 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
May 13, 2025Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability distribution, sequence perplexity is invariant under any factorization, including forward, backward, or arbitrary permutations. This result establishes a rigorous theoretical foundation for studying how LLMs learn from data and defines principled protocols for empirical evaluation. Applying these protocols, we show that prior studies examining ordering effects suffer from critical methodological flaws. We retrain GPT-2 models across forward, backward, and arbitrary permuted orders on scientific text. We find systematic deviations from theoretical invariance across all orderings with arbitrary permutations strongly deviating from both forward and backward models, which largely (but not completely) agreed with one another. Deviations were traceable to differences in self-attention, reflecting positional and locality biases in processing. Our theoretical and empirical results provide novel avenues for understanding positional biases in LLMs and suggest methods for detecting when LLMs' probability distributions are inconsistent and therefore untrustworthy.
Beyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text
Nov 17, 2024

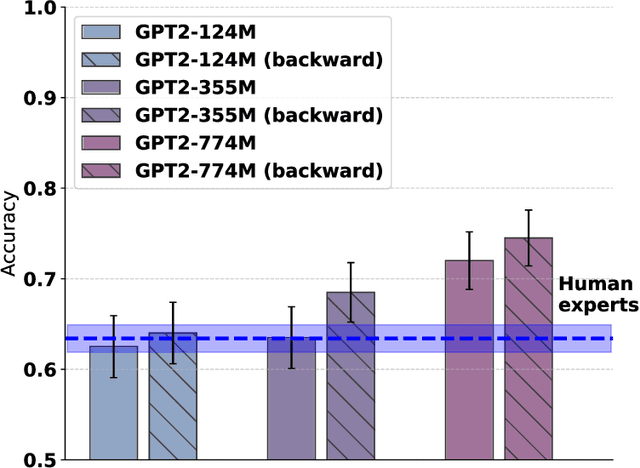
The impressive performance of large language models (LLMs) has led to their consideration as models of human language processing. Instead, we suggest that the success of LLMs arises from the flexibility of the transformer learning architecture. To evaluate this conjecture, we trained LLMs on scientific texts that were either in a forward or backward format. Despite backward text being inconsistent with the structure of human languages, we found that LLMs performed equally well in either format on a neuroscience benchmark, eclipsing human expert performance for both forward and backward orders. Our results are consistent with the success of transformers across diverse domains, such as weather prediction and protein design. This widespread success is attributable to LLM's ability to extract predictive patterns from any sufficiently structured input. Given their generality, we suggest caution in interpreting LLM's success in linguistic tasks as evidence for human-like mechanisms.
The empirical structure of word frequency distributions
Jan 09, 2020



The frequencies at which individual words occur across languages follow power law distributions, a pattern of findings known as Zipf's law. A vast literature argues over whether this serves to optimize the efficiency of human communication, however this claim is necessarily post hoc, and it has been suggested that Zipf's law may in fact describe mixtures of other distributions. From this perspective, recent findings that Sinosphere first (family) names are geometrically distributed are notable, because this is actually consistent with information theoretic predictions regarding optimal coding. First names form natural communicative distributions in most languages, and I show that when analyzed in relation to the communities in which they are used, first name distributions across a diverse set of languages are both geometric and, historically, remarkably similar, with power law distributions only emerging when empirical distributions are aggregated. I then show this pattern of findings replicates in communicative distributions of English nouns and verbs. These results indicate that if lexical distributions support efficient communication, they do so because their functional structures directly satisfy the constraints described by information theory, and not because of Zipf's law. Understanding the function of these information structures is likely to be key to explaining humankind's remarkable communicative capacities.
Source codes in human communication
Mar 08, 2019



Although information theoretic characterizations of human communication have become increasingly popular in linguistics, to date they have largely involved grafting probabilistic constructs onto older ideas about grammar. Similarities between human and digital communication have been strongly emphasized, and differences largely ignored. However, some of these differences matter: communication systems are based on predefined codes shared by every sender-receiver, whereas the distributions of words in natural languages guarantee that no speaker-hearer ever has access to an entire linguistic code, which seemingly undermines the idea that natural languages are probabilistic systems in any meaningful sense. This paper describes how the distributional properties of languages meet the various challenges arising from the differences between information systems and natural languages, along with the very different view of human communication these properties suggest.