 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceWukong: Benchmarking Deepfake Voice Detection
Sep 10, 2024
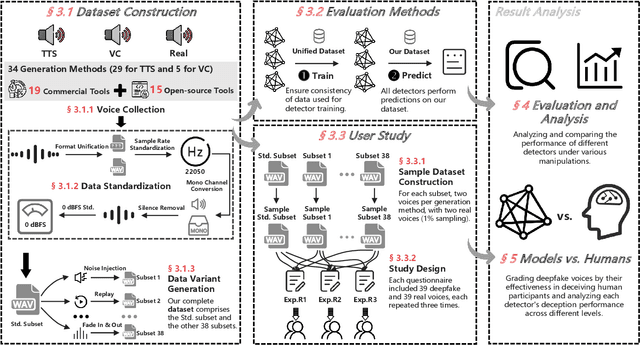
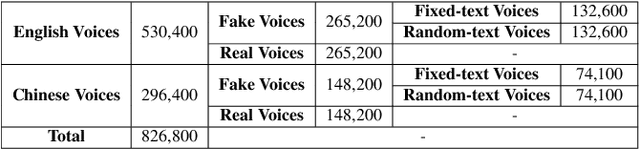
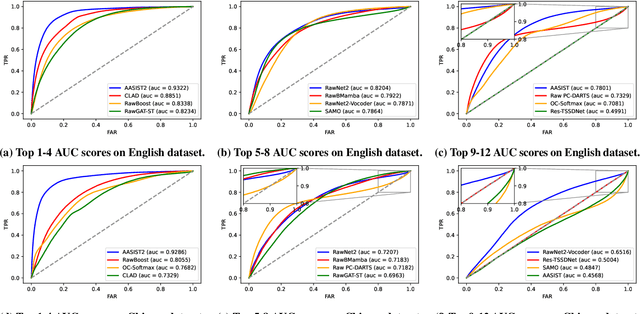
With the rapid advancement of technologies like text-to-speech (TTS) and voice conversion (VC), detecting deepfake voices has become increasingly crucial. However, both academia and industry lack a comprehensive and intuitive benchmark for evaluating detectors. Existing datasets are limited in language diversity and lack many manipulations encountered in real-world production environments. To fill this gap, we propose VoiceWukong, a benchmark designed to evaluate the performance of deepfake voice detectors. To build the dataset, we first collected deepfake voices generated by 19 advanced and widely recognized commercial tools and 15 open-source tools. We then created 38 data variants covering six types of manipulations, constructing the evaluation dataset for deepfake voice detection. VoiceWukong thus includes 265,200 English and 148,200 Chinese deepfake voice samples. Using VoiceWukong, we evaluated 12 state-of-the-art detectors. AASIST2 achieved the best equal error rate (EER) of 13.50%, while all others exceeded 20%. Our findings reveal that these detectors face significant challenges in real-world applications, with dramatically declining performance. In addition, we conducted a user study with more than 300 participants. The results are compared with the performance of the 12 detectors and a multimodel large language model (MLLM), i.e., Qwen2-Audio, where different detectors and humans exhibit varying identification capabilities for deepfake voices at different deception levels, while the LALM demonstrates no detection ability at all. Furthermore, we provide a leaderboard for deepfake voice detection, publicly available at {https://voicewukong.github.io}.
Potato: A Data-Oriented Programming 3D Simulator for Large-Scale Heterogeneous Swarm Robotics
Aug 24, 2023



Large-scale simulation with realistic nonlinear dynamic models is crucial for algorithms development for swarm robotics. However, existing platforms are mainly developed based on Object-Oriented Programming (OOP) and either use simple kinematic models to pursue a large number of simulating nodes or implement realistic dynamic models with limited simulating nodes. In this paper, we develop a simulator based on Data-Oriented Programming (DOP) that utilizes GPU parallel computing to achieve large-scale swarm robotic simulations. Specifically, we use a multi-process approach to simulate heterogeneous agents and leverage PyTorch with GPU to simulate homogeneous agents with a large number. We test our approach using a nonlinear quadrotor model and demonstrate that this DOP approach can maintain almost the same computational speed when quadrotors are less than 5,000. We also provide two examples to present the functionality of the platform.
Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation
Mar 22, 2022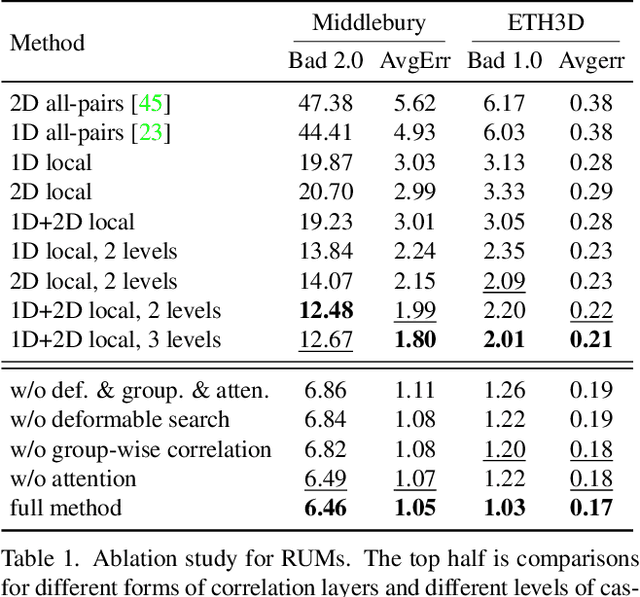
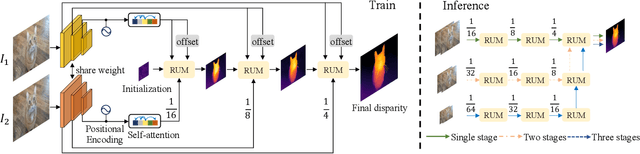
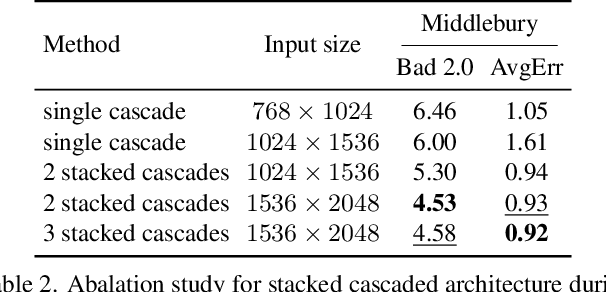
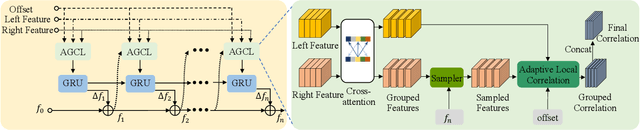
With the advent of convolutional neural networks, stereo matching algorithms have recently gained tremendous progress. However, it remains a great challenge to accurately extract disparities from real-world image pairs taken by consumer-level devices like smartphones, due to practical complicating factors such as thin structures, non-ideal rectification, camera module inconsistencies and various hard-case scenes. In this paper, we propose a set of innovative designs to tackle the problem of practical stereo matching: 1) to better recover fine depth details, we design a hierarchical network with recurrent refinement to update disparities in a coarse-to-fine manner, as well as a stacked cascaded architecture for inference; 2) we propose an adaptive group correlation layer to mitigate the impact of erroneous rectification; 3) we introduce a new synthetic dataset with special attention to difficult cases for better generalizing to real-world scenes. Our results not only rank 1st on both Middlebury and ETH3D benchmarks, outperforming existing state-of-the-art methods by a notable margin, but also exhibit high-quality details for real-life photos, which clearly demonstrates the efficacy of our contributions.