 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Human-Like Processing: Large Language Models Perform Equivalently on Forward and Backward Scientific Text
Paper and Code


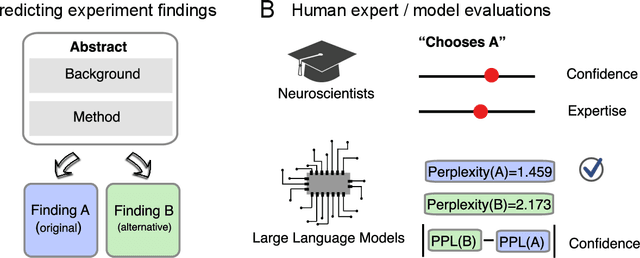
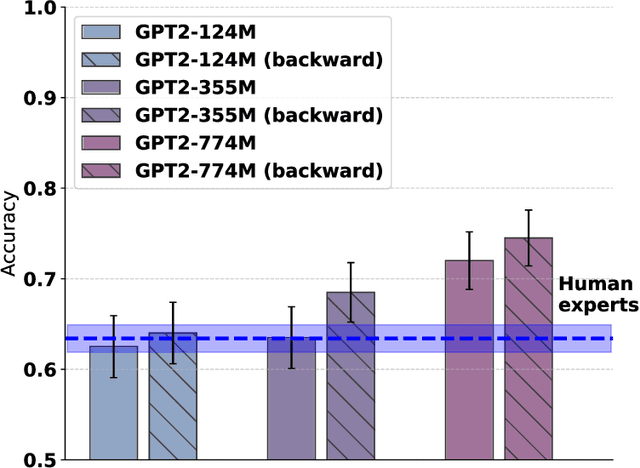
The impressive performance of large language models (LLMs) has led to their consideration as models of human language processing. Instead, we suggest that the success of LLMs arises from the flexibility of the transformer learning architecture. To evaluate this conjecture, we trained LLMs on scientific texts that were either in a forward or backward format. Despite backward text being inconsistent with the structure of human languages, we found that LLMs performed equally well in either format on a neuroscience benchmark, eclipsing human expert performance for both forward and backward orders. Our results are consistent with the success of transformers across diverse domains, such as weather prediction and protein design. This widespread success is attributable to LLM's ability to extract predictive patterns from any sufficiently structured input. Given their generality, we suggest caution in interpreting LLM's success in linguistic tasks as evidence for human-like mechanisms.