 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHAT: Modeling Period Heterogeneity for Multivariate Time Series Forecasting
Jan 31, 2026While existing multivariate time series forecasting models have advanced significantly in modeling periodicity, they largely neglect the periodic heterogeneity common in real-world data, where variates exhibit distinct and dynamically changing periods. To effectively capture this periodic heterogeneity, we propose PHAT (Period Heterogeneity-Aware Transformer). Specifically, PHAT arranges multivariate inputs into a three-dimensional "periodic bucket" tensor, where the dimensions correspond to variate group characteristics with similar periodicity, time steps aligned by phase, and offsets within the period. By restricting interactions within buckets and masking cross-bucket connections, PHAT effectively avoids interference from inconsistent periods. We also propose a positive-negative attention mechanism, which captures periodic dependencies from two perspectives: periodic alignment and periodic deviation. Additionally, the periodic alignment attention scores are decomposed into positive and negative components, with a modulation term encoding periodic priors. This modulation constrains the attention mechanism to more faithfully reflect the underlying periodic trends. A mathematical explanation is provided to support this property. We evaluate PHAT comprehensively on 14 real-world datasets against 18 baselines, and the results show that it significantly outperforms existing methods, achieving highly competitive forecasting performance. Our sources is available at GitHub.
To See Far, Look Close: Evolutionary Forecasting for Long-term Time Series
Jan 30, 2026The prevailing Direct Forecasting (DF) paradigm dominates Long-term Time Series Forecasting (LTSF) by forcing models to predict the entire future horizon in a single forward pass. While efficient, this rigid coupling of output and evaluation horizons necessitates computationally prohibitive re-training for every target horizon. In this work, we uncover a counter-intuitive optimization anomaly: models trained on short horizons-when coupled with our proposed Evolutionary Forecasting (EF) paradigm-significantly outperform those trained directly on long horizons. We attribute this success to the mitigation of a fundamental optimization pathology inherent in DF, where conflicting gradients from distant futures cripple the learning of local dynamics. We establish EF as a unified generative framework, proving that DF is merely a degenerate special case of EF. Extensive experiments demonstrate that a singular EF model surpasses task-specific DF ensembles across standard benchmarks and exhibits robust asymptotic stability in extreme extrapolation. This work propels a paradigm shift in LTSF: moving from passive Static Mapping to autonomous Evolutionary Reasoning.
A General ReLearner: Empowering Spatiotemporal Prediction by Re-learning Input-label Residual
Jan 30, 2026Prevailing spatiotemporal prediction models typically operate under a forward (unidirectional) learning paradigm, in which models extract spatiotemporal features from historical observation input and map them to target spatiotemporal space for future forecasting (label). However, these models frequently exhibit suboptimal performance when spatiotemporal discrepancies exist between inputs and labels, for instance, when nodes with similar time-series inputs manifest distinct future labels, or vice versa. To address this limitation, we propose explicitly incorporating label features during the training phase. Specifically, we introduce the Spatiotemporal Residual Theorem, which generalizes the conventional unidirectional spatiotemporal prediction paradigm into a bidirectional learning framework. Building upon this theoretical foundation, we design an universal module, termed ReLearner, which seamlessly augments Spatiotemporal Neural Networks (STNNs) with a bidirectional learning capability via an auxiliary inverse learning process. In this process, the model relearns the spatiotemporal feature residuals between input data and future data. The proposed ReLearner comprises two critical components: (1) a Residual Learning Module, designed to effectively disentangle spatiotemporal feature discrepancies between input and label representations; and (2) a Residual Smoothing Module, employed to smooth residual terms and facilitate stable convergence. Extensive experiments conducted on 11 real-world datasets across 14 backbone models demonstrate that ReLearner significantly enhances the predictive performance of existing STNNs.Our code is available on GitHub.
FaLW: A Forgetting-aware Loss Reweighting for Long-tailed Unlearning
Jan 26, 2026Machine unlearning, which aims to efficiently remove the influence of specific data from trained models, is crucial for upholding data privacy regulations like the ``right to be forgotten". However, existing research predominantly evaluates unlearning methods on relatively balanced forget sets. This overlooks a common real-world scenario where data to be forgotten, such as a user's activity records, follows a long-tailed distribution. Our work is the first to investigate this critical research gap. We find that in such long-tailed settings, existing methods suffer from two key issues: \textit{Heterogeneous Unlearning Deviation} and \textit{Skewed Unlearning Deviation}. To address these challenges, we propose FaLW, a plug-and-play, instance-wise dynamic loss reweighting method. FaLW innovatively assesses the unlearning state of each sample by comparing its predictive probability to the distribution of unseen data from the same class. Based on this, it uses a forgetting-aware reweighting scheme, modulated by a balancing factor, to adaptively adjust the unlearning intensity for each sample. Extensive experiments demonstrate that FaLW achieves superior performance. Code is available at \textbf{Supplementary Material}.
We Need a More Robust Classifier: Dual Causal Learning Empowers Domain-Incremental Time Series Classification
Jan 15, 2026The World Wide Web thrives on intelligent services that rely on accurate time series classification, which has recently witnessed significant progress driven by advances in deep learning. However, existing studies face challenges in domain incremental learning. In this paper, we propose a lightweight and robust dual-causal disentanglement framework (DualCD) to enhance the robustness of models under domain incremental scenarios, which can be seamlessly integrated into time series classification models. Specifically, DualCD first introduces a temporal feature disentanglement module to capture class-causal features and spurious features. The causal features can offer sufficient predictive power to support the classifier in domain incremental learning settings. To accurately capture these causal features, we further design a dual-causal intervention mechanism to eliminate the influence of both intra-class and inter-class confounding features. This mechanism constructs variant samples by combining the current class's causal features with intra-class spurious features and with causal features from other classes. The causal intervention loss encourages the model to accurately predict the labels of these variant samples based solely on the causal features. Extensive experiments on multiple datasets and models demonstrate that DualCD effectively improves performance in domain incremental scenarios. We summarize our rich experiments into a comprehensive benchmark to facilitate research in domain incremental time series classification.
Augur: Modeling Covariate Causal Associations in Time Series via Large Language Models
Oct 09, 2025Large language models (LLM) have emerged as a promising avenue for time series forecasting, offering the potential to integrate multimodal data. However, existing LLM-based approaches face notable limitations-such as marginalized role in model architectures, reliance on coarse statistical text prompts, and lack of interpretability. In this work, we introduce Augur, a fully LLM driven time series forecasting framework that exploits LLM causal reasoning to discover and use directed causal associations among covariates. Augur uses a two stage teacher student architecture where a powerful teacher LLM infers a directed causal graph from time series using heuristic search together with pairwise causality testing. A lightweight student agent then refines the graph and fine tune on high confidence causal associations that are encoded as rich textual prompts to perform forecasting. This design improves predictive accuracy while yielding transparent, traceable reasoning about variable interactions. Extensive experiments on real-world datasets with 25 baselines demonstrate that Augur achieves competitive performance and robust zero-shot generalization.
QuiZSF: An efficient data-model interaction framework for zero-shot time-series forecasting
Aug 09, 2025Time series forecasting has become increasingly important to empower diverse applications with streaming data. Zero-shot time-series forecasting (ZSF), particularly valuable in data-scarce scenarios, such as domain transfer or forecasting under extreme conditions, is difficult for traditional models to deal with. While time series pre-trained models (TSPMs) have demonstrated strong performance in ZSF, they often lack mechanisms to dynamically incorporate external knowledge. Fortunately, emerging retrieval-augmented generation (RAG) offers a promising path for injecting such knowledge on demand, yet they are rarely integrated with TSPMs. To leverage the strengths of both worlds, we introduce RAG into TSPMs to enhance zero-shot time series forecasting. In this paper, we propose QuiZSF (Quick Zero-Shot Time Series Forecaster), a lightweight and modular framework that couples efficient retrieval with representation learning and model adaptation for ZSF. Specifically, we construct a hierarchical tree-structured ChronoRAG Base (CRB) for scalable time-series storage and domain-aware retrieval, introduce a Multi-grained Series Interaction Learner (MSIL) to extract fine- and coarse-grained relational features, and develop a dual-branch Model Cooperation Coherer (MCC) that aligns retrieved knowledge with two kinds of TSPMs: Non-LLM based and LLM based. Compared with contemporary baselines, QuiZSF, with Non-LLM based and LLM based TSPMs as base model, respectively, ranks Top1 in 75% and 87.5% of prediction settings, while maintaining high efficiency in memory and inference time.
Spatiotemporal Causal Decoupling Model for Air Quality Forecasting
May 26, 2025Due to the profound impact of air pollution on human health, livelihoods, and economic development, air quality forecasting is of paramount significance. Initially, we employ the causal graph method to scrutinize the constraints of existing research in comprehensively modeling the causal relationships between the air quality index (AQI) and meteorological features. In order to enhance prediction accuracy, we introduce a novel air quality forecasting model, AirCade, which incorporates a causal decoupling approach. AirCade leverages a spatiotemporal module in conjunction with knowledge embedding techniques to capture the internal dynamics of AQI. Subsequently, a causal decoupling module is proposed to disentangle synchronous causality from past AQI and meteorological features, followed by the dissemination of acquired knowledge to future time steps to enhance performance. Additionally, we introduce a causal intervention mechanism to explicitly represent the uncertainty of future meteorological features, thereby bolstering the model's robustness. Our evaluation of AirCade on an open-source air quality dataset demonstrates over 20\% relative improvement over state-of-the-art models.
A baseline for machine-learning-based hepatocellular carcinoma diagnosis using multi-modal clinical data
Jan 20, 2025The objective of this paper is to provide a baseline for performing multi-modal data classification on a novel open multimodal dataset of hepatocellular carcinoma (HCC), which includes both image data (contrast-enhanced CT and MRI images) and tabular data (the clinical laboratory test data as well as case report forms). TNM staging is the classification task. Features from the vectorized preprocessed tabular data and radiomics features from contrast-enhanced CT and MRI images are collected. Feature selection is performed based on mutual information. An XGBoost classifier predicts the TNM staging and it shows a prediction accuracy of $0.89 \pm 0.05$ and an AUC of $0.93 \pm 0.03$. The classifier shows that this high level of prediction accuracy can only be obtained by combining image and clinical laboratory data and therefore is a good example case where multi-model classification is mandatory to achieve accurate results.
FusionTransNet for Smart Urban Mobility: Spatiotemporal Traffic Forecasting Through Multimodal Network Integration
May 09, 2024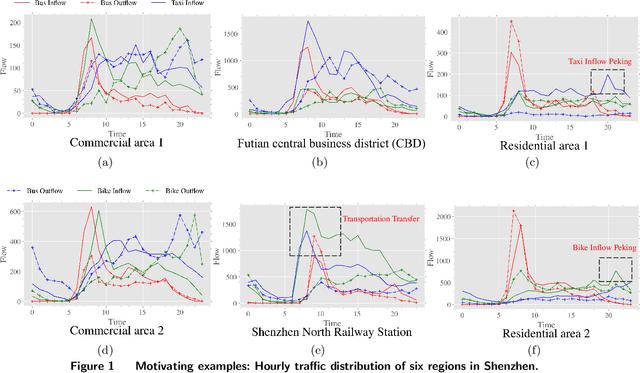
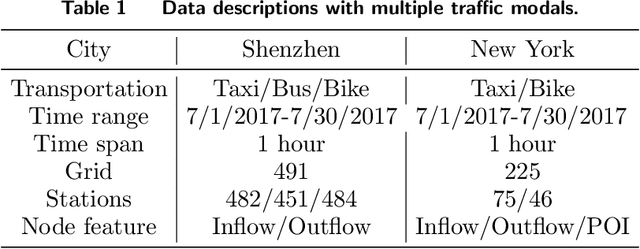

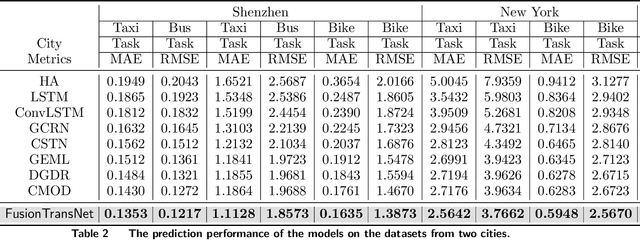
This study develops FusionTransNet, a framework designed for Origin-Destination (OD) flow predictions within smart and multimodal urban transportation systems. Urban transportation complexity arises from the spatiotemporal interactions among various traffic modes. Motivated by analyzing multimodal data from Shenzhen, a framework that can dissect complicated spatiotemporal interactions between these modes, from the microscopic local level to the macroscopic city-wide perspective, is essential. The framework contains three core components: the Intra-modal Learning Module, the Inter-modal Learning Module, and the Prediction Decoder. The Intra-modal Learning Module is designed to analyze spatial dependencies within individual transportation modes, facilitating a granular understanding of single-mode spatiotemporal dynamics. The Inter-modal Learning Module extends this analysis, integrating data across different modes to uncover cross-modal interdependencies, by breaking down the interactions at both local and global scales. Finally, the Prediction Decoder synthesizes insights from the preceding modules to generate accurate OD flow predictions, translating complex multimodal interactions into forecasts. Empirical evaluations conducted in metropolitan contexts, including Shenzhen and New York, demonstrate FusionTransNet's superior predictive accuracy compared to existing state-of-the-art methods. The implication of this study extends beyond urban transportation, as the method for transferring information across different spatiotemporal graphs at both local and global scales can be instrumental in other spatial systems, such as supply chain logistics and epidemics spreading.