 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelpful or Harmful Data? Fine-tuning-free Shapley Attribution for Explaining Language Model Predictions
Paper and Code
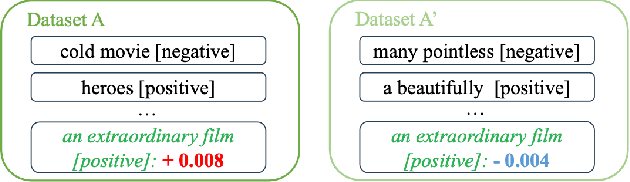
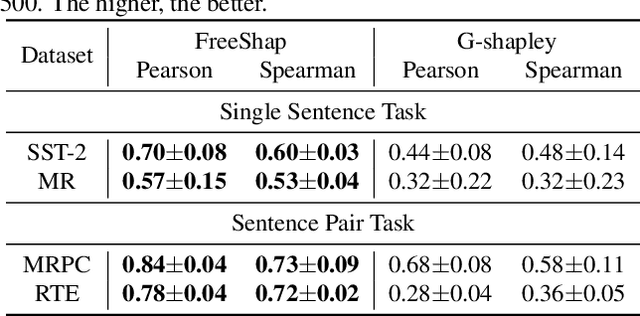
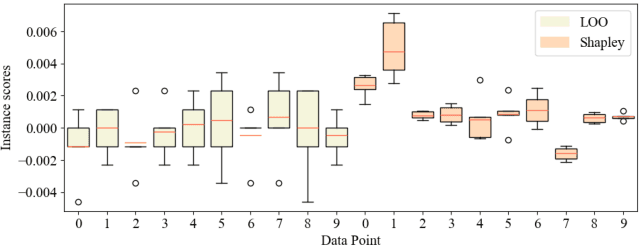

The increasing complexity of foundational models underscores the necessity for explainability, particularly for fine-tuning, the most widely used training method for adapting models to downstream tasks. Instance attribution, one type of explanation, attributes the model prediction to each training example by an instance score. However, the robustness of instance scores, specifically towards dataset resampling, has been overlooked. To bridge this gap, we propose a notion of robustness on the sign of the instance score. We theoretically and empirically demonstrate that the popular leave-one-out-based methods lack robustness, while the Shapley value behaves significantly better, but at a higher computational cost. Accordingly, we introduce an efficient fine-tuning-free approximation of the Shapley value (FreeShap) for instance attribution based on the neural tangent kernel. We empirically demonstrate that FreeShap outperforms other methods for instance attribution and other data-centric applications such as data removal, data selection, and wrong label detection, and further generalize our scale to large language models (LLMs). Our code is available at https://github.com/JTWang2000/FreeShap.