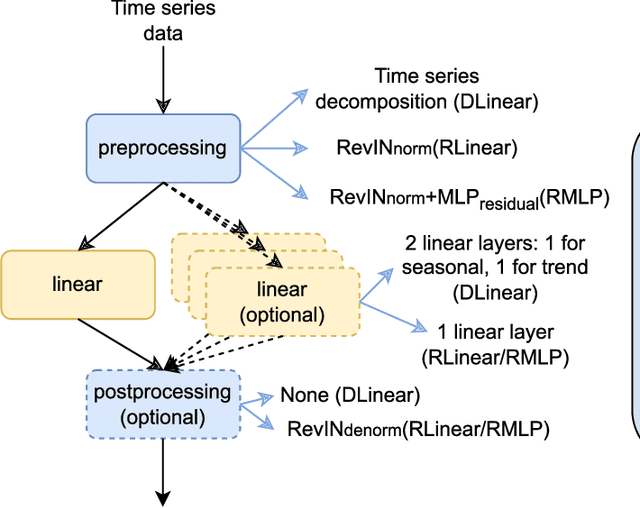

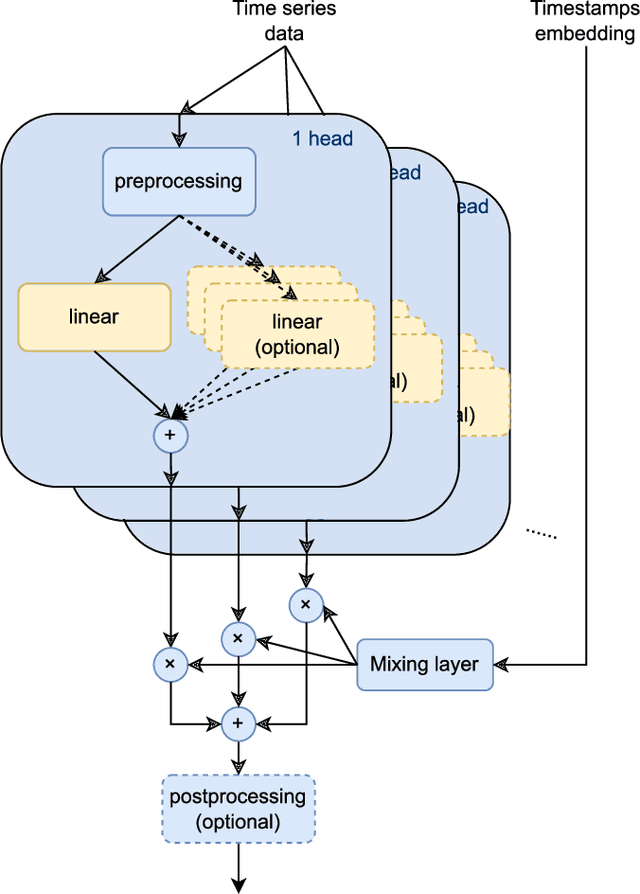
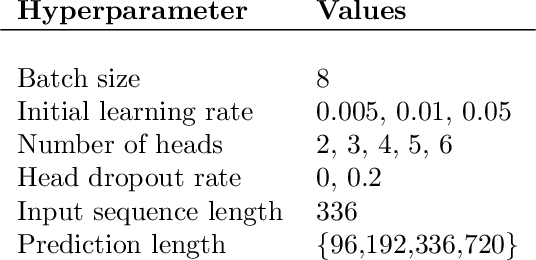
Long-term time series forecasting (LTSF) aims to predict future values of a time series given the past values. The current state-of-the-art (SOTA) on this problem is attained in some cases by linear-centric models, which primarily feature a linear mapping layer. However, due to their inherent simplicity, they are not able to adapt their prediction rules to periodic changes in time series patterns. To address this challenge, we propose a Mixture-of-Experts-style augmentation for linear-centric models and propose Mixture-of-Linear-Experts (MoLE). Instead of training a single model, MoLE trains multiple linear-centric models (i.e., experts) and a router model that weighs and mixes their outputs. While the entire framework is trained end-to-end, each expert learns to specialize in a specific temporal pattern, and the router model learns to compose the experts adaptively. Experiments show that MoLE reduces forecasting error of linear-centric models, including DLinear, RLinear, and RMLP, in over 78% of the datasets and settings we evaluated. By using MoLE existing linear-centric models can achieve SOTA LTSF results in 68% of the experiments that PatchTST reports and we compare to, whereas existing single-head linear-centric models achieve SOTA results in only 25% of cases. Additionally, MoLE models achieve SOTA in all settings for the newly released Weather2K datasets.
Summary Statistic Privacy in Data Sharing
Mar 03, 2023



Data sharing between different parties has become increasingly common across industry and academia. An important class of privacy concerns that arises in data sharing scenarios regards the underlying distribution of data. For example, the total traffic volume of data from a networking company can reveal the scale of its business, which may be considered a trade secret. Unfortunately, existing privacy frameworks (e.g., differential privacy, anonymization) do not adequately address such concerns. In this paper, we propose summary statistic privacy, a framework for analyzing and protecting these summary statistic privacy concerns. We propose a class of quantization mechanisms that can be tailored to various data distributions and statistical secrets, and analyze their privacy-distortion trade-offs under our framework. We prove corresponding lower bounds on the privacy-utility tradeoff, which match the tradeoffs of the quantization mechanism under certain regimes, up to small constant factors. Finally, we demonstrate that the proposed quantization mechanisms achieve better privacy-distortion tradeoffs than alternative privacy mechanisms on real-world datasets.
Towards a Defense against Backdoor Attacks in Continual Federated Learning
May 28, 2022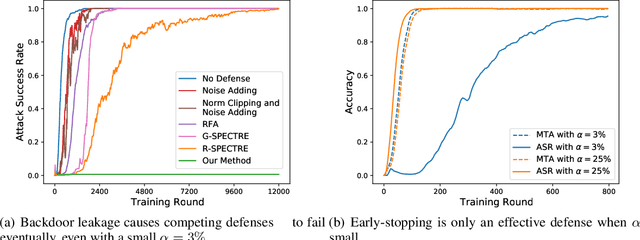

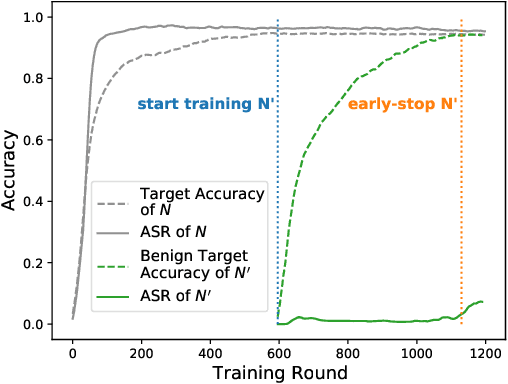

Backdoor attacks are a major concern in federated learning (FL) pipelines where training data is sourced from untrusted clients over long periods of time (i.e., continual learning). Preventing such attacks is difficult because defenders in FL do not have access to raw training data. Moreover, in a phenomenon we call backdoor leakage, models trained continuously eventually suffer from backdoors due to cumulative errors in backdoor defense mechanisms. We propose a novel framework for defending against backdoor attacks in the federated continual learning setting. Our framework trains two models in parallel: a backbone model and a shadow model. The backbone is trained without any defense mechanism to obtain good performance on the main task. The shadow model combines recent ideas from robust covariance estimation-based filters with early-stopping to control the attack success rate even as the data distribution changes. We provide theoretical motivation for this design and show experimentally that our framework significantly improves upon existing defenses against backdoor attacks.