 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Text and Images Don't Mix: Bias-Correcting Language-Image Similarity Scores for Anomaly Detection
Paper and Code
Jul 24, 2024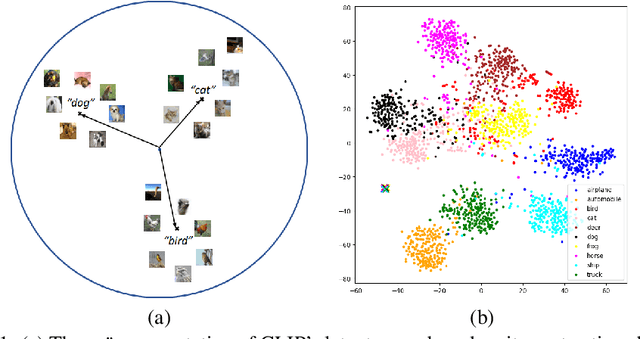
Contrastive Language-Image Pre-training (CLIP) achieves remarkable performance in various downstream tasks through the alignment of image and text input embeddings and holds great promise for anomaly detection. However, our empirical experiments show that the embeddings of text inputs unexpectedly tightly cluster together, far away from image embeddings, contrary to the model's contrastive training objective to align image-text input pairs. We show that this phenomenon induces a `similarity bias' - in which false negative and false positive errors occur due to bias in the similarities between images and the normal label text embeddings. To address this bias, we propose a novel methodology called BLISS which directly accounts for this similarity bias through the use of an auxiliary, external set of text inputs. BLISS is simple, it does not require strong inductive biases about anomalous behaviour nor an expensive training process, and it significantly outperforms baseline methods on benchmark image datasets, even when access to normal data is extremely limited.